习题代码:Machine-Translation
习题代码:Trigger-word-detection
序列结构的各种序列
seq2seq
分为编码网络的解码网络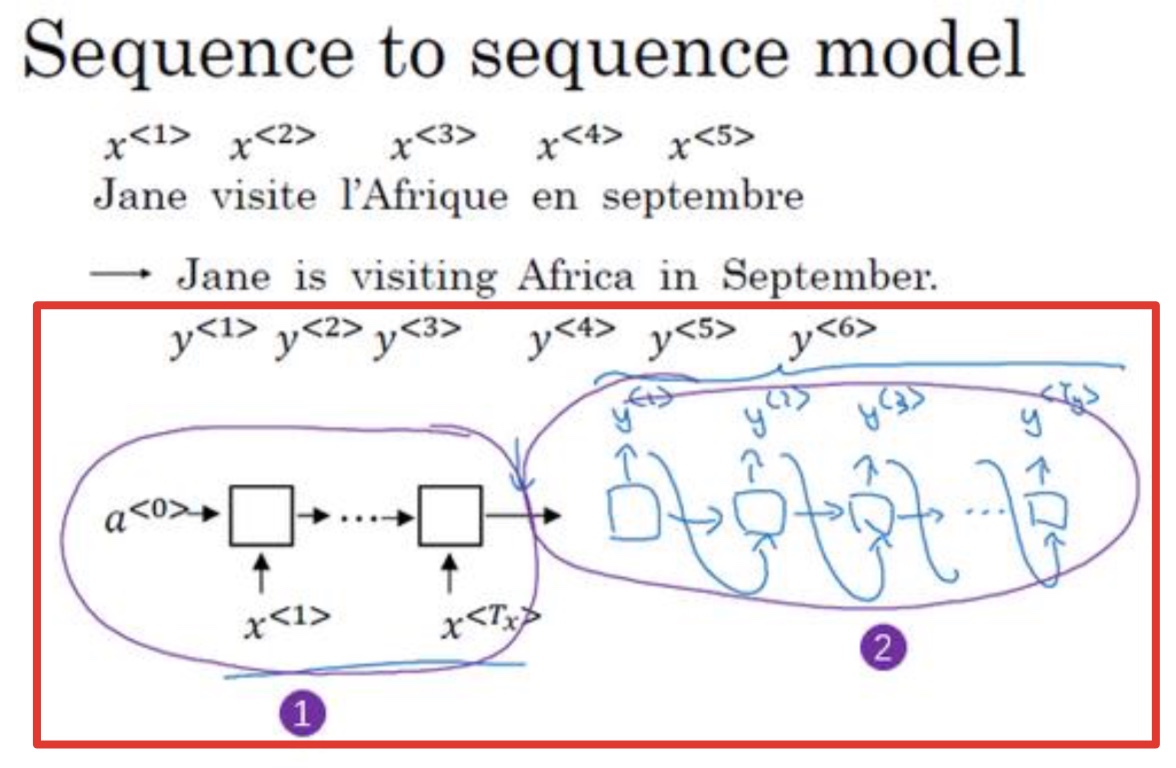
应用场景
- 机器翻译,比如英文和法文的互相翻译
- Image-to-seq
例子中使用的AlexNet网络,将最后的softmax输出替换为RNN网络,输出为一个序列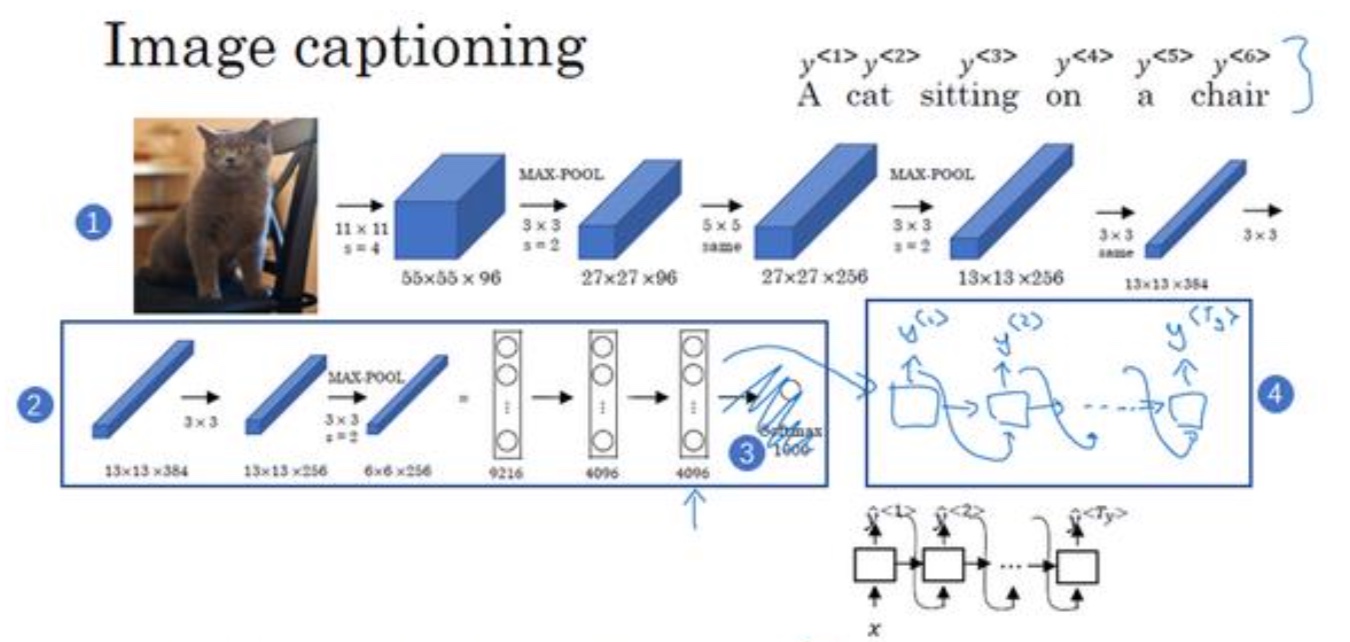
选择最可能的句子
- 语言模型和翻译模型比较
- 语言模型总是以零向量开始$(P(y^{< 1 >},y^{< 2 >},y^{< 3 >}…y^{< n >}))$
- 而翻译模型输入是法语的encoder,可以理解为条件模型:$P(y^{< 1 >},y^{< 2 >},y^{< 3 >}…y^{< n >}|x^{< 1 >},x^{< 2 >},x^{< 3 >}…x^{< n >})$
- 所以一个是随机输出seq,另一个是需要概率最大的seq
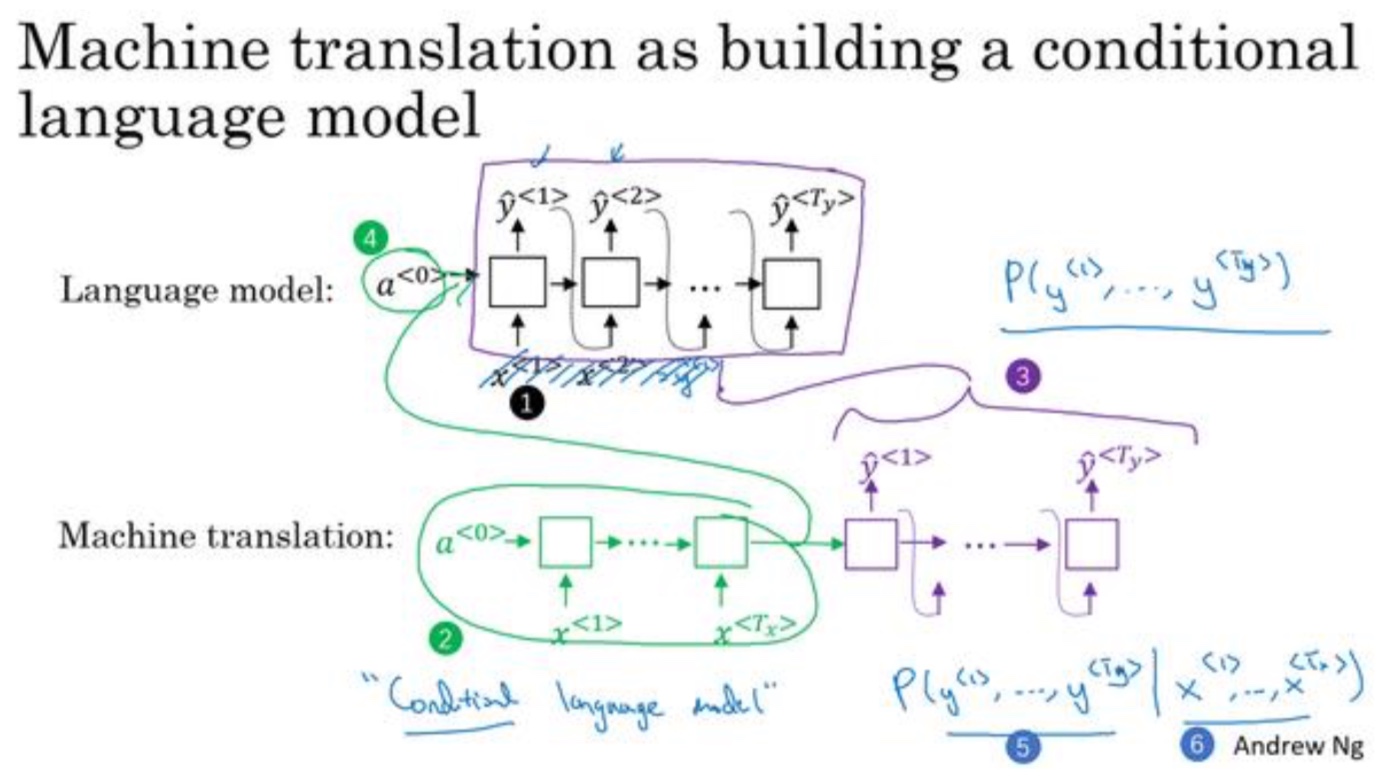
- 如何保证翻译模型中的条件概率最大
- 贪心算法:没一个输出都保证当前一个term($y^{< i >}$)概率最大,但是并不能保证整个序列概率最大,所以一次挑选一个词并不是最佳的选择
- 穷举法:将所有句子进行穷举测试,但由单词生成的句子量太大,无法穷举
- 集束算法
- 语言模型和翻译模型比较
集束算法(Beam Search)
集束算法
- 贪婪算法只会挑出最可能的那一个单词,然后继续。而集束搜索则会考虑多个选择,选择数量就是集束宽(Beam width)
