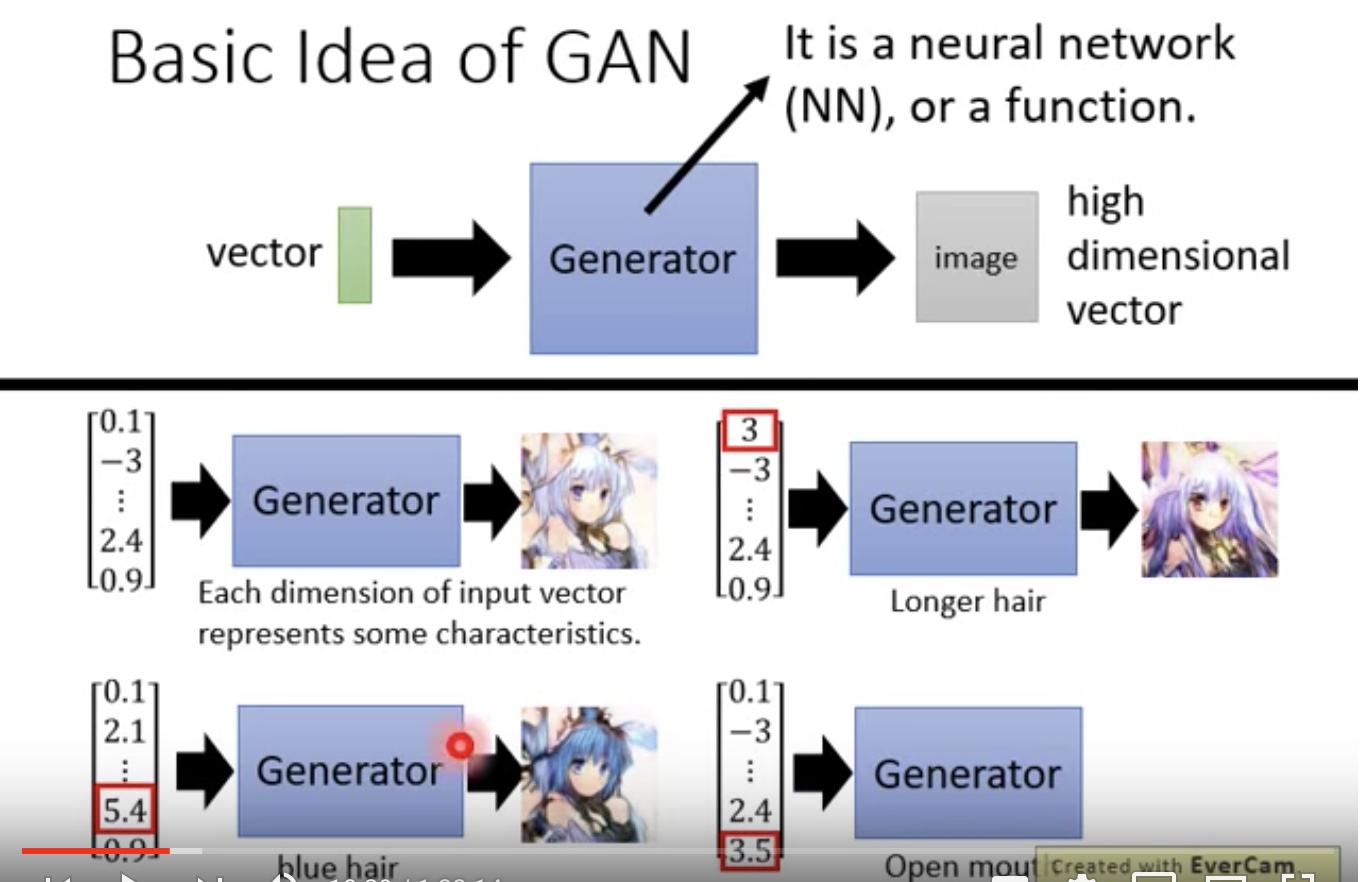
Basic idea of GAN
Generator
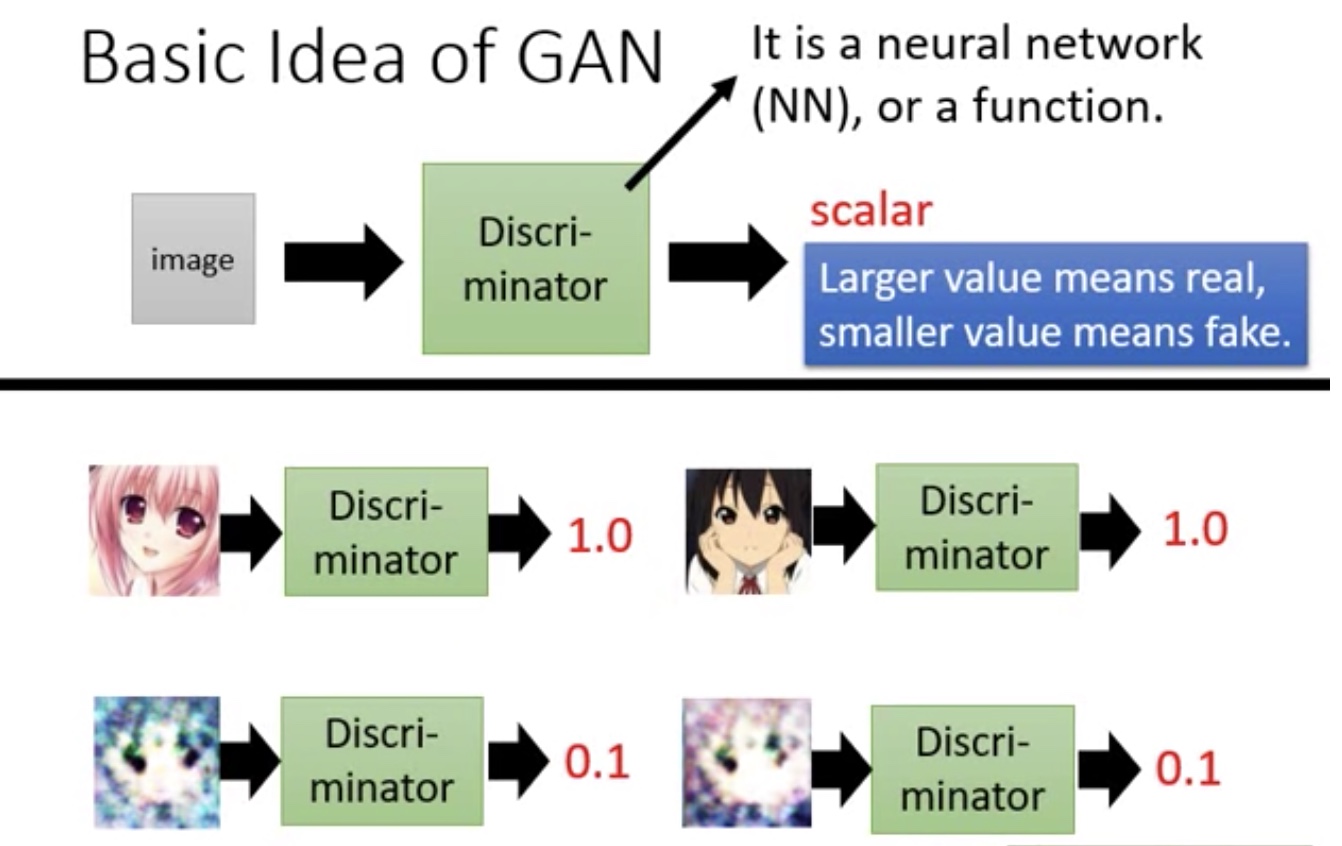
Discriminator(辨别者,鉴别器)
- 产出一个标量
形容关系:猎食者和天敌都在净化
- 天敌-Discriminator
枯叶蝶-Generator
- 枯叶蝶为了躲避猎食者的捕猎,不行进化自身
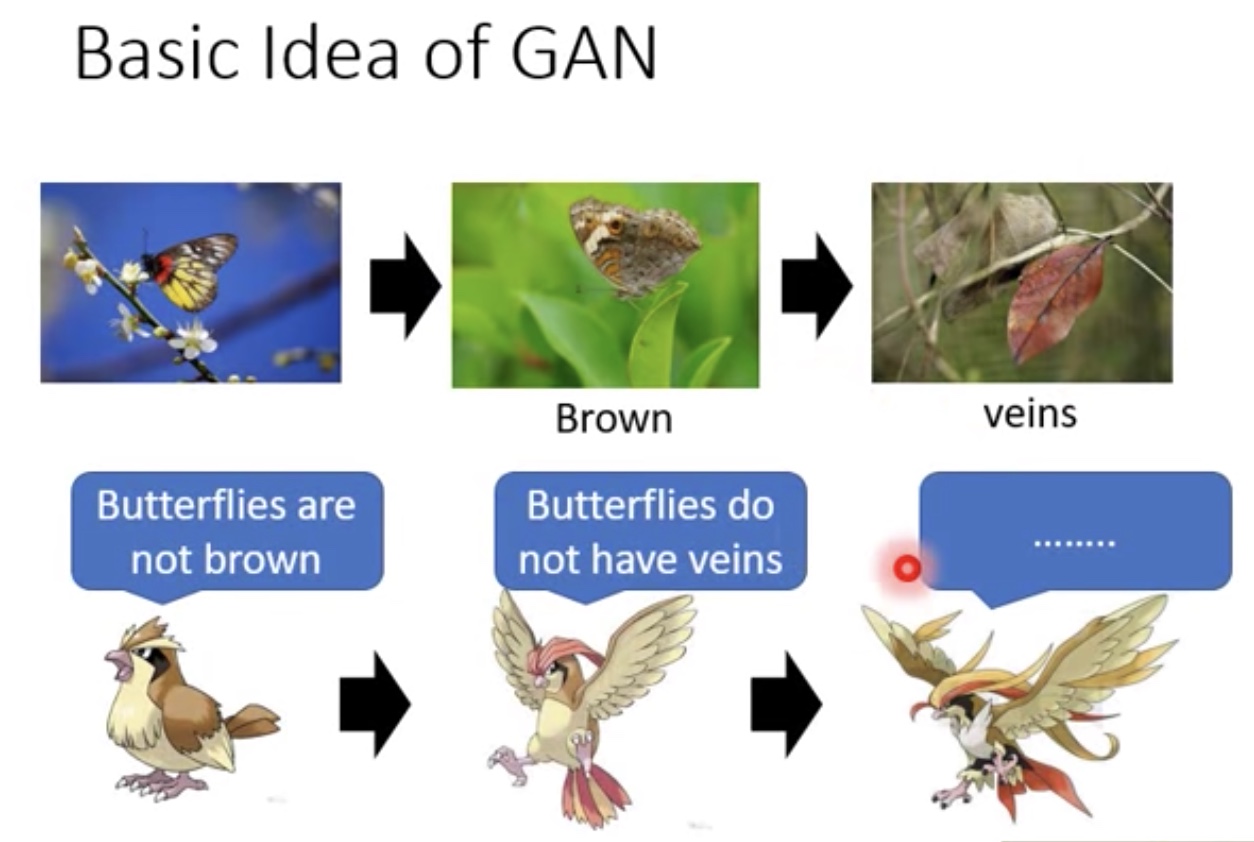
- 枯叶蝶为了躲避猎食者的捕猎,不行进化自身
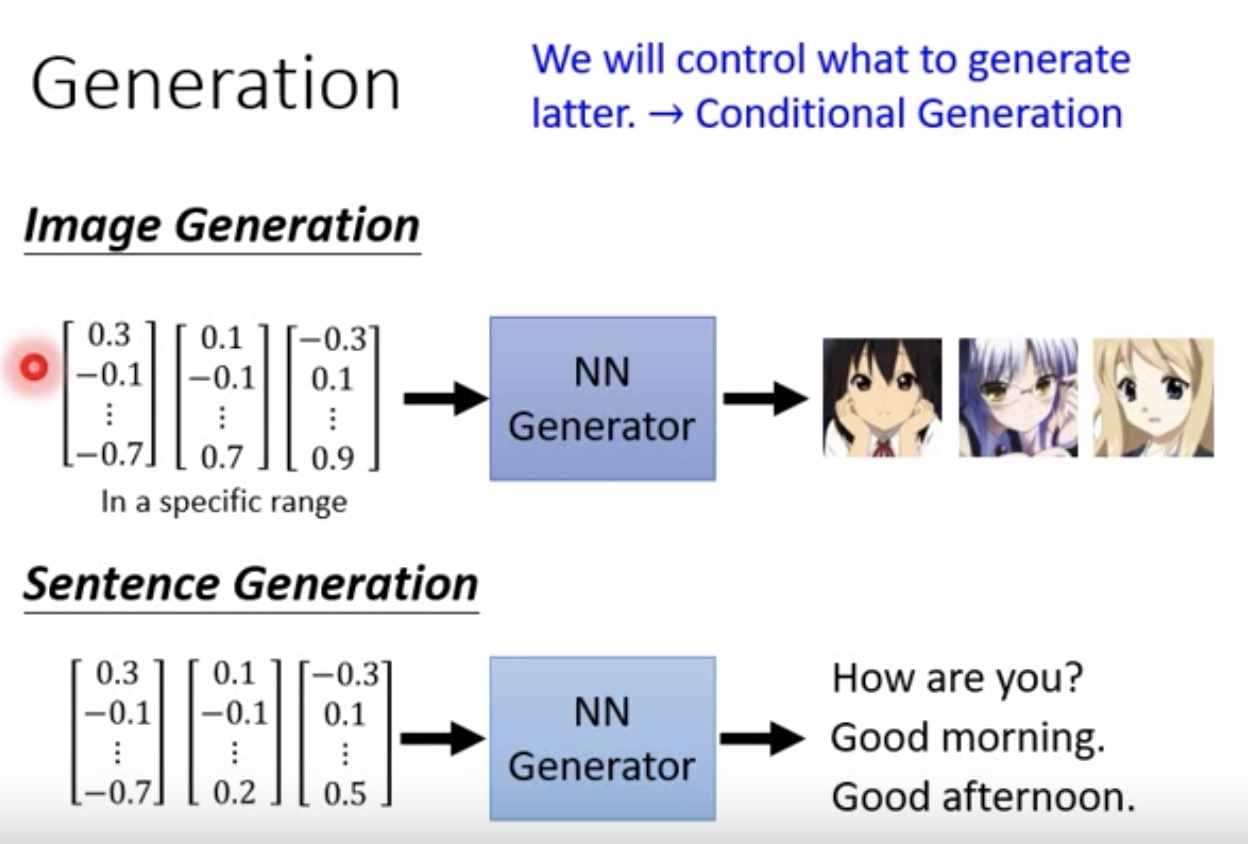
二次元也是一样的
- Generator,Discriminator不断进化Discriminator2骗过Generator1,Discriminator3骗过Generator2等
- 看起来Generator,Discriminator像是对抗的样子,所以是adversarial的由来
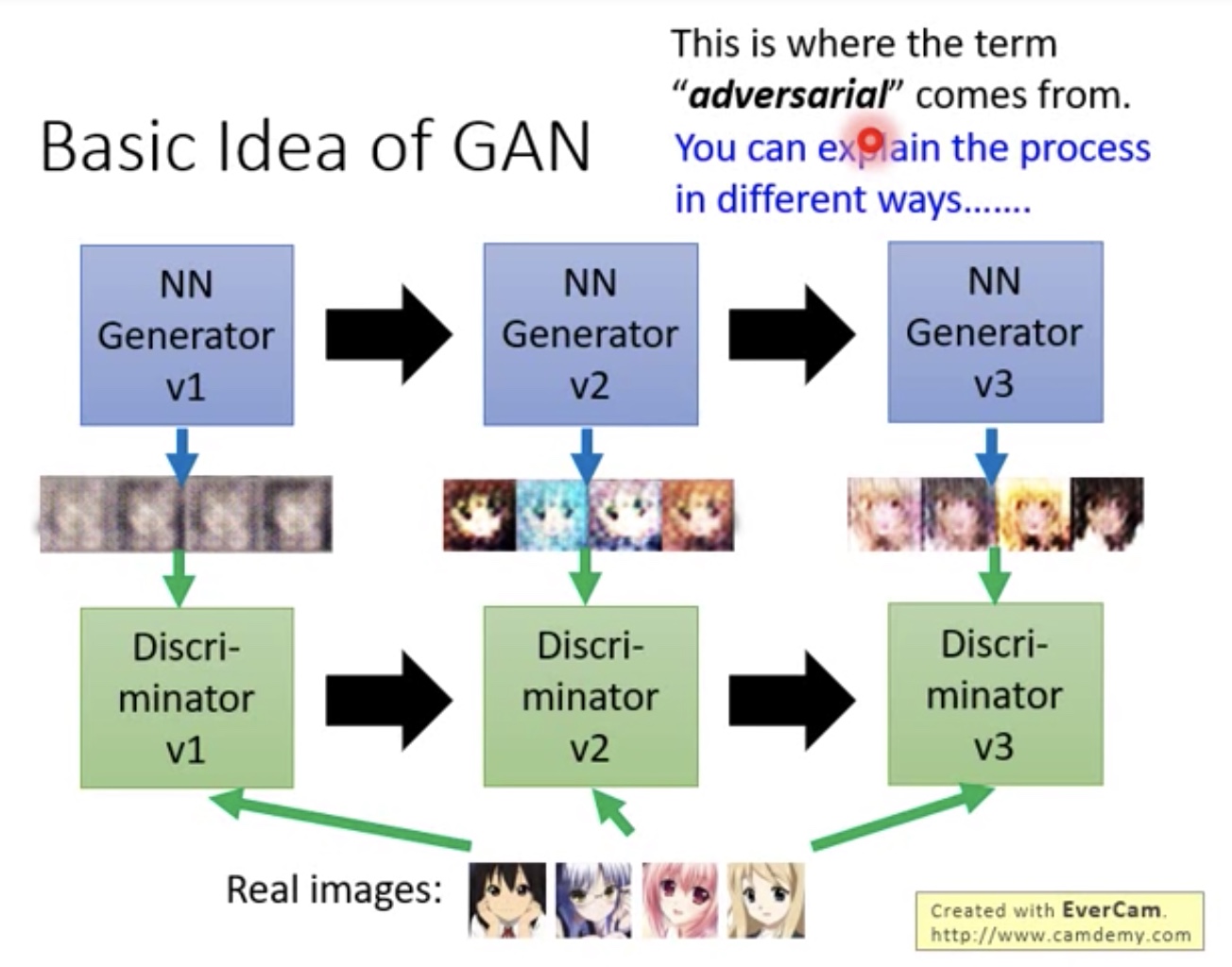
