目标定位
- 定义:
在分类问题输出y的基础上增加物体位置的输出:$b_x,b_y,b_w,b_h$及中心坐标及宽高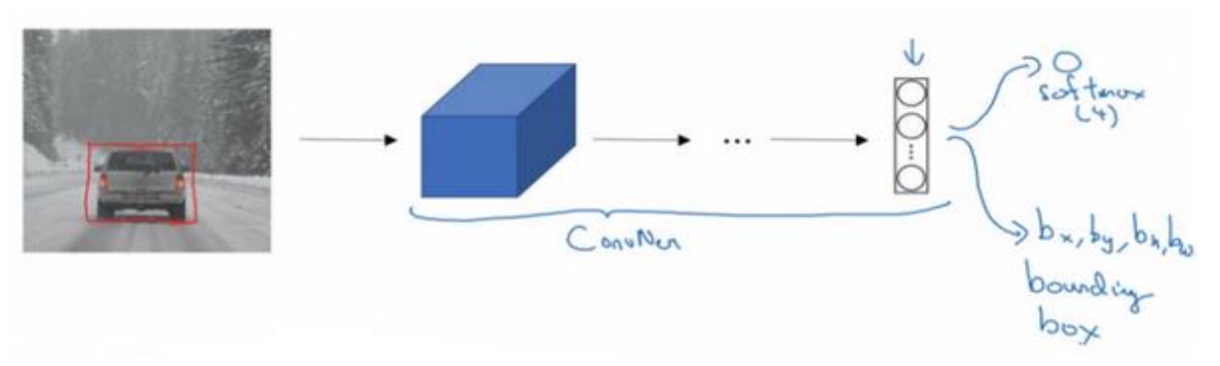
- Loss函数的定义:
输出为以y向量,采用平方误差的策略,$L(\hat y,y)=(\hat {y_1}-y_1)^2 + (\hat {y_2}-y_2)^2 + (\hat {y_3}-y_3)^2 + … +(\hat {y_8}-y_8)^2$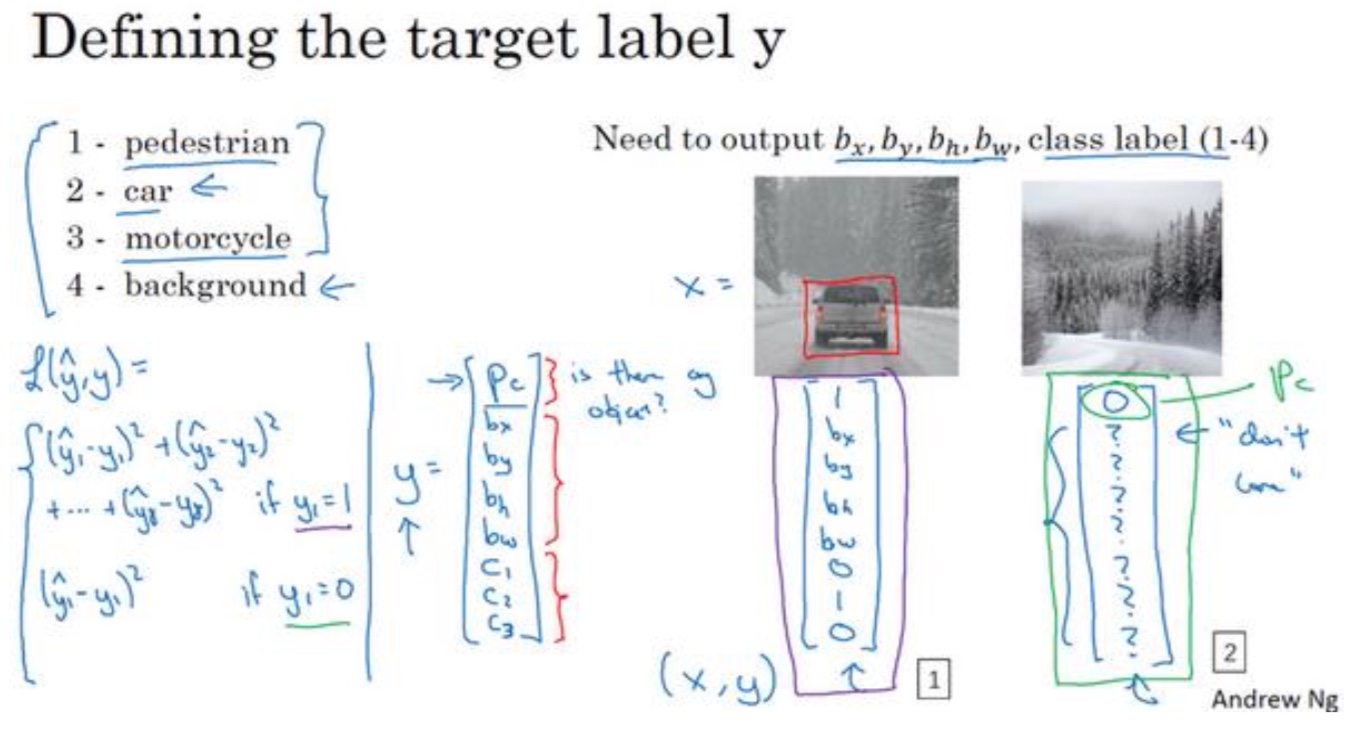
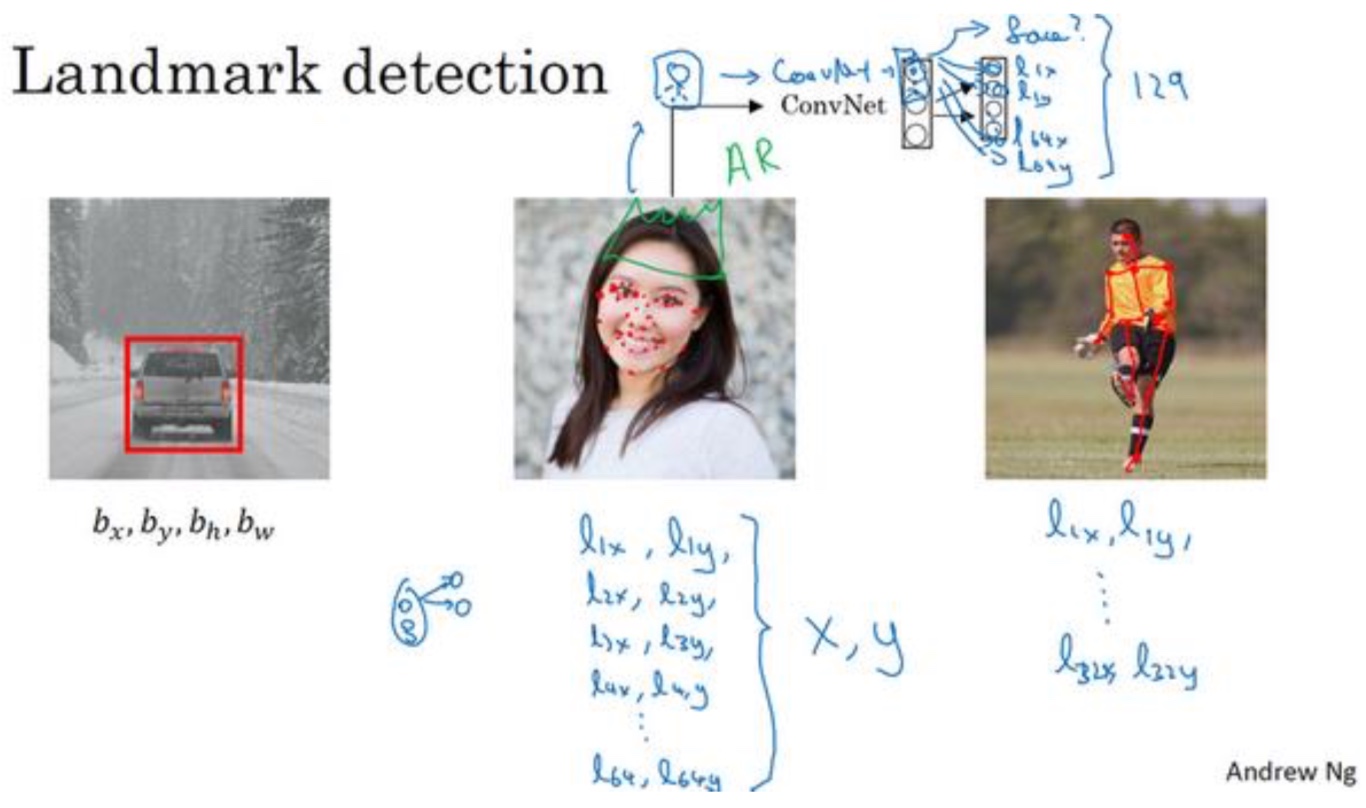
特征点检测(Landmark detection)
- 神经网络可以通过输出图片上的特征点的(x,y)坐标来实现对目标特征的识别,例如人脸检测或者snapchar上的头带皇冠的功能:
- 人脸检测:对人脸进行64个特征点的检测,总共输出129维的向量,$y_1$表示又没有人脸,然后是64个坐标($x_i,y_i$)