- 第一步:
需要 输入法语句子到编码网络,然后会解码这个网络,这个 softmax 层(上图编号 3 所示)会输 出 10,000 个概率值,得到这 10,000 个输出的概率值,取前三个存起来 - 第二步:
- 选择第一步中的一个词$P(y^{<2>}|x, y^{<1>})$如下图3,输入为第一步的输出和x
- 不仅仅 是第二个单词有最大的概率,而是第一个、第二个单词对有最大的概率
- $P(y^{<1>},y^{<2>}|x)=P(y^{<1>}|x)P(y^{<2>}|x, y^{<1>})$
- 后面的步骤也是模仿第二步进行计算
- 重复第二步,选择第一步中的其他词进行计算
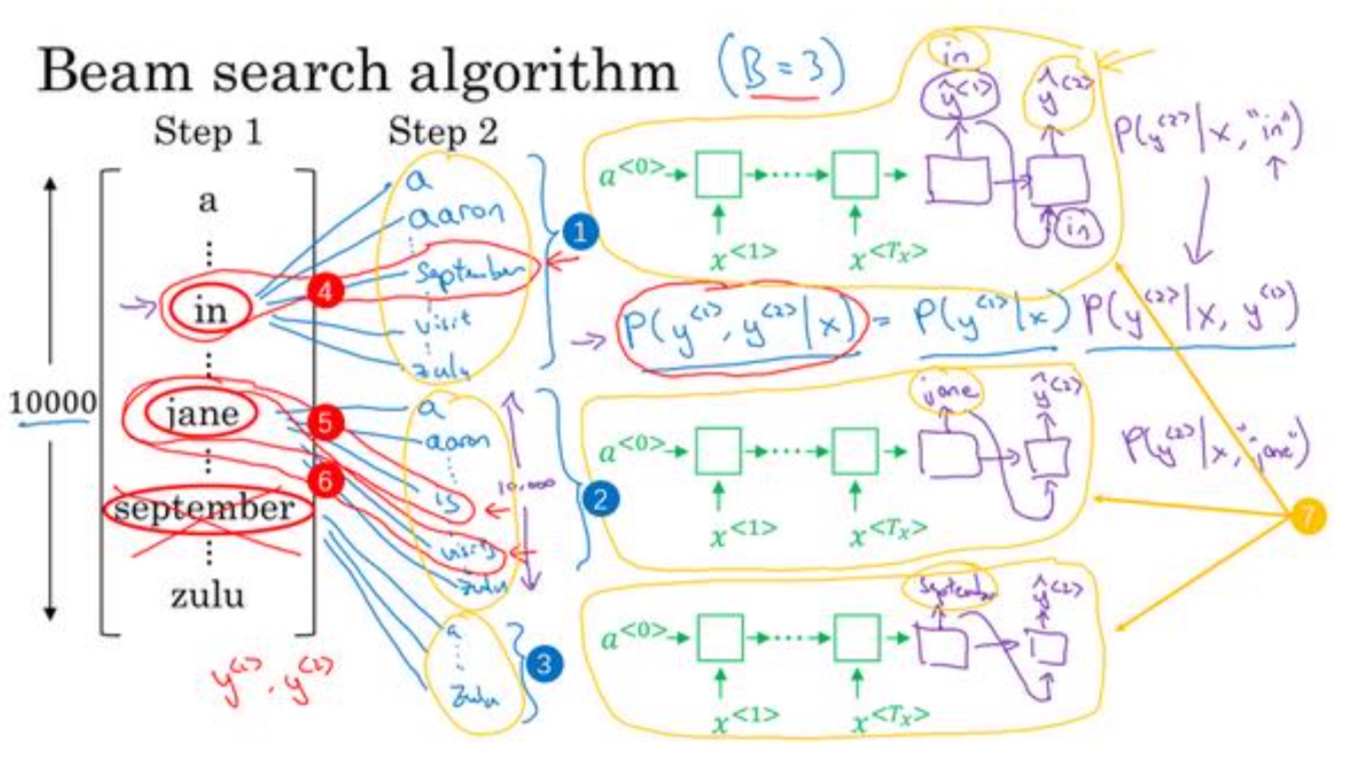
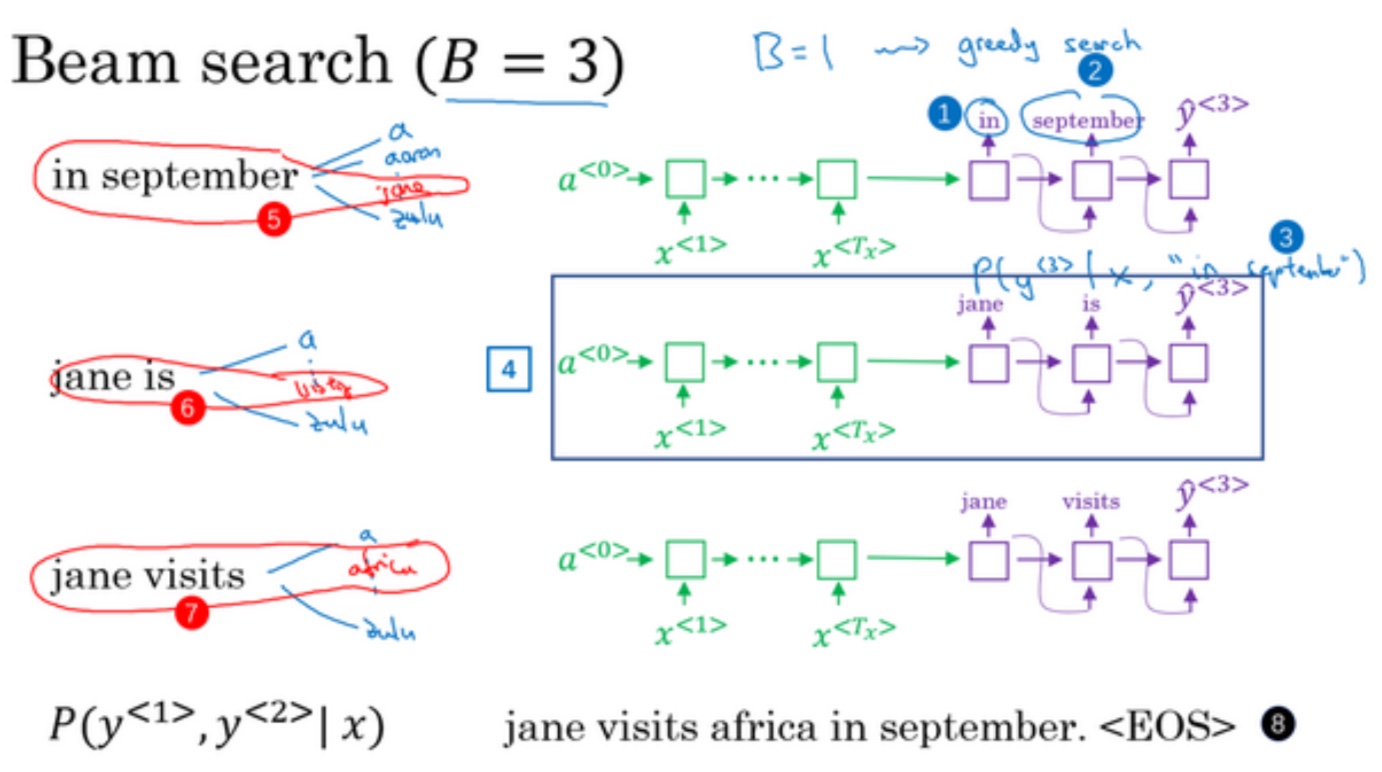
- 可以看见,如果集束宽为1,那么其实就是贪心算法
改进集束搜索
问题1:$P(y^{<1>}|x)P(y^{<2>}|x, y^{<1>})$…..由于每一步概率值都小于0,所以比容易造成数值下溢,也就是导致电脑的浮点表示不能精确的存储
- 解决方案:
我们总是记录概率的对数和,而不是概率的乘积,就用到了对数函数乘积的性质
- 解决方案:
问题2:由于每一项乘积都小于1,并且目标函数是最大概率的输出,所以一般会偏向于比较短的句子,这样乘积项就比较少
- 解决方案:
通过除以翻译结果的单词数量。这样就是取每个单词的概率对数值的平均了,这样很明显地 减少了对输出长的结果的惩罚
- 解决方案:
更柔和的方法:并不直接除以单词数,而是会乘上一个超参数a,比如a=0.7,如果a=1那么就相当于完全用长度来做归一化