对抗只是拟人的方法,下面就是和平的比喻
- 问题:
- 1.为什么Generator不能自己学,而需要Discriminator驱动
- 2.为什么Discriminator不自己做
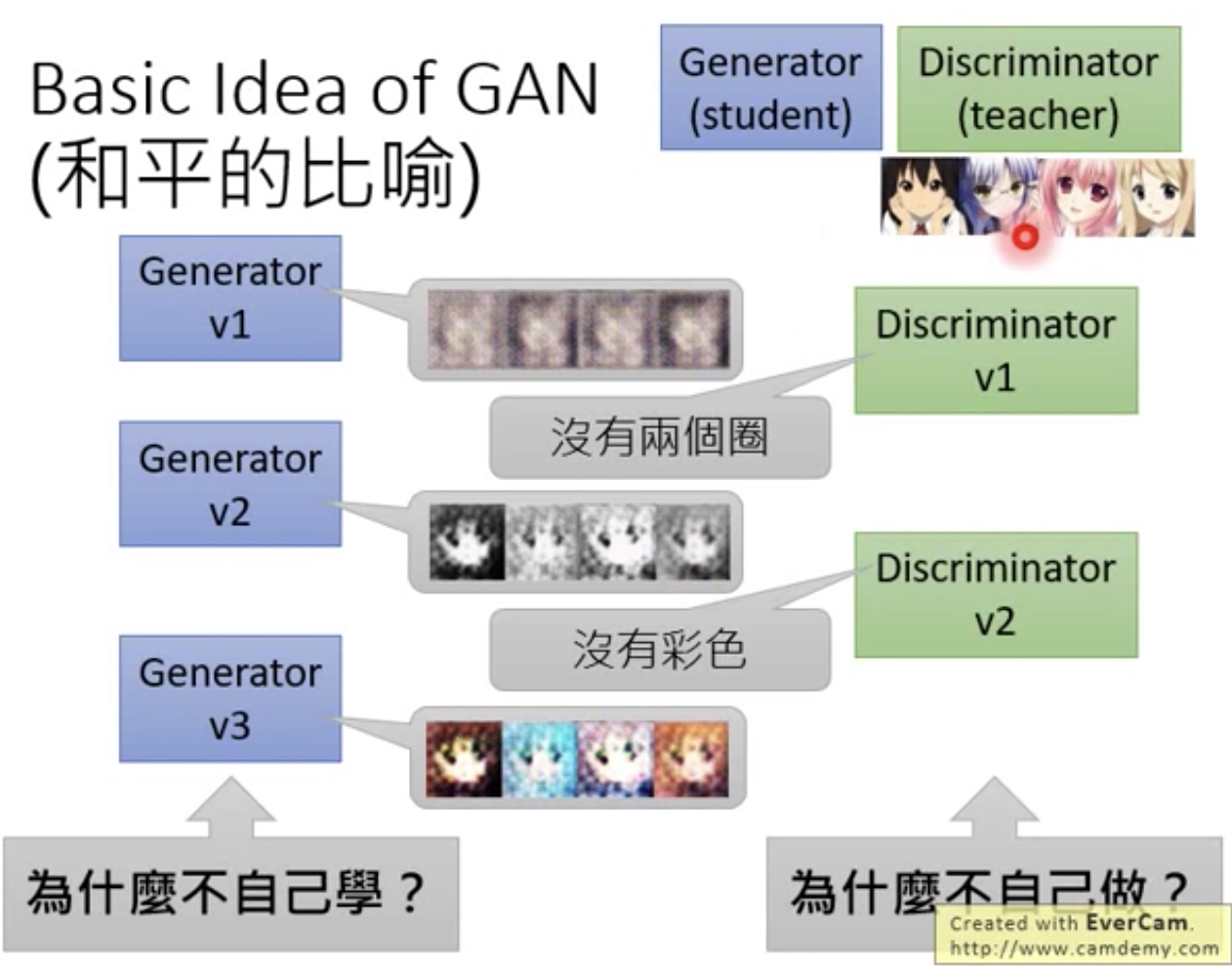
- 问题:
Algorithm
step1
- 训练Discriminator,使database中产生的结果很接近1,Generator产生的结果很接近0
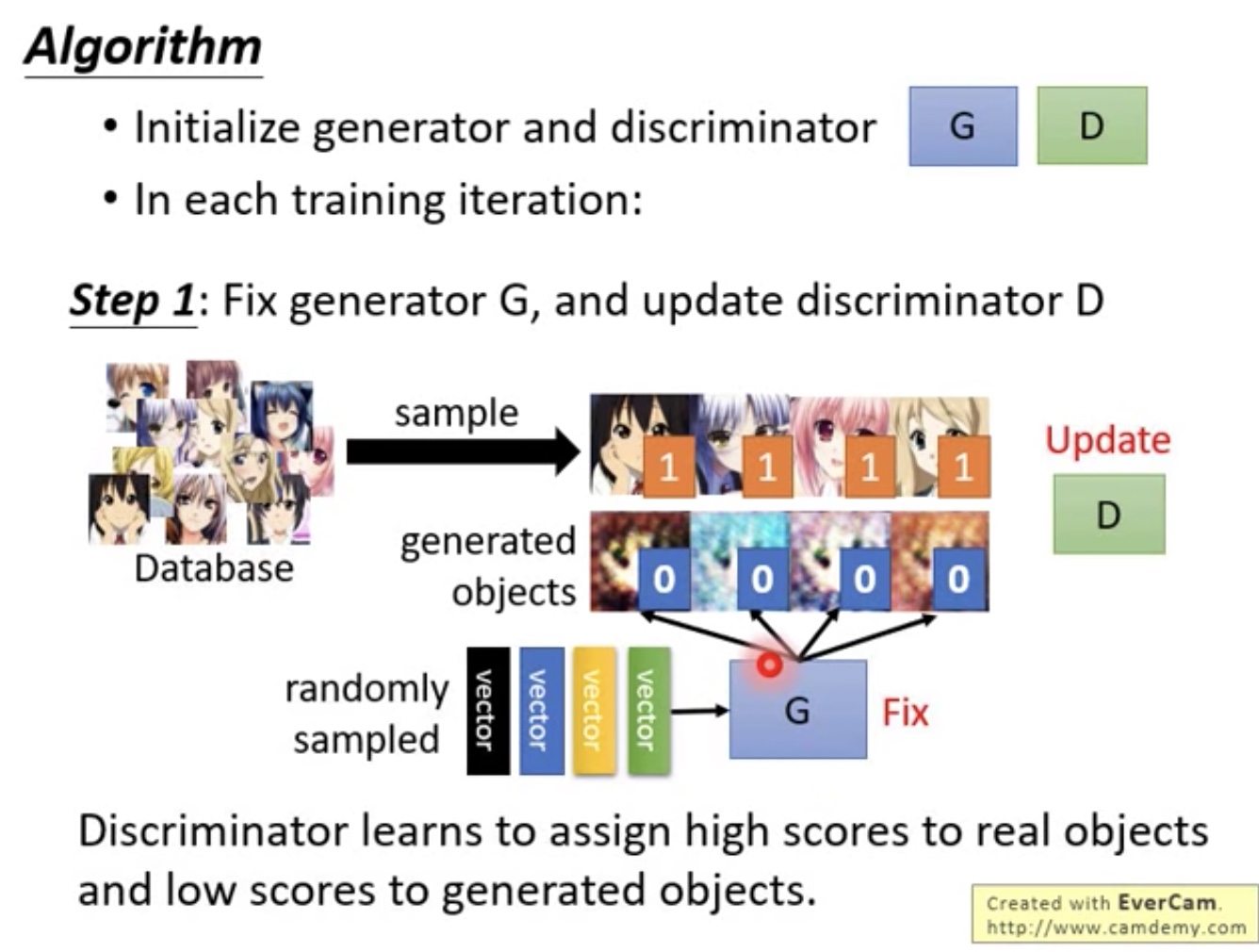
- 训练Discriminator,使database中产生的结果很接近1,Generator产生的结果很接近0
step2
- Fix Discriminator,update Generator
- Generator,Discriminator合一起,成一个巨大的网络,比如前几层是Generator,后几层是Discriminator
- 这一步目标就是巨大网络输出scala值要大(Gradient Ascent)
- 通常情况下,要让最后的输出很大,只需要调整最后一层softmax层就可以了