- Snapchat:也是通过检测头的上部特征点
- 或者是人的姿势,也是一些特征点
目标检测(Object detection)
- Sliding window detection
一般会获取三次不同大小的窗口,然后循环图片进行检测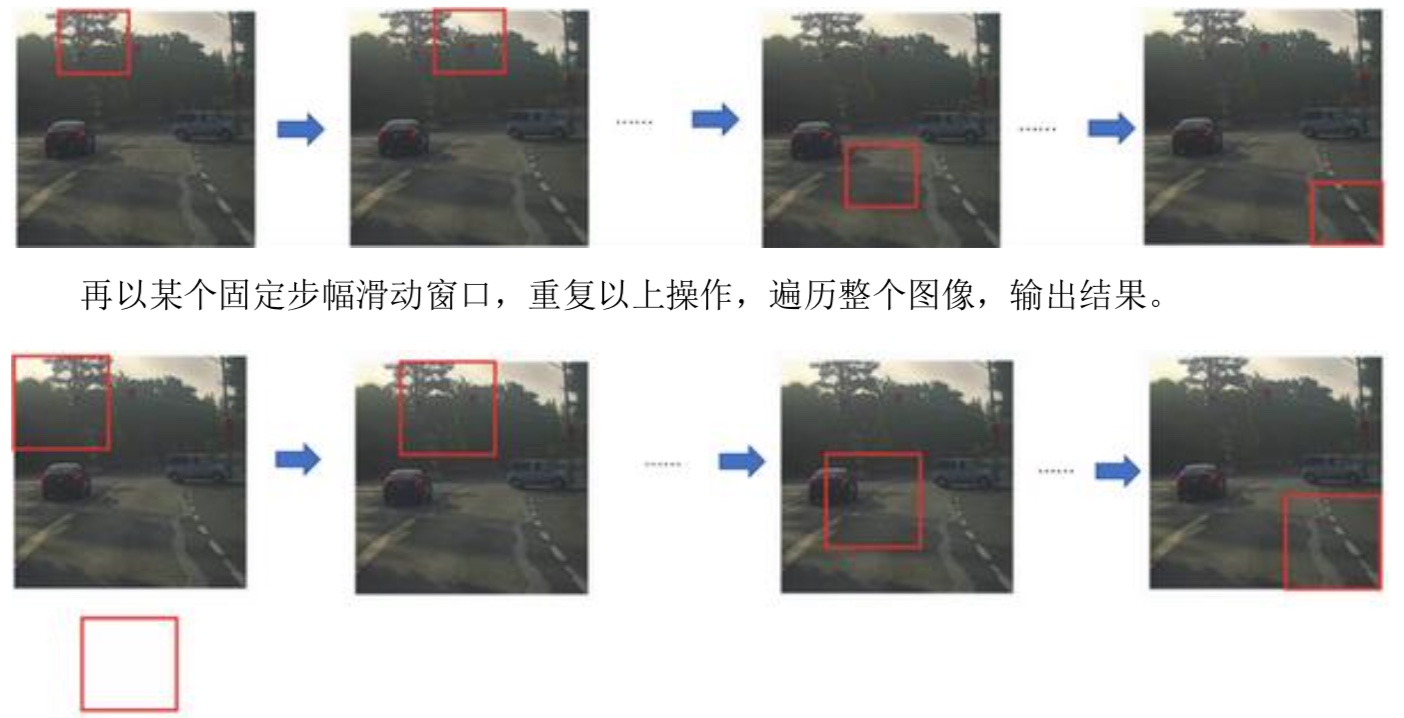
- 计算成本
计算成本比较大,步幅大一点能够缩小成本,但是效果不好。步幅小一点检测效果当然会很好,但是计算成本会很大
卷积的滑动窗口实现
- 需要将全连接进行卷积改造
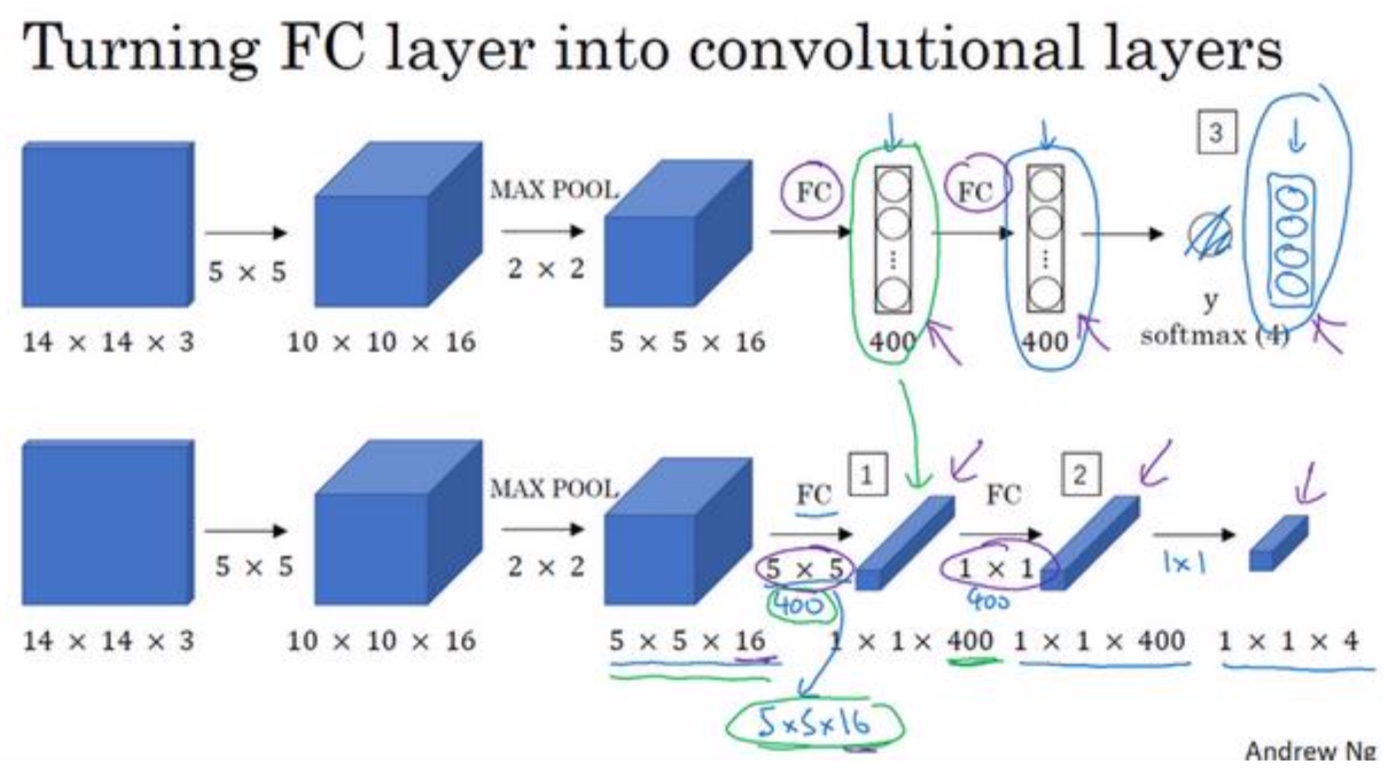
- 实现要点:
- 如果按照原始方法,进行四次切割,然后将14x14的图片给CNN,那边就是跑四次CNN,并且中间会有很多重复计算
- 所以用卷积进行替换,将16x16整张图进行卷积操作