集束宽选择
集束宽越大效果当然越好,但是计算也越复杂。在产品中,经常可以看到把束宽设到 10
集束搜索误差分析
Bleu得分
- 背景:比如机器翻译会得到很多都不错的答案,那么如何选择呢?Bleu得分算法,就是解决这个问题,它做的是;给定一个机器生成的翻译,能够自动地计算一个分数来衡量好坏
注意力模型
- 背景:从Bleu评分可以看出,长句的效果比较差
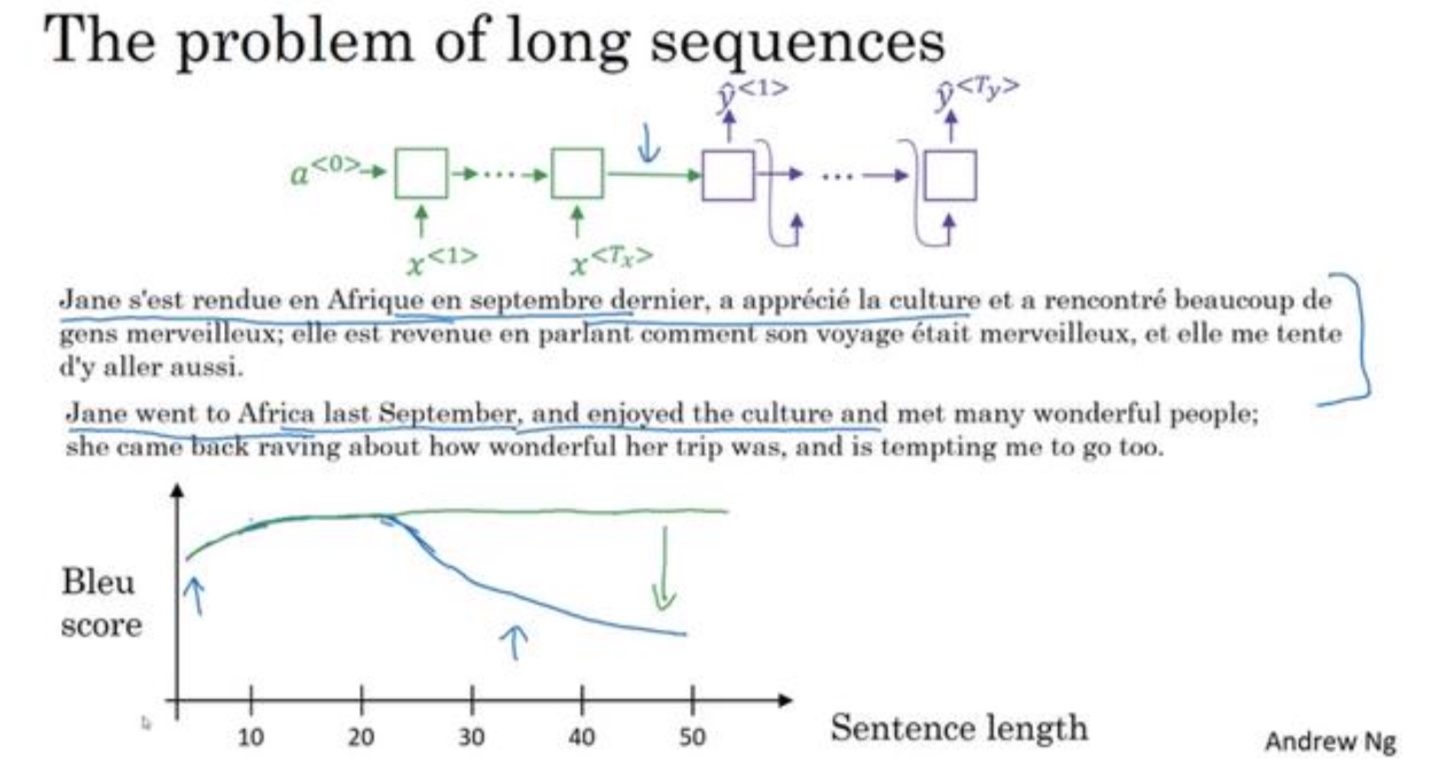
- 原理:模仿人工翻译,不会一次性把整个文章都读完再翻译,会读一部分内容,翻译一部分
- 下层的双向LSTM就是先跑所有的法语单词,然后形成context,看具体时间步的注意力需要多少前后关注做准备
- 理解:在计算当前时间步的时候,会花多少精力去关注多少当前词附近的词语
- 这些是注意力权重,即$a^{<t,t’>}$告诉你,当你尝试生成第𝑡个英文词,它应该花多少注意力在第𝑡个法语词上面。当生成一个 特定的英文词时,这允许它在每个时间步去看周围词距内的法语词要花多少注意力
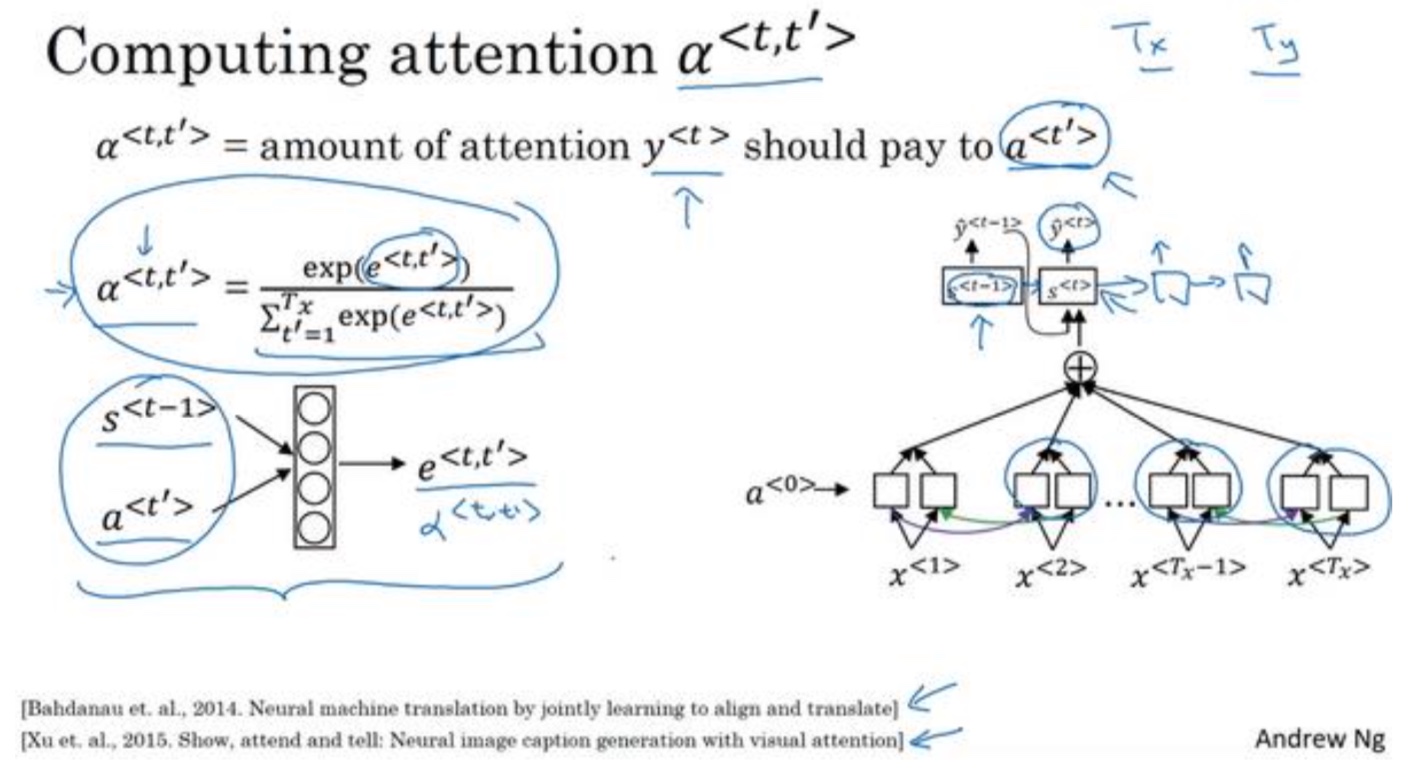
- 这些是注意力权重,即$a^{<t,t’>}$告诉你,当你尝试生成第𝑡个英文词,它应该花多少注意力在第𝑡个法语词上面。当生成一个 特定的英文词时,这允许它在每个时间步去看周围词距内的法语词要花多少注意力
编程练习:
- 将人工理解(Tuesday 09 Oct 1993)的日期翻译为机器理解的日期(1993-10-09)
- 这里前一个时间步的输出不用喂给后一个输入,并不像前面练习的恐龙名字一样,前后两个单词是有关联的
- 在训练过程中,每一个时间步的注意力长度是不一样的
