背景
- 前面的算法都是与真实的环境进行交互,个体并不试图去理解环境动力学
- 如果能构建一个较为准确地模拟环境动力学特 征的模型或者问题的模型本身就类似于一些棋类游戏是明确或者简单的,个体就可以通过构建这样的模型来模拟其与环境的交互,这种依靠模型模拟而不实际与环境交互的过程类似于“思考”过程
- 通过思考,个体可以对问题进行规划、在与环境实际交互时搜索交互可能产生的各种 后果并从中选择对个体有利的结果
- 我理解是通过模拟的环境,得到各自行为,然后与真实环境进行交互的时候,从这些模拟环境得到的行为中搜索,选择最优的结果
- 通过思考,个体可以对问题进行规划、在与环境实际交互时搜索交互可能产生的各种 后果并从中选择对个体有利的结果
环境的模型
模型是个体构建的对于环境动力学特征的表示
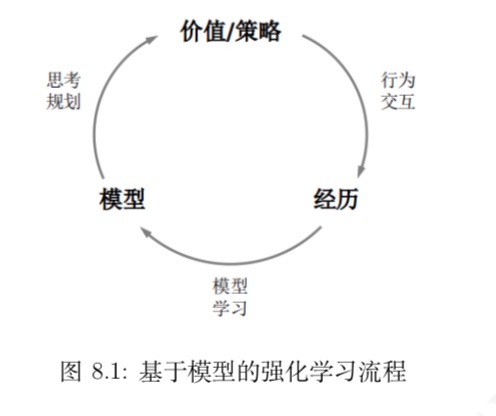
基于模型的强化学习流程
当个体得到了一 个较为准确的描述环境动力学的模型时,它在与环境交互的过程中,既可以通过实际交互来提高模型的准确程度,也可以在交互间隙利用构建的模型进行思考、规划,决策出对个体有力的行为
学习一个模型相当于丛经历 $S_1, A_1, R_2, . . . , S_T$ 中通过监督学习得到一个模型 $M_η$
- 训练数据为
$S_1,A_1 →R_2,S_2$
$S_2,A_2 →R_3,S_3$..
$S_{T−1},A_{T−1} →R_T,S_T$
- 训练数据为
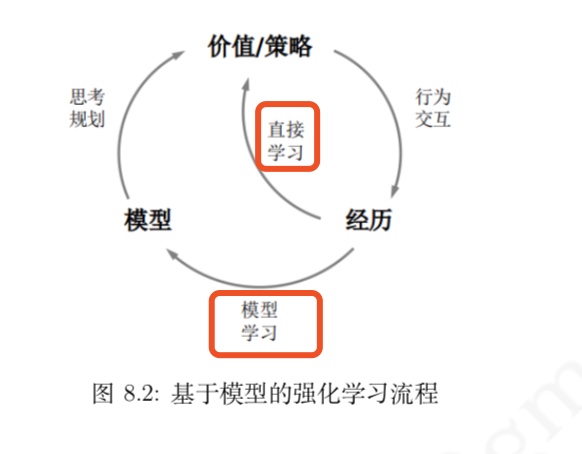
使用近似的模型解决强化学习问题与使用价值函数或策略函数的近似表达来解决强化学习问题并不冲突,它们是从不同角度来近似求解一个强化学习问题
- 当构建一个模型比构建近似价值函数 或近似策略函数更方便时,那么使用近似模型来求解会更加高效
特别注意模型参数要随着个体与环境交互而不断地动态更新,即通过实际经历要与使用模型产生的虚拟经历相结合来解决问题
- 这就催生了一类整合了学习与规划的强化学习算法——Dyna
Dyna算法(整合学习与规划)
- Dyna 算法从实际经历中学习得到模型,同时联合使用实际经历和基于模型采样得到的虚拟经历来学习和规划,更新价值和 (或) 策略函数
- 伪代码

- 我的理解:
- 从开始是通过真实环境去得到模型环境Model
- 下面会使用Model得到虚拟的经历,结合上面真实经历来更新Q(S,A)
- 我的理解:
基于模拟的搜索
- 前向搜索形式
在强化学习中,基于模拟的搜索 (simulation-based search) 是一种前向搜索形式,它从当前 时刻的状态开始,利用模型来模拟采样,构建一个关注短期未来的前向搜索树,将构建得到的搜索树作为一个学习资源,使用不基于模型的强化学习方法来寻找当前状态下的最优策略- 我的理解就是通过模型来构造一颗状态行为树,然后搜索在当前状态下的最优行为,也就是最优策略
- 如果使用蒙特卡罗学习方法则称为蒙特卡罗搜索,如果使用 Sarsa 学习方法,则称为 TD 搜索