- 最后输出的2x2x4网络,需要理解:每一个1x1x4的网络就是类比的原始方法切分后的图片的输出,所以这里会有2x2就是4种切分方式的输出(可以一步一步卷积过程来理解2x2为什么代表之前的四次切分)
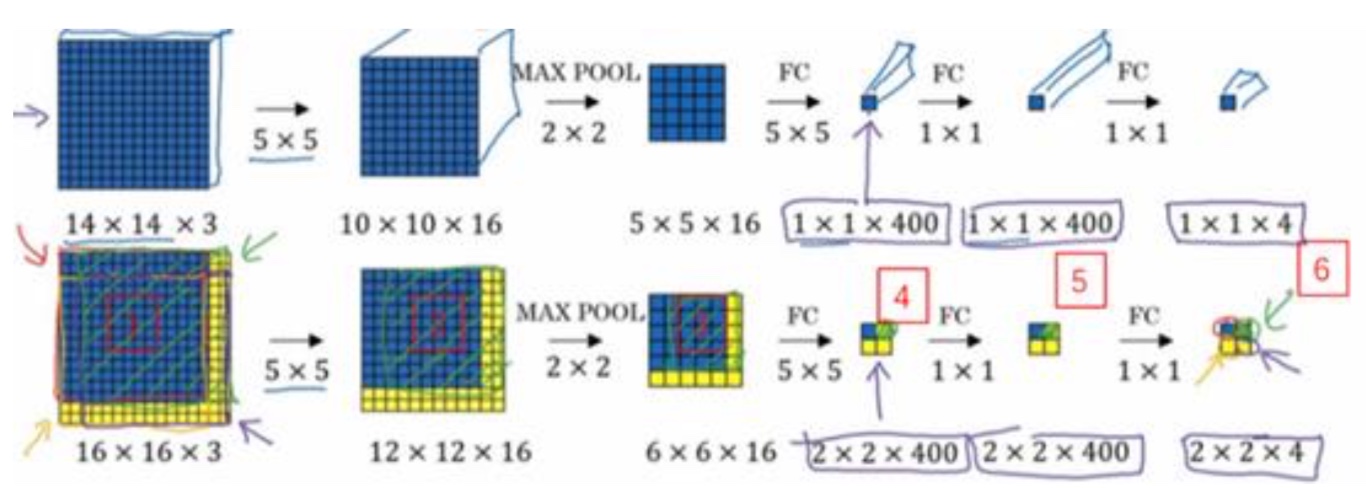
- 最后输出的2x2x4网络,需要理解:每一个1x1x4的网络就是类比的原始方法切分后的图片的输出,所以这里会有2x2就是4种切分方式的输出(可以一步一步卷积过程来理解2x2为什么代表之前的四次切分)
- 其他28x28举例:
最终是8x8x4 的输出,原始的表示切割了64次,每一次切割后输出都是4种分类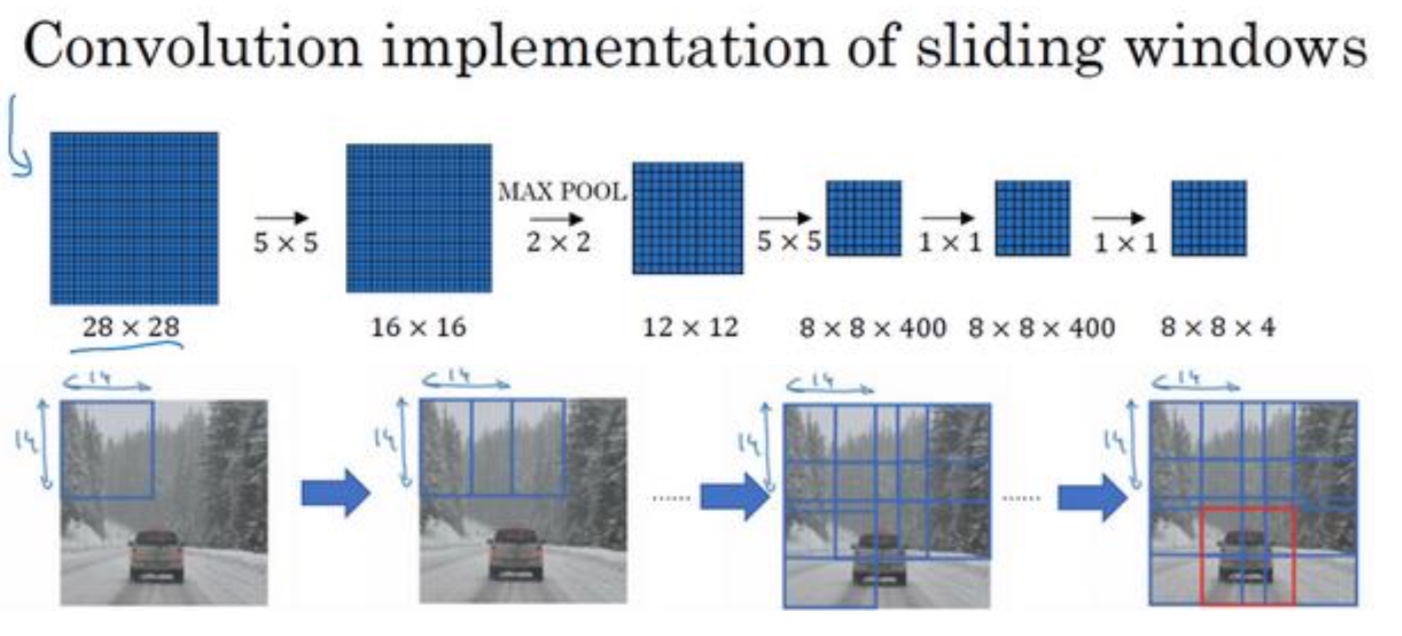
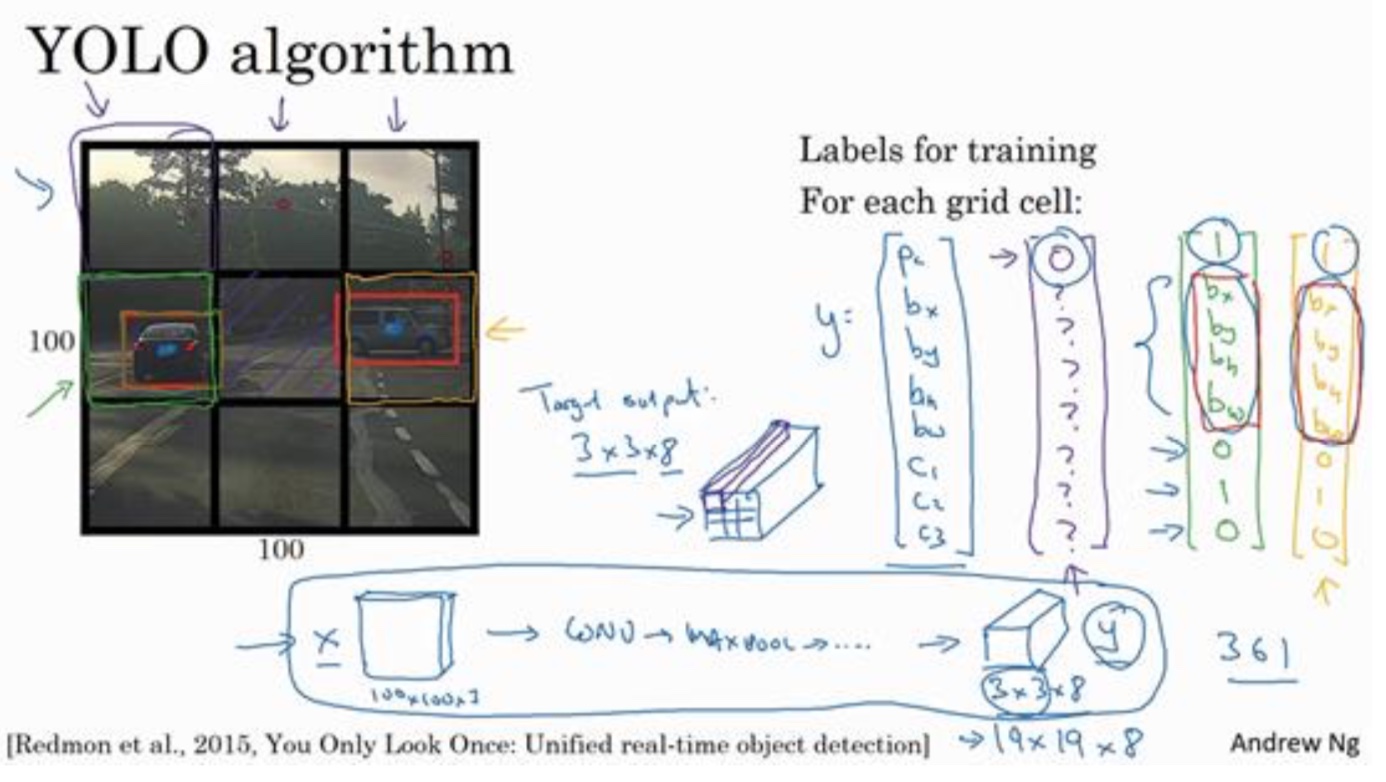
YOLO算法
- 背景:卷积滑动窗口也不能输出最精准的边界框
- 算法:
- 使用卷积滑动,所以效率比较高
- 将图片分为3x3,或者19x19,找到对象的中心点所属于的小窗口。然后计算出相对于小窗口的宽带和高度,其中宽带和高度可能会大于1