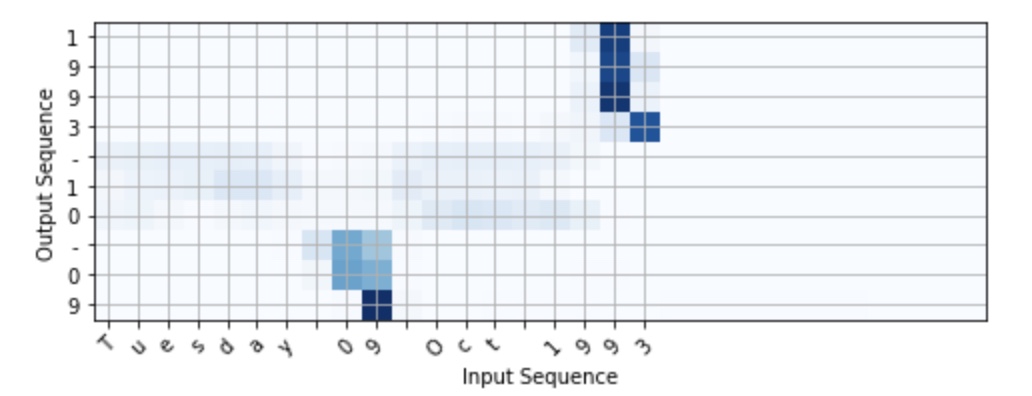
model:
总体分为2步,1:右边,one “Attention”如何计算,2:左边,整体的attention模型
In this part, you will implement the attention mechanism presented in the lecture videos. Here is a figure to remind you how the model works. The diagram on the left shows the attention model. The diagram on the right shows what one “Attention” step does to calculate the attention variables $\alpha^{\langle t, t’ \rangle}$, which are used to compute the context variable $context^{\langle t \rangle}$ for each timestep in the output ($t=1, \ldots, T_y$).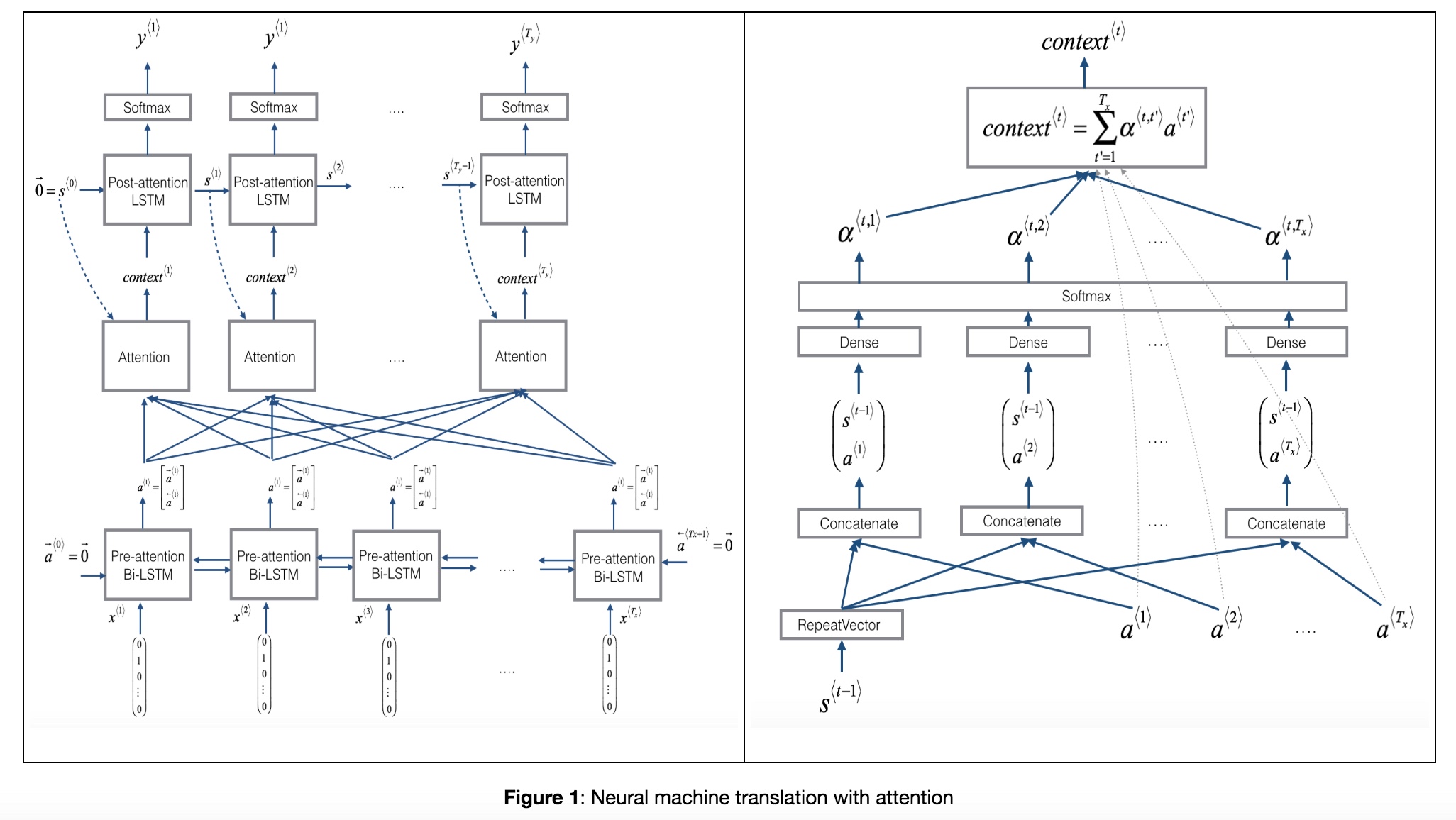
Here are some properties of the model that you may notice:
模型分两个LSTM层,下面一个双向LSTM根据前向后向计算的激活值a,然后匹配上各个时间步的注意力的长度,产出context,第二层LSTM是用context和前一个时间步的输出$S^{< t-1 >}$输出最终值