- 但是这里固定住后面几层,只让调整Generator
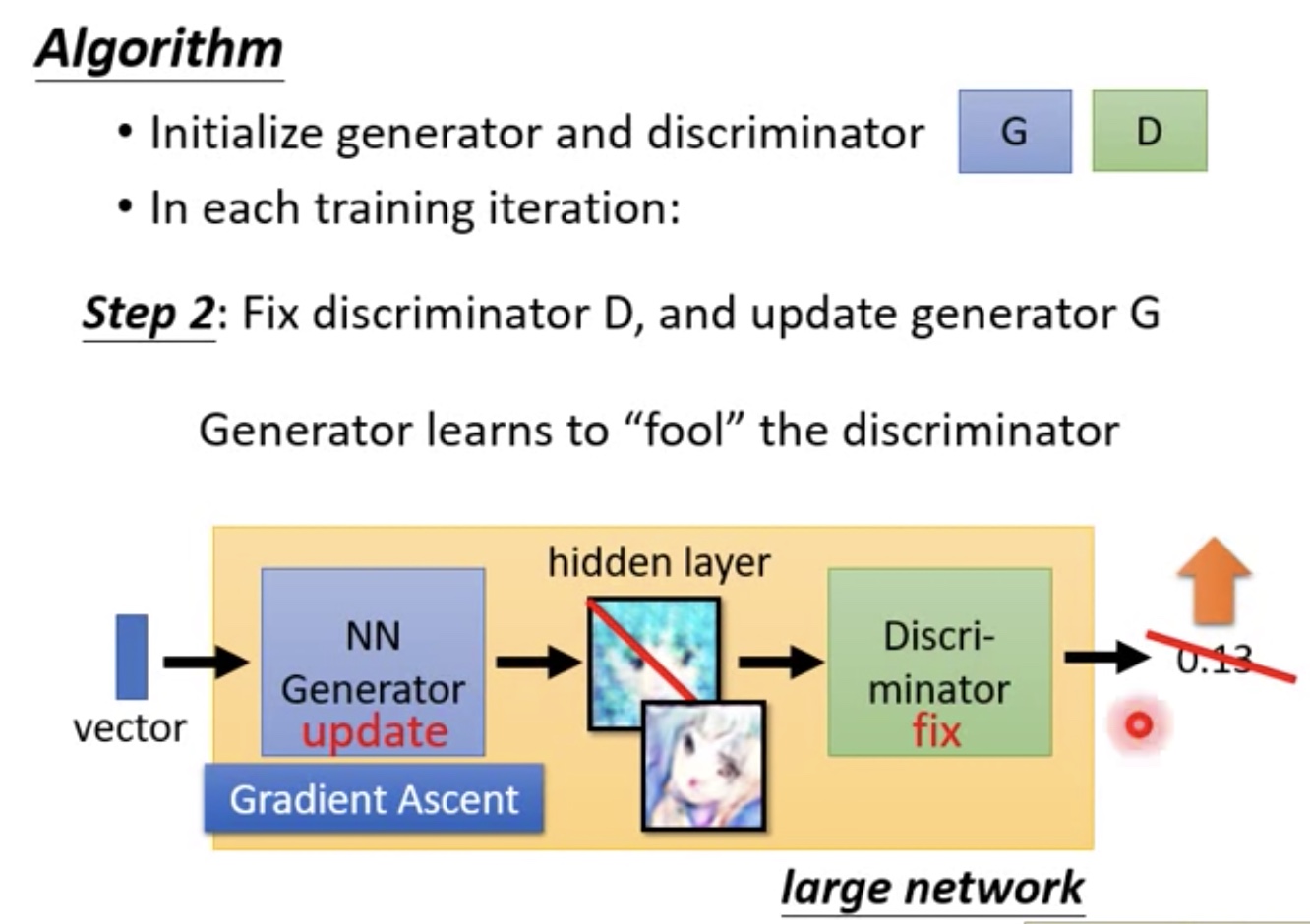
整体算法
- Learning D
- sample from database:$x^m$,noise samples:$z^m$
- $\tilde x^m=G(z^m)$表示Genertor产生的vector
- 然后通过梯度提升算法,最优化$\tilde V$,含义就是让$D(x^i)尽量大,D(\tilde x^i)$尽量小
- Learning G
- 目的就是update G,使其能够骗过D
- $D(G(z^i))$,理解其含义就是让noise数据经过G处理后,然后通过D(骗过D),得到最大的标量值

- Learning D
GAN as structured learning
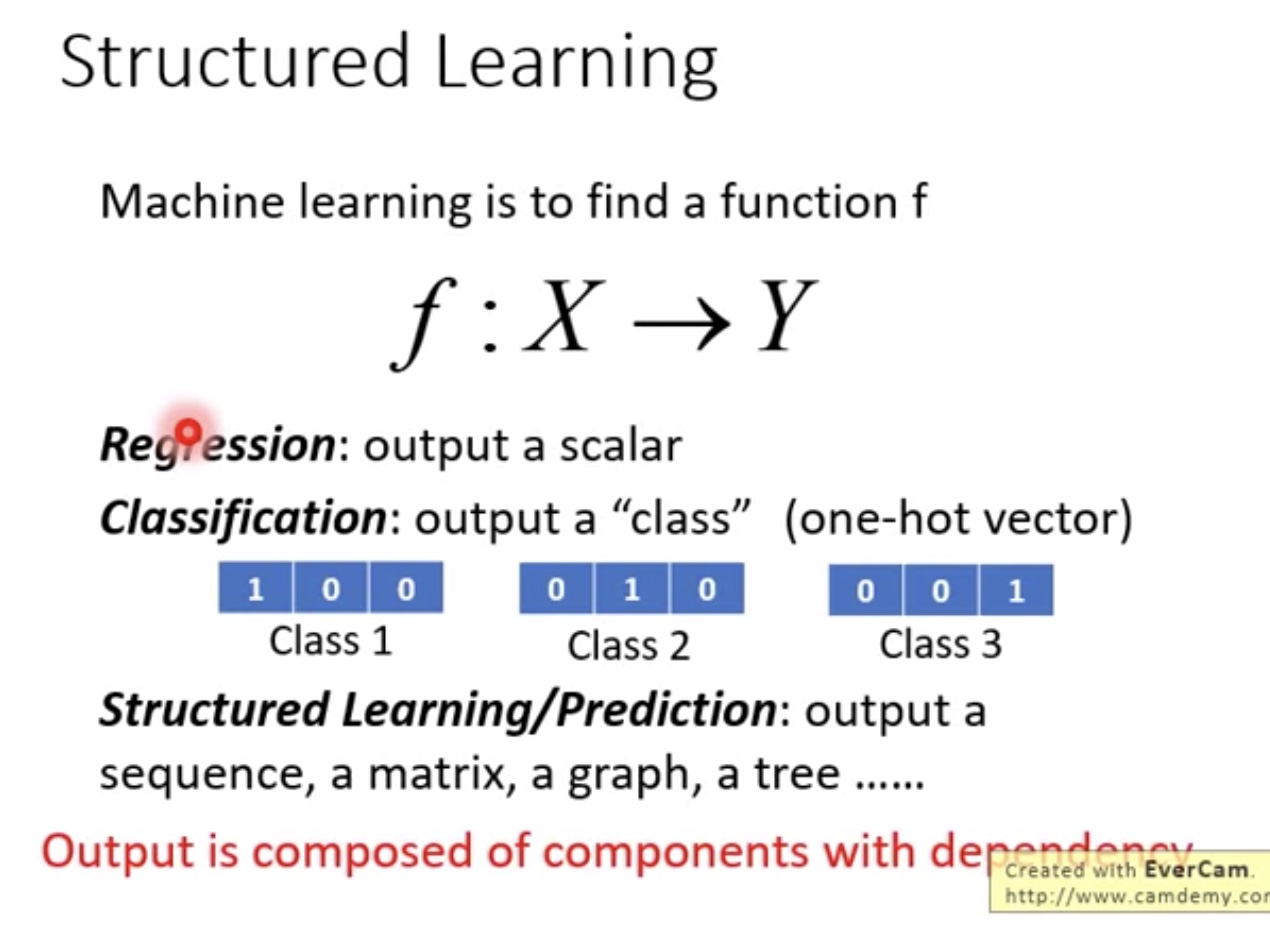
Structured Learning
- 当输出不是一个标量数值或者分类,是更负责的模型的时候,比如seq,matrix,graph等