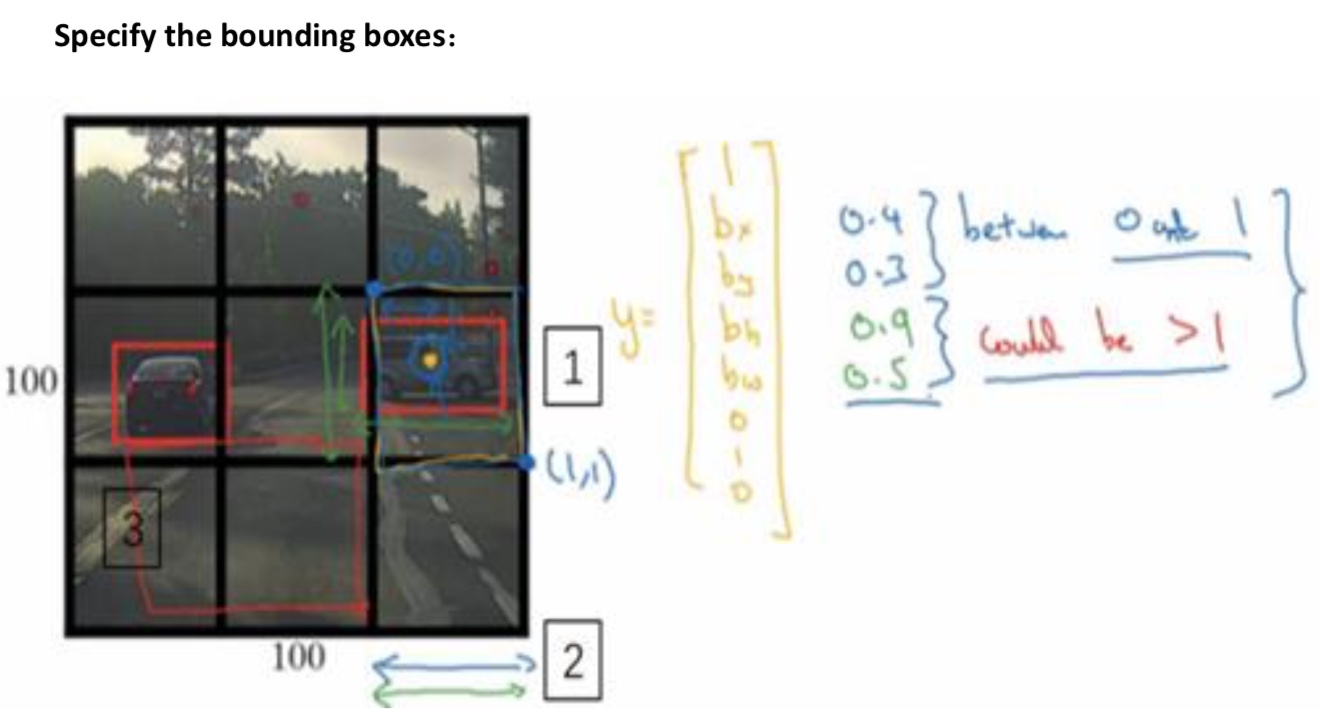
交并比
- 背景:如何判断对象检测算法运作良好呢
- 一般如果Iou大于0.5就算比较理想

非极大值抑制
背景:你的算法可能对同一个对象做出多次 检测,所以算法不是对某个对象检测出一次,而是检测出多次
比如下面这个图,多个小方框都会说自己内部可能有对象
定义:非最大值意味着你只输出概率最大的分类结果,但抑制很接 近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制
找到一个最大的$P_c$,非极大值抑制就会逐一审视 剩下的矩形,所有和这个最大的边框有很高交并比(IoU),高度重叠的其他边界框,那么这些输出 就会被抑制
算法步骤:
- 1.得到标记所有边框界,去掉这些边框界中$P_c$很小的,比如0.6,表示出现对象的概率很低
- 2.找到剩下的边框界中最大的$P_c$,然后去掉和$P_c$重合度最高,也就是IoU比较大的一些边框界