There are two separate LSTMs in this model (see diagram on the left). Because the one at the bottom of the picture is a Bi-directional LSTM and comes before the attention mechanism, we will call it pre-attention Bi-LSTM. The LSTM at the top of the diagram comes after the attention mechanism, so we will call it the post-attention LSTM. The pre-attention Bi-LSTM goes through $T_x$ time steps; the post-attention LSTM goes through $T_y$ time steps.The post-attention LSTM passes $s^{\langle t \rangle}, c^{\langle t \rangle}$ from one time step to the next. In the lecture videos, we were using only a basic RNN for the post-activation sequence model, so the state captured by the RNN output activations $s^{\langle t\rangle}$. But since we are using an LSTM here, the LSTM has both the output activation $s^{\langle t\rangle}$ and the hidden cell state $c^{\langle t\rangle}$. However, unlike previous text generation examples (such as Dinosaurus in week 1), in this model the post-activation LSTM at time $t$ does will not take the specific generated $y^{\langle t-1 \rangle}$ as input; it only takes $s^{\langle t\rangle}$ and $c^{\langle t\rangle}$ as input. We have designed the model this way, because (unlike language generation where adjacent characters are highly correlated) there isn’t as strong a dependency between the previous character and the next character in a YYYY-MM-DD date.
We use $a^{\langle t \rangle} = [\overrightarrow{a}^{\langle t \rangle}; \overleftarrow{a}^{\langle t \rangle}]$ to represent the concatenation of the activations of both the forward-direction and backward-directions of the pre-attention Bi-LSTM.
The diagram on the right uses a
RepeatVectornode to copy $s^{\langle t-1 \rangle}$’s value $T_x$ times, and thenConcatenationto concatenate $s^{\langle t-1 \rangle}$ and $a^{\langle t \rangle}$ to compute $e^{\langle t, t’}$, which is then passed through a softmax to compute $\alpha^{\langle t, t’ \rangle}$. We’ll explain how to useRepeatVectorandConcatenationin Keras below.
语音模型
- CTC cost
- 背景:很多时候语音输入比输出会多很多,如何在RNN中相同输入输出的模型中使用呢?
- CTC 损失函数的一个基本规则是 将空白符之间的重复的字符折叠起来,再说清楚一些,我这里用下划线来表示这个特殊的空 白符(a special blank character),这样就可以让输出和输入相同数量了
触发字检测
- 生谱图特征得到特征向量$x^{<1>},x^{<2>,…}$