- Why structured learning challenging
- 必须考虑大局观
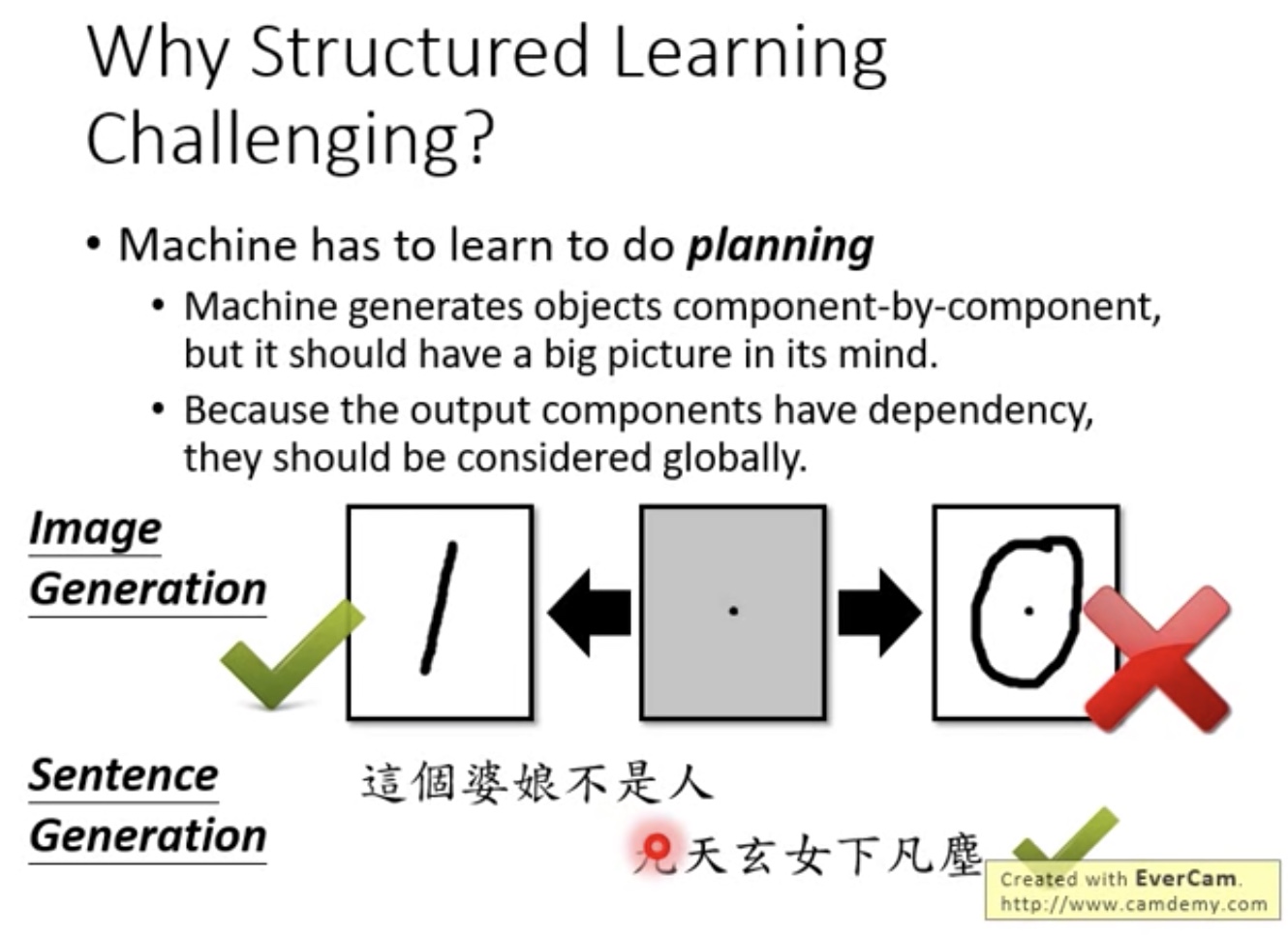
- 必须考虑大局观
- Structured Learning Approach
- Bottom up方法容易失去大局观
- 一个componet一个component地生成
- component与component之间的关系不容易把握
- Top Down方法不容易train
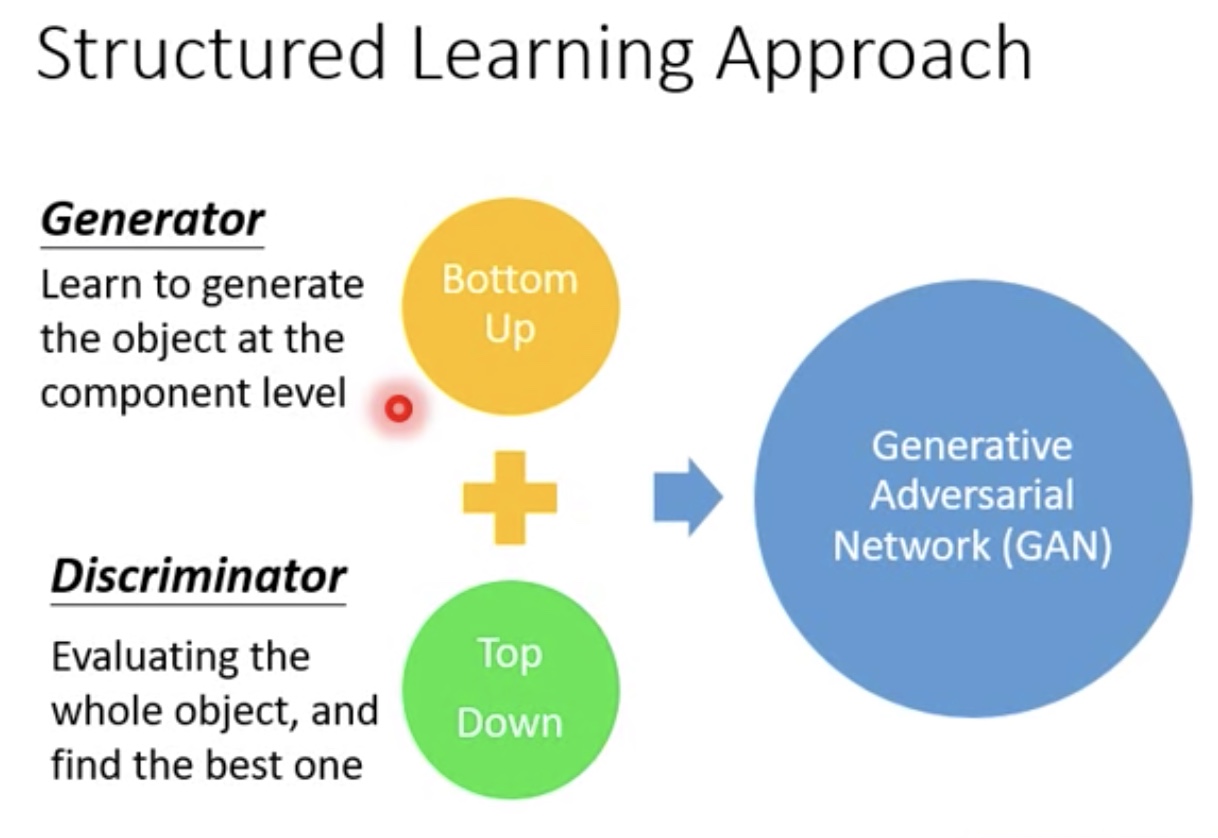
- Bottom up方法容易失去大局观
Can Generator learn by itself
NN Generator和NN Classifier比较类似
- 只是一个是输入vector,一个输入图像
- 问题:NN Generator如何产生输入的vector(将图片进行编码)?
- 不能够随机产生,因为如果随机产生,就无法表示出向量的相似性了(比如图片1有很多种,左斜,右斜等)
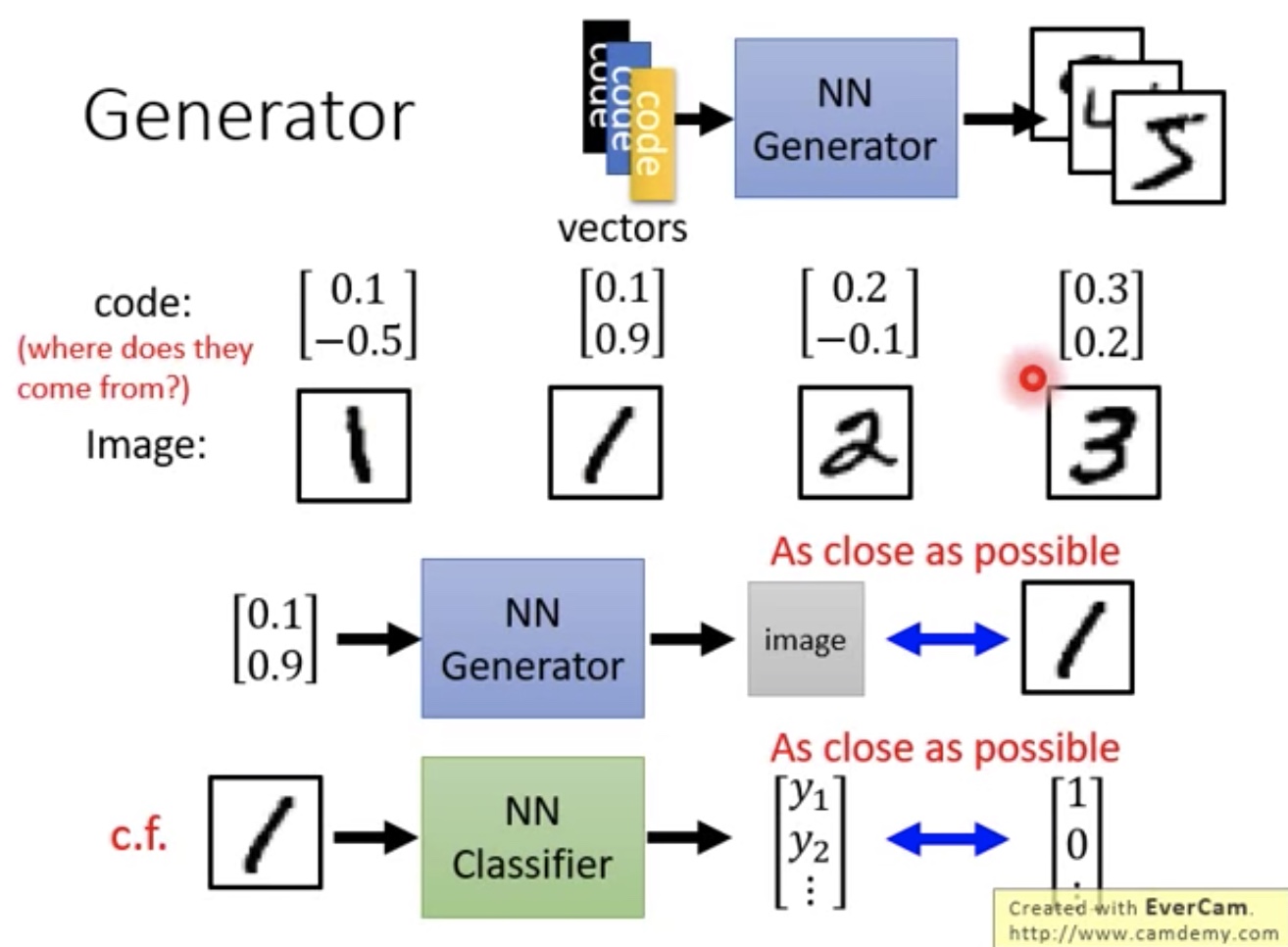