- 3.在剩下的边框界中重复2步骤,直到每一个边框界都被处理过
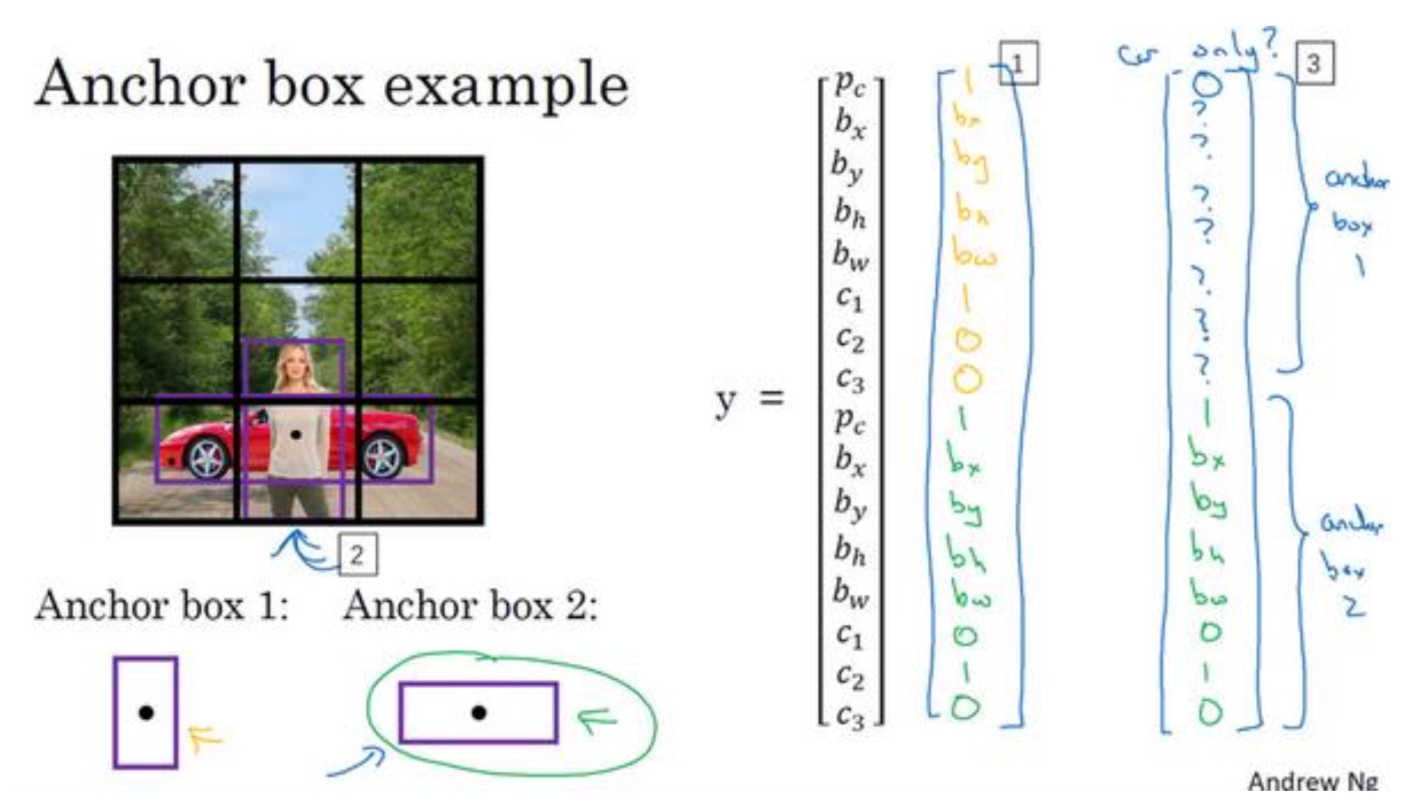
Anchor Boxes
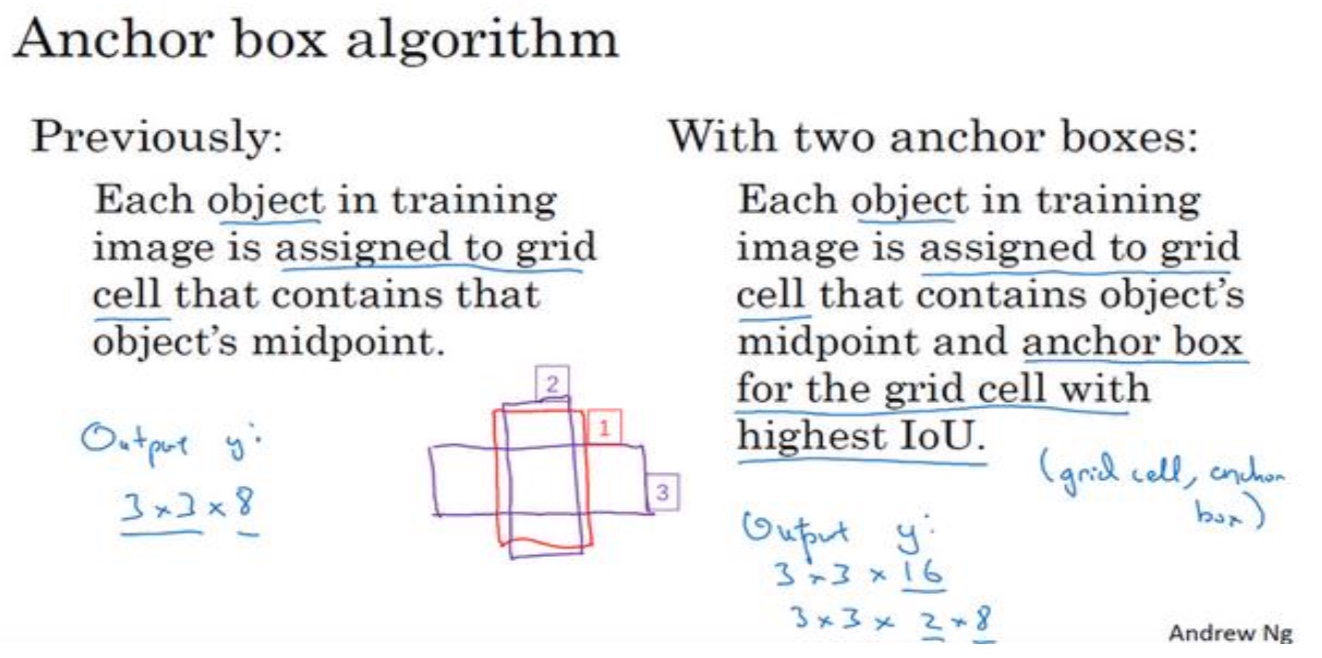
- 背景:对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,可以使用Anchor Boxes
- 思路:而 anchor box的思路是,这样子,预先定义两个不同形状的 anchor box,或者 anchor box 形状,你要做的是把预测结果和这两个 anchor box 关联起来
- 算法:输出为16维的向量,分别对应2个archor,然后找到和哪个archor的IoU最高,就和谁关联(每个archor会表示对应到哪个对象)
YOLO算法(集成)
- Train
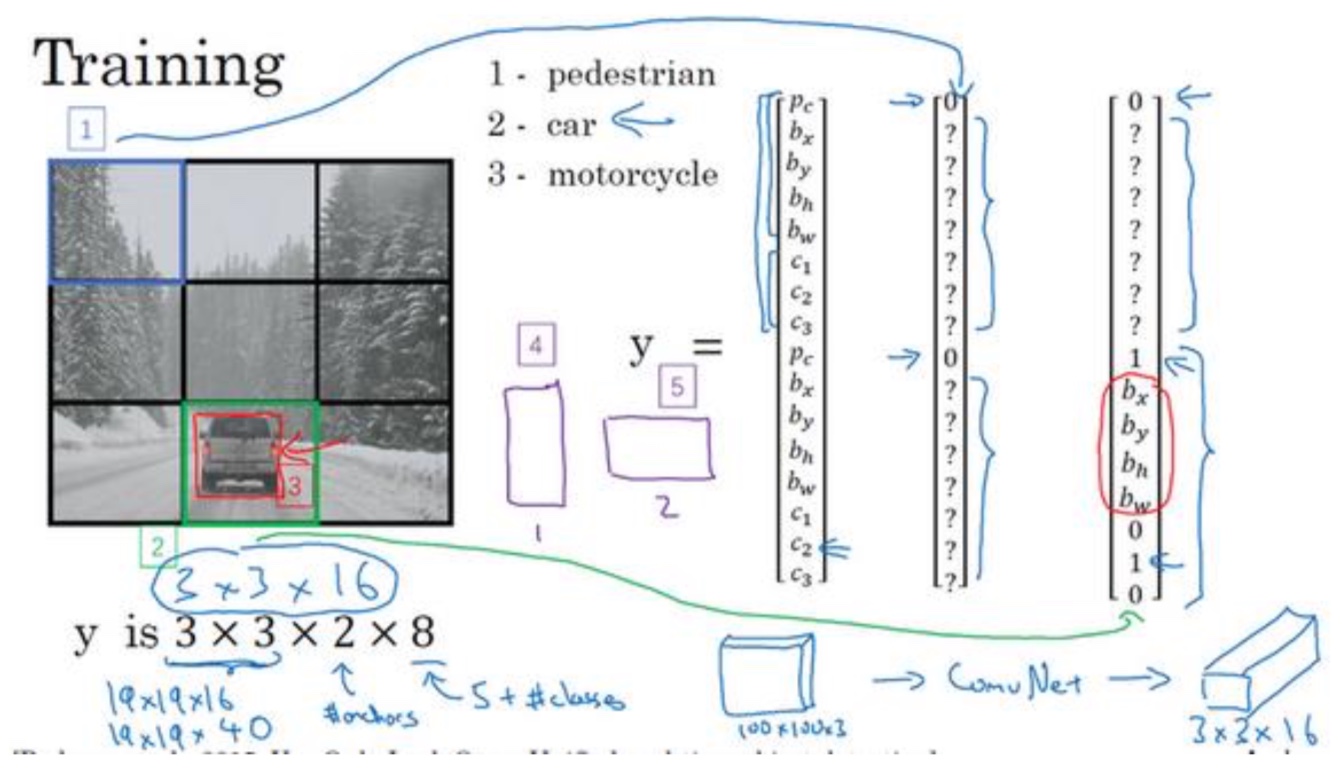
- Prediction