- 训练集如何标注:检测到关键词的以后就标注为1,未检测到就标注为0
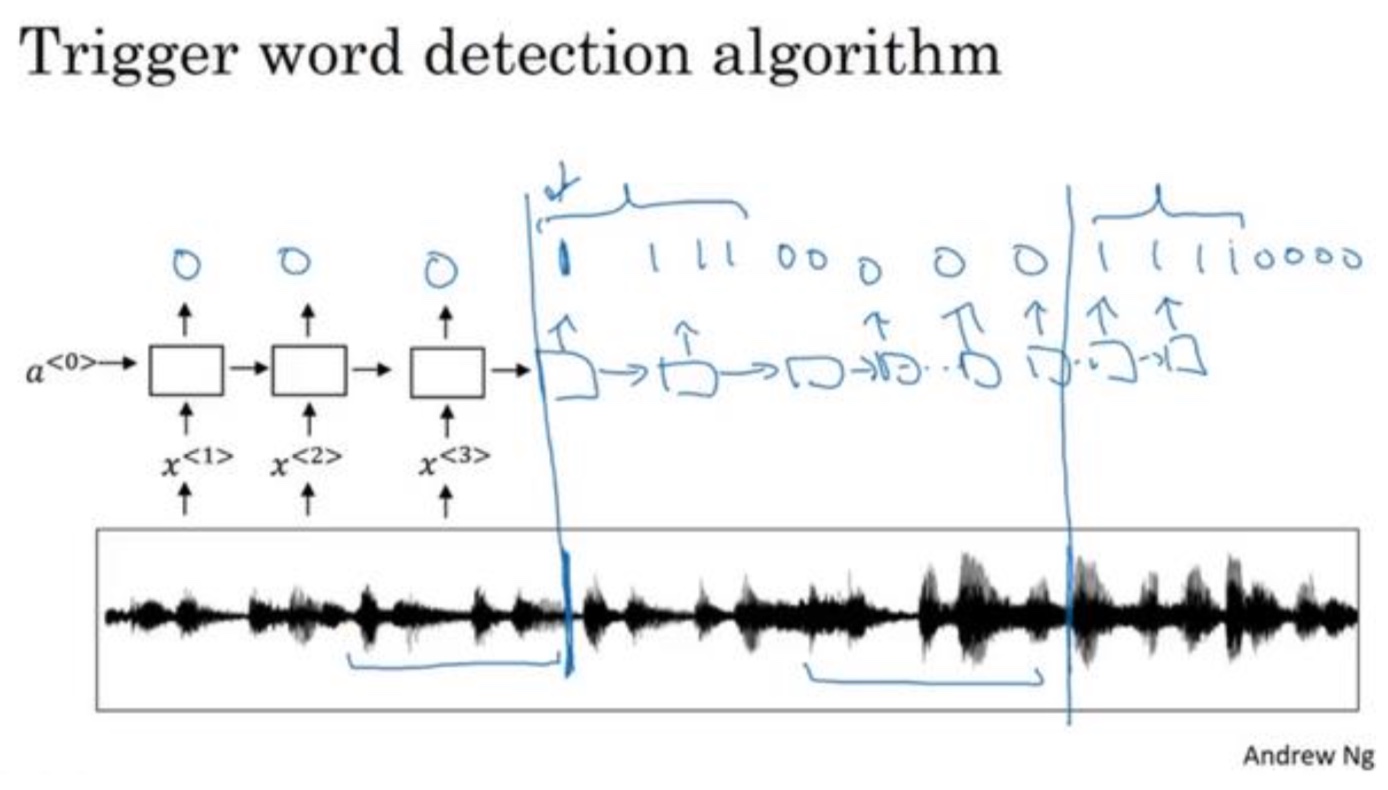
- 问题:这样导致0和1的数量很不平衡,简单的处理方式:比 起只在一个时间步上去输出 1,其实你可以在输出变回 0 之前,多次输出 1,或说在固定的 一段时间内输出多个 1
- 练习题:
- 网络架构
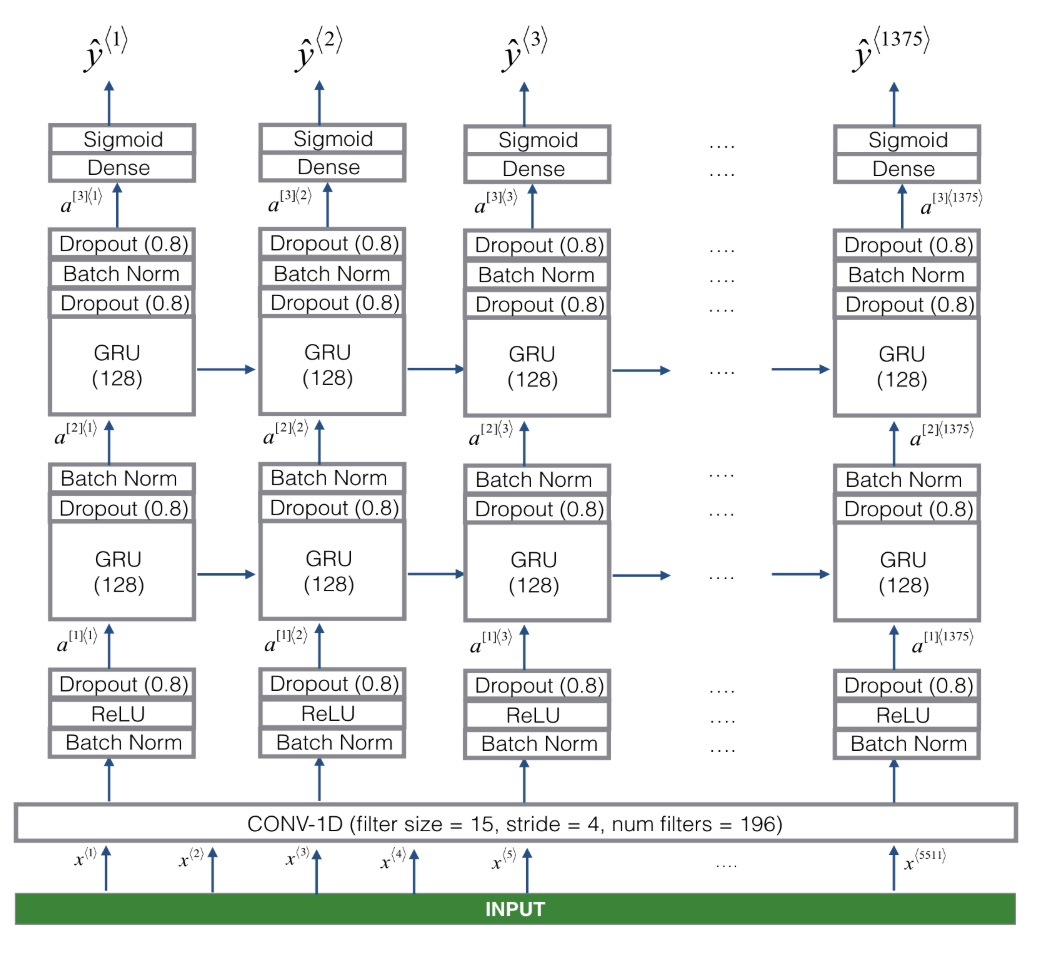
- 首先通过生谱图将声音转换为特征向量
- 然后开始使用了CNN,使5511时间步减小到1375,这个在RNN中大量减小了复杂大
- 然后用两层RNN,进行0,1预测输出,注意并没有使用双向RNN,因为语音说完就要快速给出结果,并不是等10s说完后才给
- Here’s what you should remember:
- Data synthesis is an effective way to create a large training set for speech problems, specifically trigger word detection.
- Using a spectrogram and optionally a 1D conv layer is a common pre-processing step prior to passing audio data to an RNN, GRU or LSTM.
- An end-to-end deep learning approach can be used to built a very effective trigger word detection system.
- 网络架构