- 不能够随机产生,因为如果随机产生,就无法表示出向量的相似性了(比如图片1有很多种,左斜,右斜等)
Auto Encoder-Decoder
- 解决上面:NN Generator如何产生输入vector问题
- 如图:encode模块,对输入和输出图片越接近越好
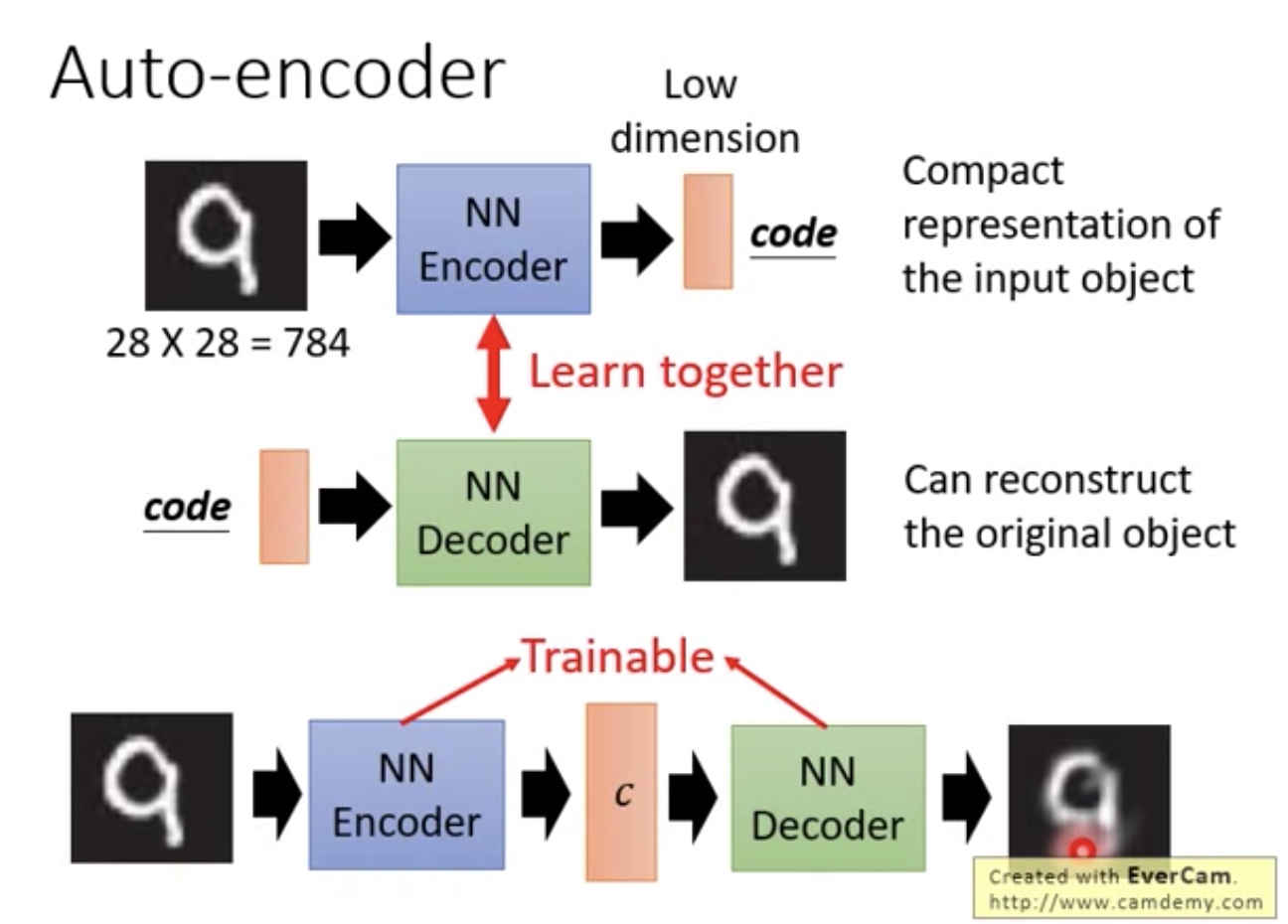
- 训练后好的Anto encoder中的NN Decoder其实就可以理解为NN Generator
- 简单来说就是输入一个vector,然后输出图像
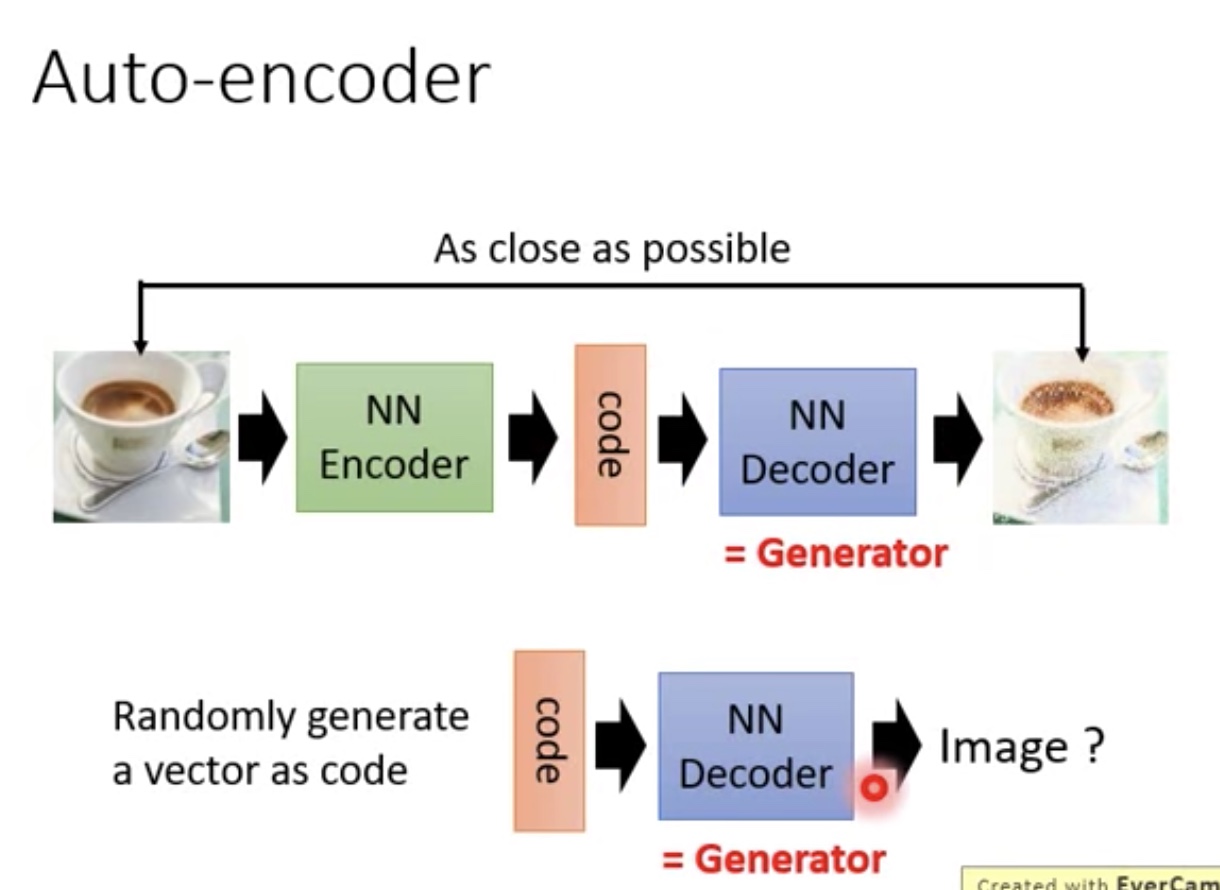
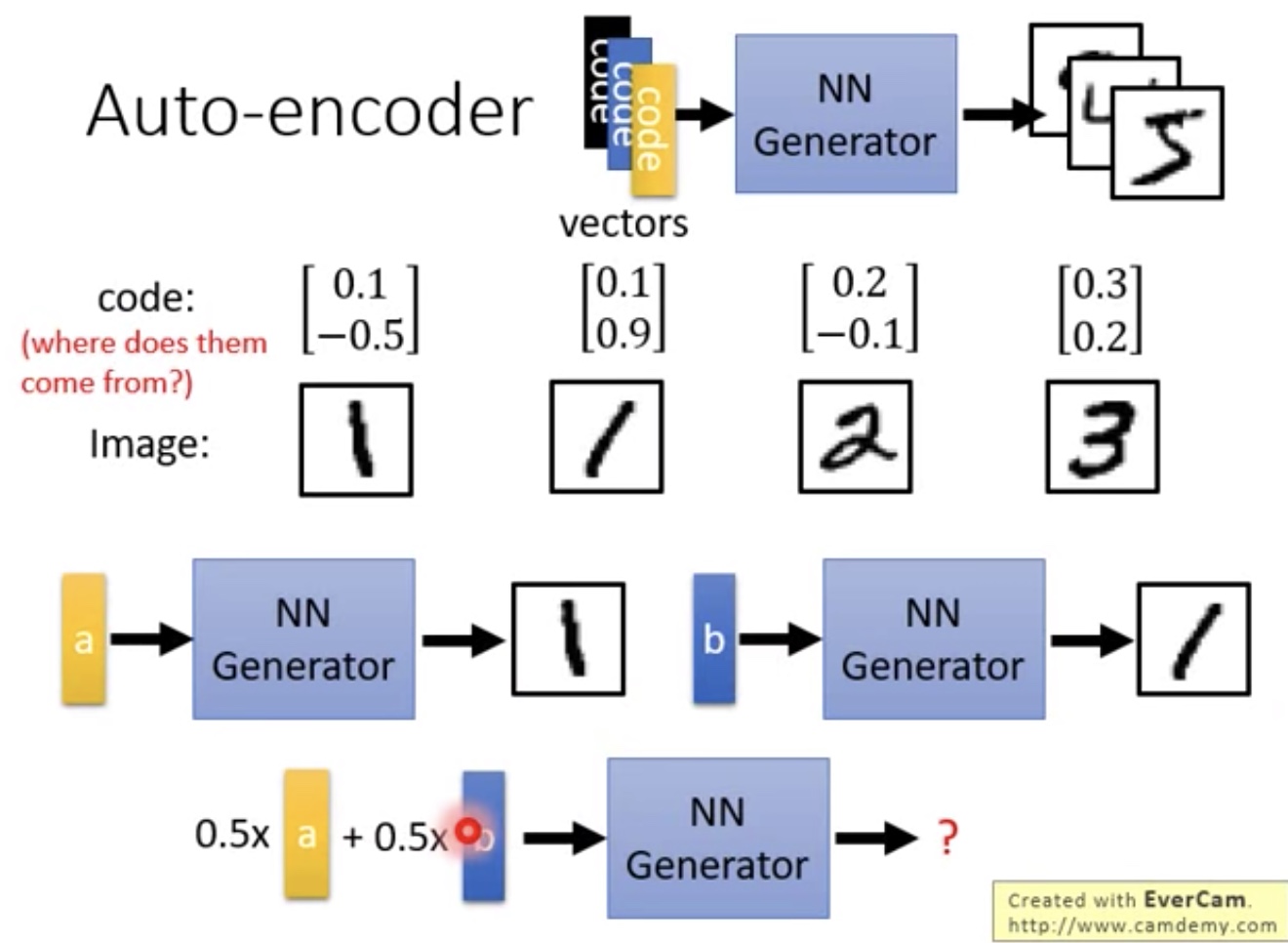
- 简单来说就是输入一个vector,然后输出图像
- 如果训练集数据比较小,当出现0.5a + 0.5b输入时无法判断
- a,b都能正确判断,但是当各0.5的时候就不好使了
- 如下使用VAE解决
VAE
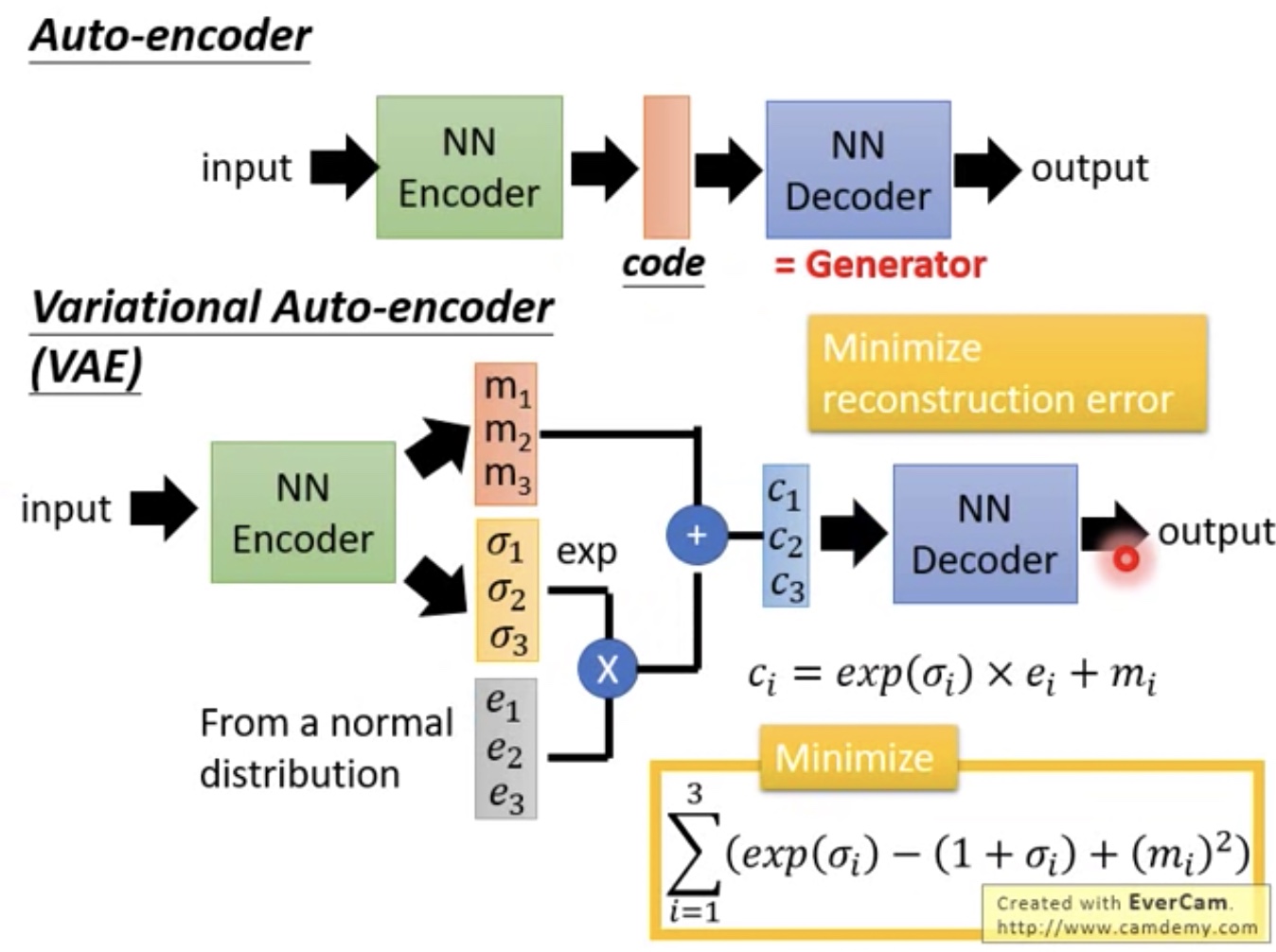
- 如何更好的判断input img和output img相似,如何取舍?