方框1得到右边3的输出,方框2得到右边4的输出,最后得到了每个grid(3x3)都得到了一个16维的向量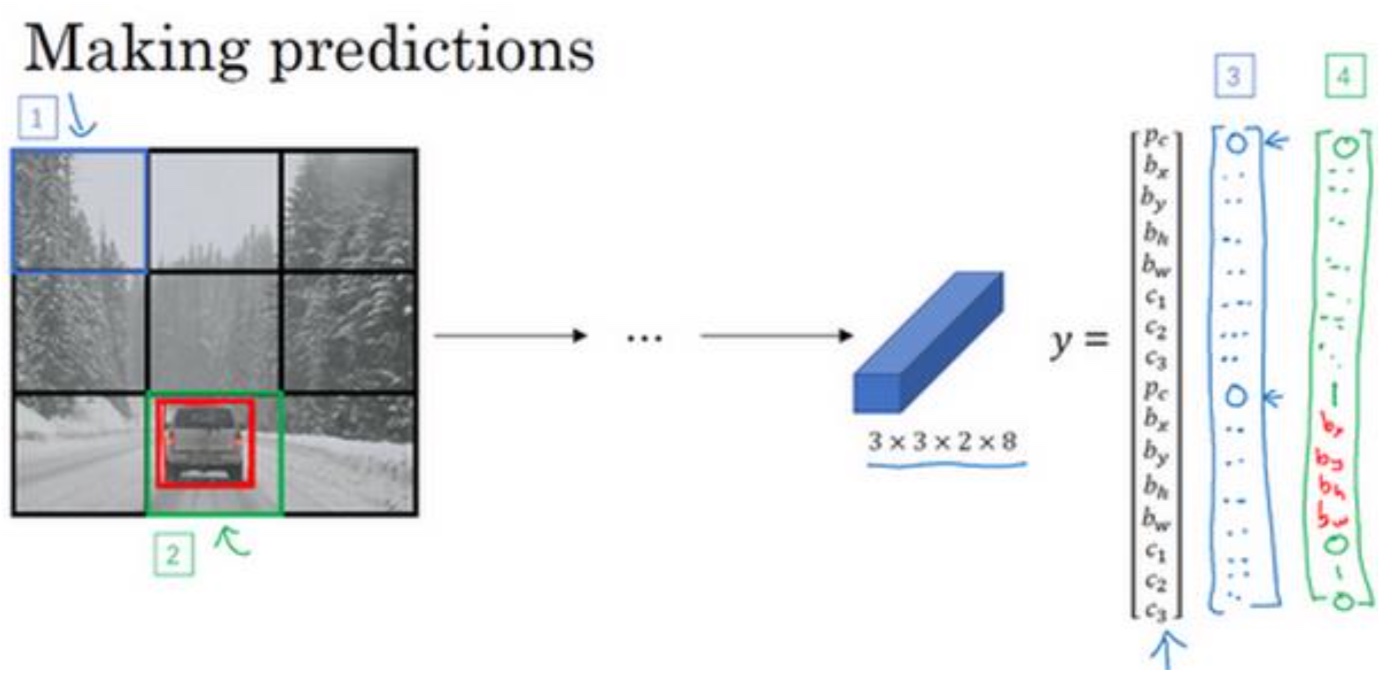
- Non-max supressed output
- 现在得到了每个grid(3x3)都得到了一个16维的向量,先去掉$P_c$比较低的网格,因为这基本代表无对象(下图1->下图2过程)
- 对剩下的网格,对每一种类别都使用Non-max supressed方法来确定每个网格对类别的预测
- 例如:如果你有三个对象检测类别,你希望检测行人,汽车和摩托车,那么你要做的是, 对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,用非极大值抑制来 处理行人类别,用非极大值抑制处理车子类别,然后对摩托车类别进行非极大值抑制,运行 三次来得到最终的预测结果。所以算法的输出最好能够检测出图像里所有的车子,还有所有 的行人(编号 3 所示)
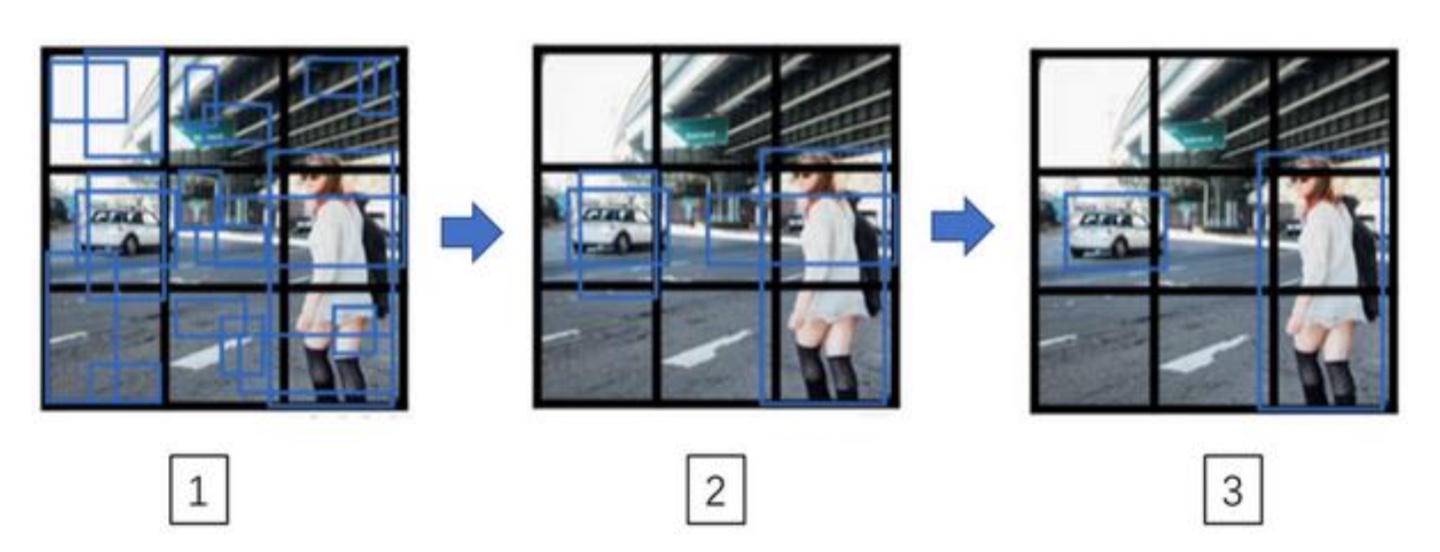
- 对于每个类别单独运行非极大值抑制

- 例如:如果你有三个对象检测类别,你希望检测行人,汽车和摩托车,那么你要做的是, 对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,用非极大值抑制来 处理行人类别,用非极大值抑制处理车子类别,然后对摩托车类别进行非极大值抑制,运行 三次来得到最终的预测结果。所以算法的输出最好能够检测出图像里所有的车子,还有所有 的行人(编号 3 所示)
候选区域
- 背景:CNN会对每个区域都进行计算,是它其中一个缺点,它在显然没有任何对象的区域浪费时间
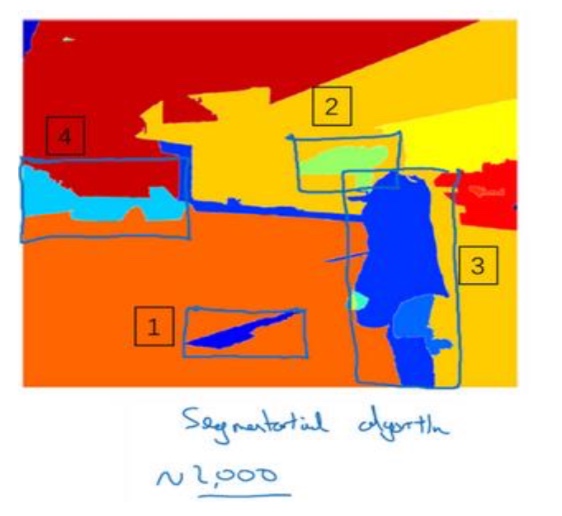
- R-CNN:带区域的卷积网络,或者说带区域的 CNN。 这个算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的,不对每个区域进行计算
- 基本的 R-CNN 算法是使用某种算法求出候选区域, 然后对每个候选区域运行一下分类器,每个区域会输出一个标签,有没有车子?有没有行人?有没有摩托车?并输出一个边界框,这样你就能在确实存在对象的区域得到一个精确的边界框。R-CNN 算法不会直接信任输入的边界框
改进算法
- Fast R-CNN
最初的算法是逐一对区域分类的,所以 Fast R-CNN用的是滑动窗法的一个卷积实现,和之前学习的”卷积的滑动窗口实现”类似 - Faster R-CNN
- 使用的是卷积神经网络,而不是更传统的分割算法来获得候选区域色块,来解决得到候选区域的聚类步骤仍然非常缓慢
- 吴恩达老师认为:我觉得候选区域是一个有趣的想法,但这个方法需要两步,首先得到候选区域,然后再分类,相比之下,能够一步做完,类似于YOLO或者你只看一次(You only look once)这个算法,在我看来,是长远而言更有希望的方向,我认为大多数 Faster R-CNN 的算法实现还是比 YOLO 算法慢很多