- 比如我们不能简单的用pixel不同个数来决定,如下图明显6 pixel error更好

- 比如我们不能简单的用pixel不同个数来决定,如下图明显6 pixel error更好
单纯的learn Generator困难的地方(Auto encoder可能遇见问题)
- 邻近的component无法交流
- 当然如果考虑更加深的NN,多加入些隐层,可能能够解决

- 当然如果考虑更加深的NN,多加入些隐层,可能能够解决
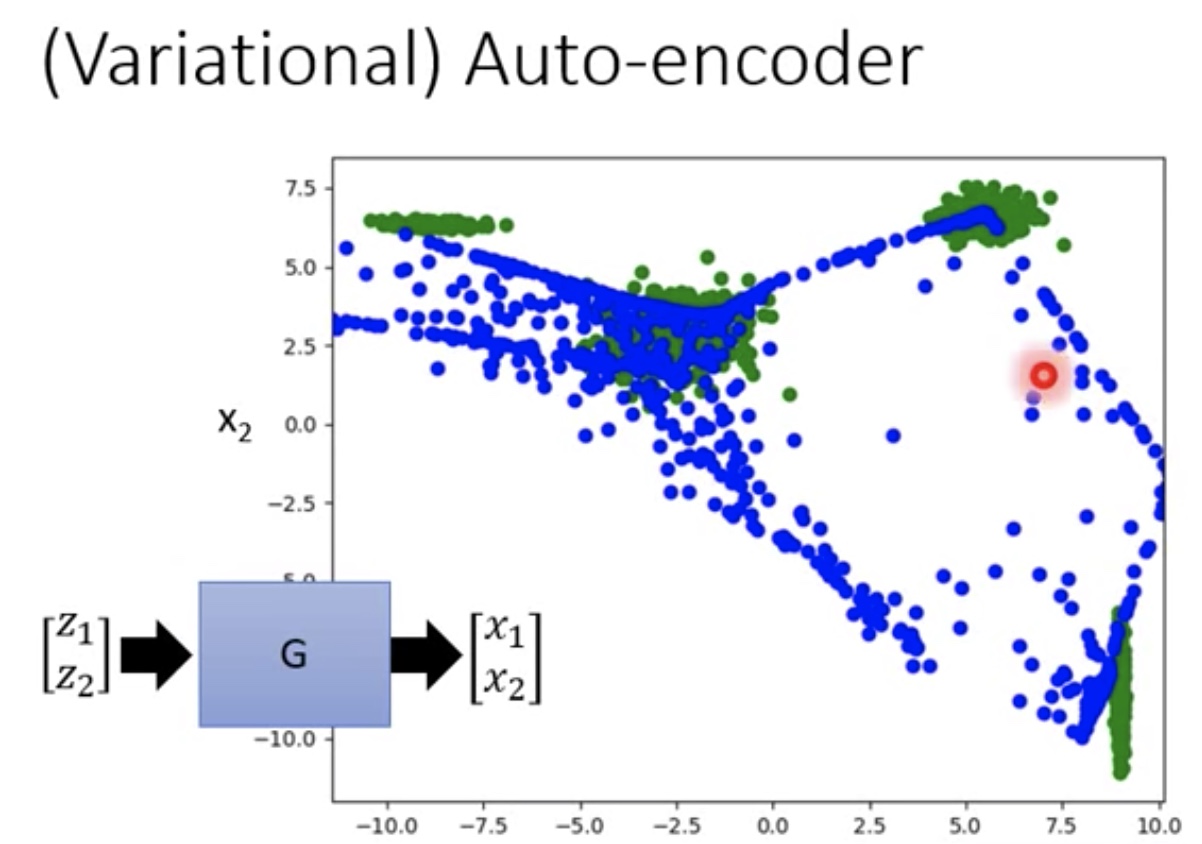
- 例如:
- 绿色为GAN得到的结论
- 蓝色为Auto-encoder(单纯Generator)得到的
- 原因是无法得到邻近的component的关系
Can Discriminator generate
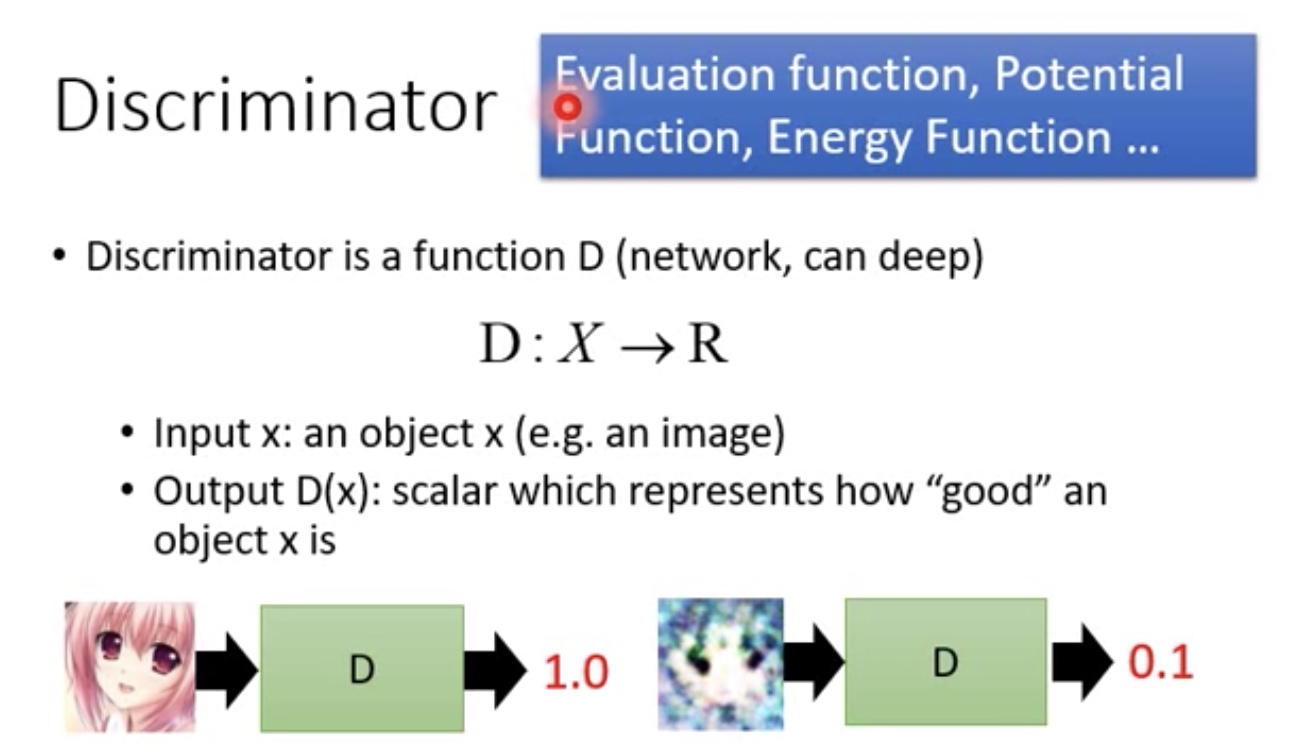
Discriminator复习
- Discriminator在不同的领域有不同的名字,evaluation function,potential function….
Discriminator容易解决component与component之间的关系
- 如果已经有了整张图片,来判断图片是否ok,比较好处理
- 比如下图中,Discriminator就是一个CNN,这个CNN中有一个检测是否有独立的的filter,这样就很容易检测了
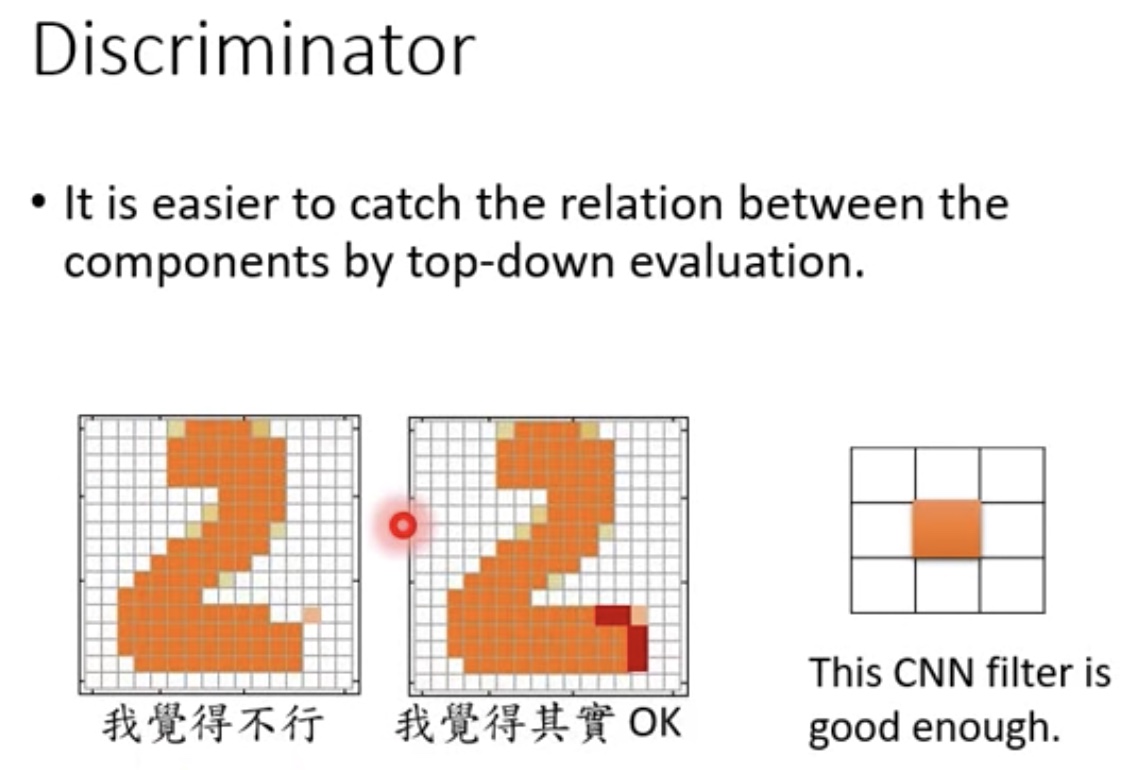
- 比如下图中,Discriminator就是一个CNN,这个CNN中有一个检测是否有独立的的filter,这样就很容易检测了
Discriminator擅长批评,不擅长生成

- need some negative example
- 所以产生negative example是关键
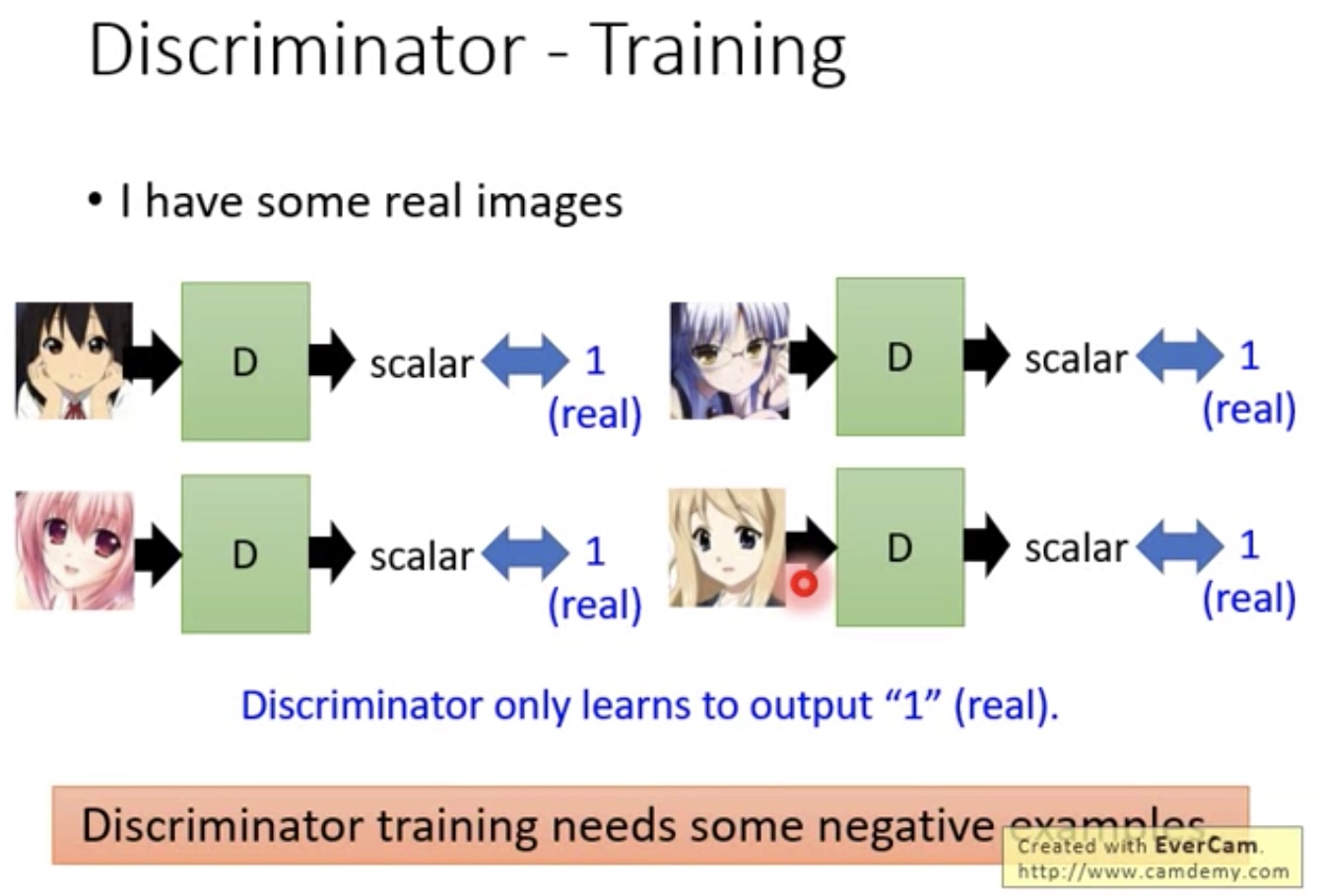
- 可能需要一个好的程序去产生negative example
- 并不能随机生成,如果随机生成,那么一些处于中间状态的图片也没有办法处理
- 而且需要一个Discriminator来判断是否是好的negative example
- 这样就会有鸡生蛋,蛋生鸡的问题了:我们需要好的negative example来训练Discriminator,同时又需要好的Discriminator来协助产生negative example

- 这样就会有鸡生蛋,蛋生鸡的问题了:我们需要好的negative example来训练Discriminator,同时又需要好的Discriminator来协助产生negative example
- 所以产生negative example是关键
- Iteration方法解决
- Discriminator Training
- 只要能够找到$\tilde x=arg maxD(x)$,Discriminator就能够自己train,而不需要Generator
- 用iteration方法,不断用此轮迭代得到的D去产生negative example(用D去找出自己的弱点),然后迭代训练

- Discriminator Training实际类似曲线图
- 第一张图中,可以看见在没有sample区域,D(x)也可能判断出很高的分数
- 第二张图中,用得到的D(x)生成新的negative example,然后再从新调整D(x)(让随机产生的negative example分数低)
- 第三张图中,就是第二轮训练后的曲线图
- 直观感觉:总体说就是用D(x)去生成非real example区域的高分negative example,然后不断调整自己,让其分数变低
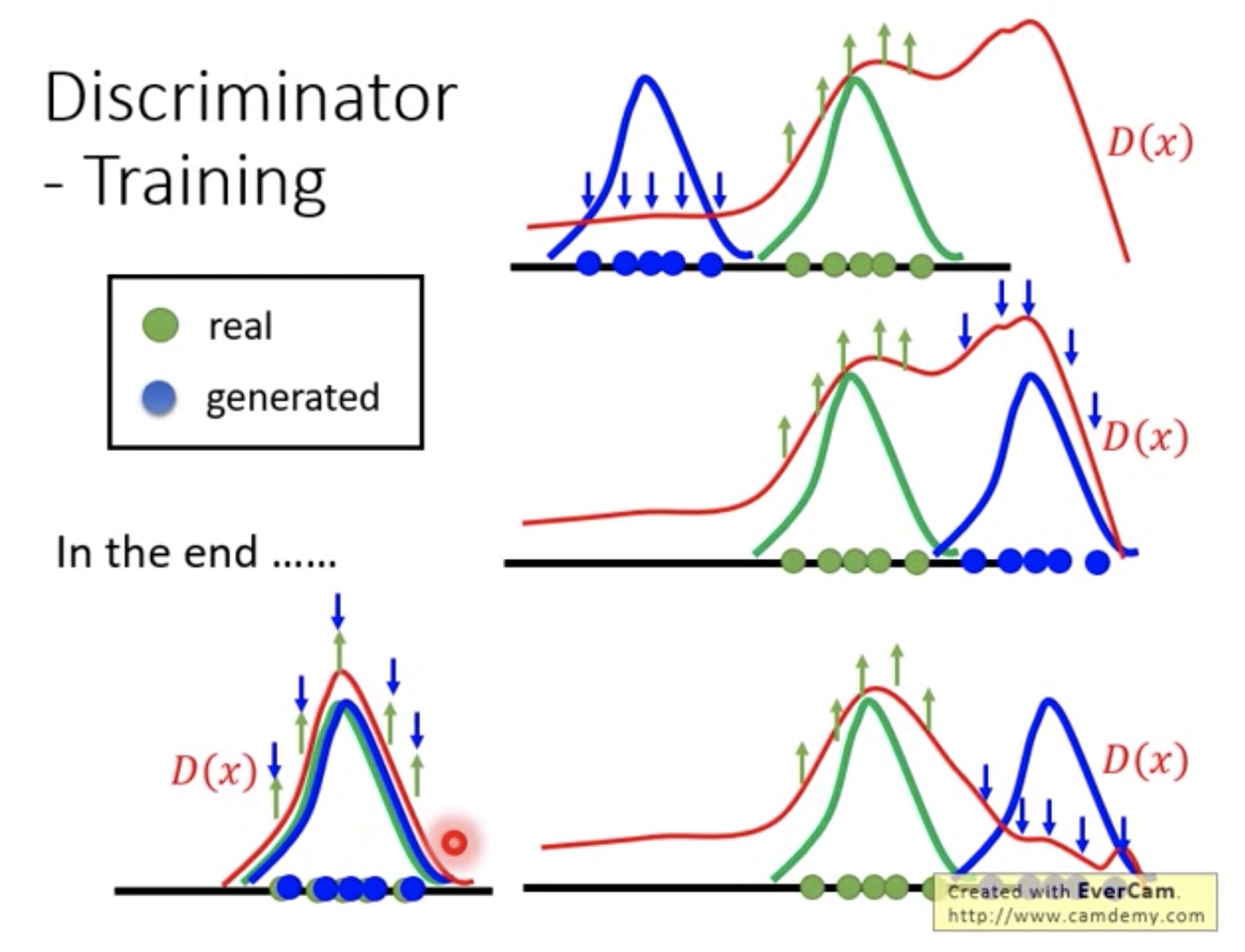
- 直观感觉:总体说就是用D(x)去生成非real example区域的高分negative example,然后不断调整自己,让其分数变低
- Discriminator Training
- Graphical model
- 其实就是用的Discriminator方法,在ml中其他的structure modle其实方法也是类似:
就是有一些negative和positive的样本,然后产生一个model,然后用此model再生成些negative example,然后再train….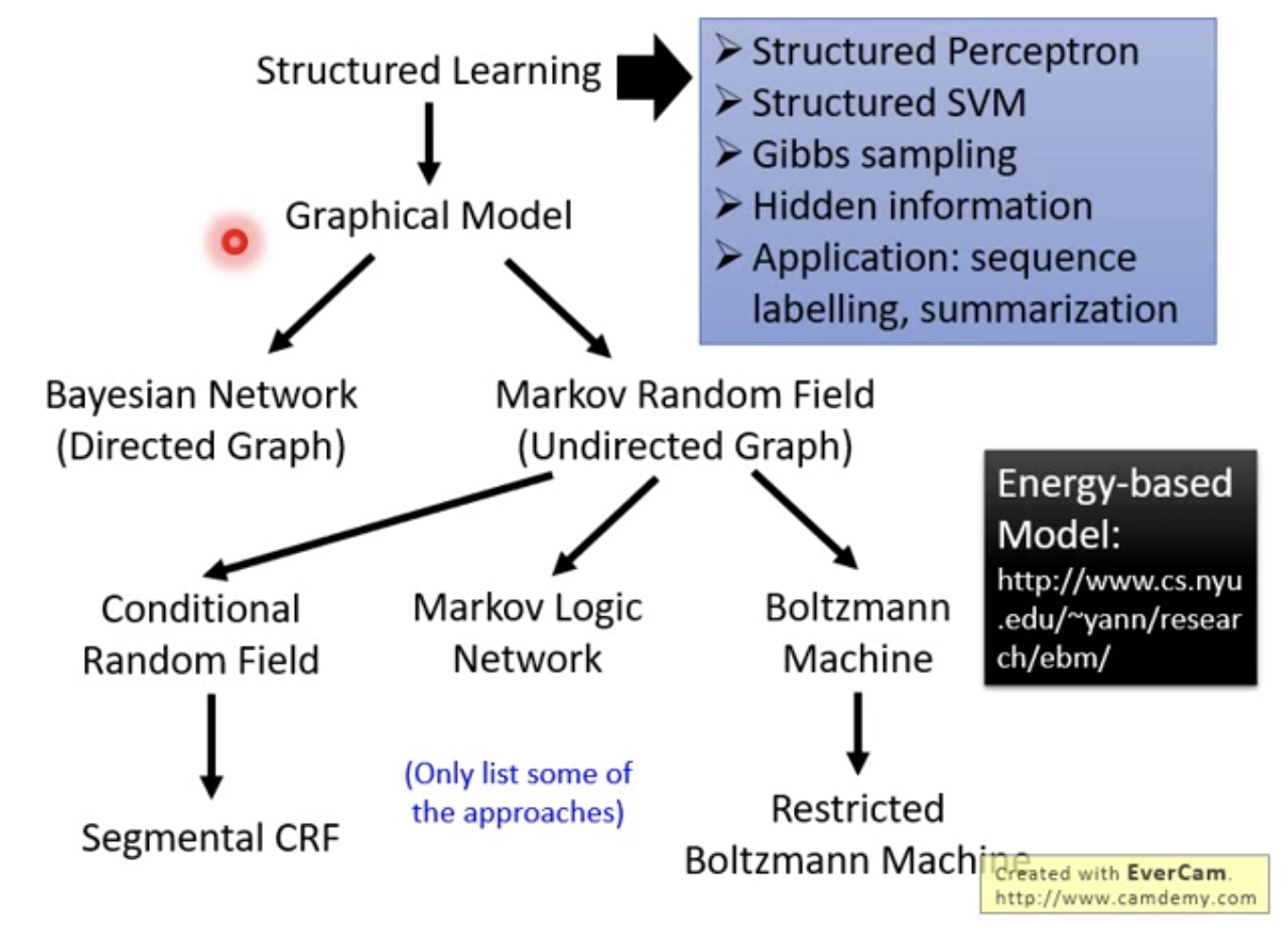
- 其实就是用的Discriminator方法,在ml中其他的structure modle其实方法也是类似:
Generator与Discriminator
- 优缺点
- Generator容易生成,但不易判断组件与组件直接的关系
- Discriminator有全局观,但不易做生成

- 组合
- Generator就替代了arg maxD(x),解决了Discriminator很难做生成的问题


- Generator就替代了arg maxD(x),解决了Discriminator很难做生成的问题
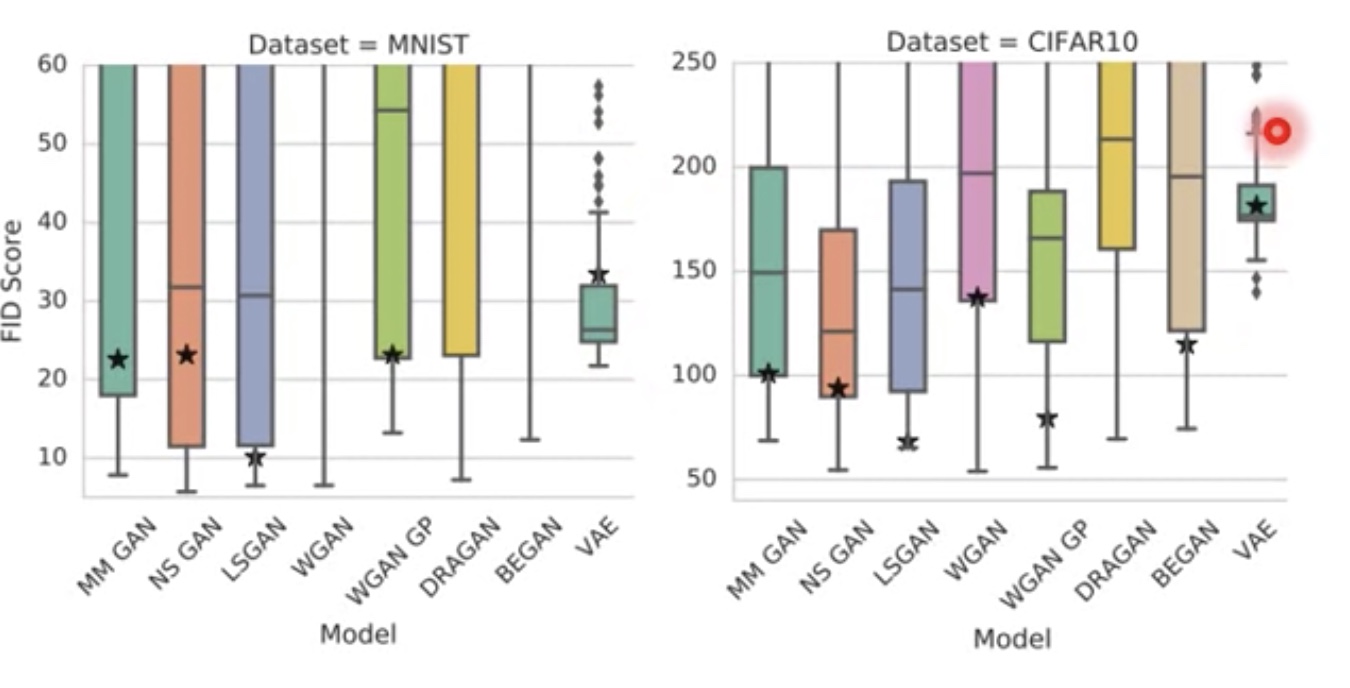
- VAE & GAN
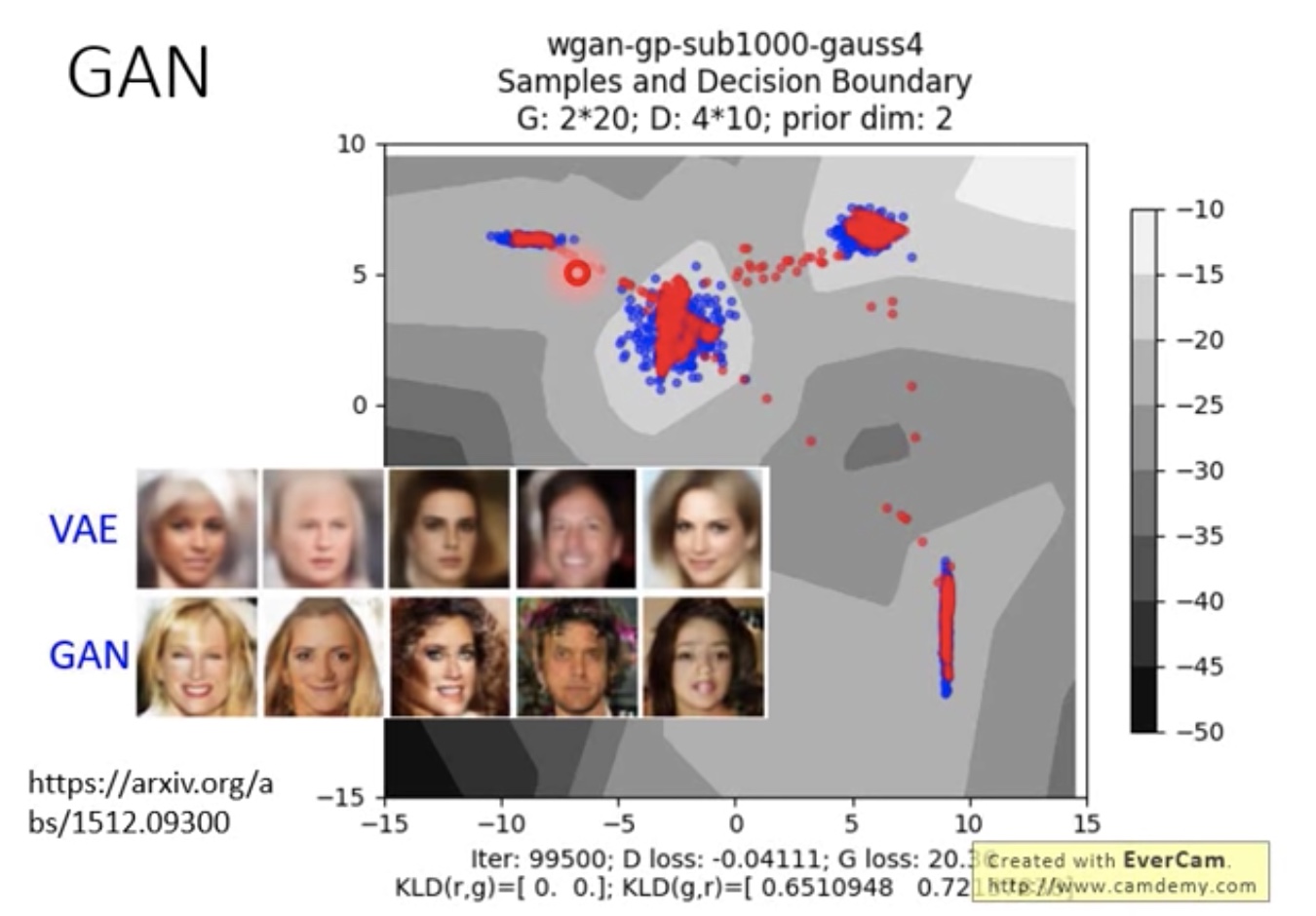
- VAE比较稳,但最终的效果还是没有GAN好
- 各种GAN其实效果没有太大区别