深度强化学习的泡沫
背景
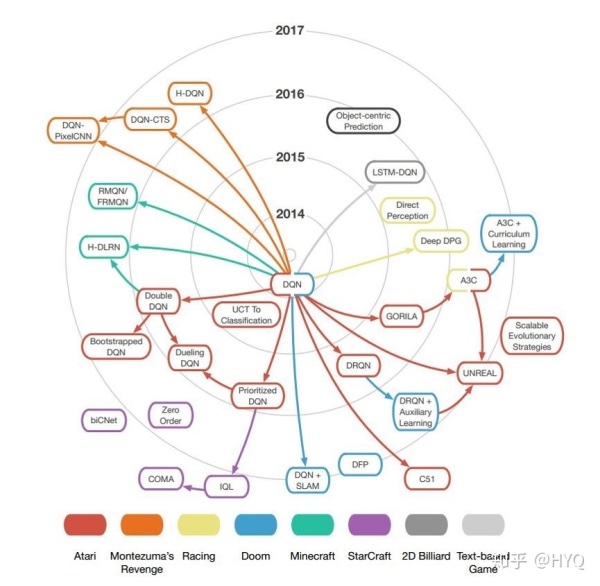
- 2015年,DeepMind的Volodymyr Mnih等研究员在《自然》杂志上发表论文Human-level control through deep reinforcement learning[1],该论文提出了一个结合深度学习(DL)技术和强化学习(RL)思想的模型Deep Q-Network(DQN),在Atari游戏平台上展示出超越人类水平的表现。自此以后,结合DL与RL的深度强化学习(Deep Reinforcement Learning, DRL)迅速成为人工智能界的焦点
- 过去三年间,DRL算法在不同领域大显神通,DeepMind负责AlphaGo项目的研究员David Silver喊出“AI = RL + DL”,认为结合了DL的表示能力与RL的推理能力的DRL将会是人工智能的终极答案
DRL的可复现性危机
- 由于发表的文献中往往不提供重要参数设置和工程解决方案的细节,很多算法都难以复现,RL专家直指当前DRL领域论文数量多却水分大、实验难以复现等问题。该文在学术界和工业界引发热烈反响。很多人对此表示认同,并对DRL的实际能力产生强烈怀疑
- 针对DRL领域,Pineau展示了该研究组对当前不同DRL算法的大量可复现性实验。实验结果表明,不同DRL算法在不同任务、不同超参数、不同随机种子下的效果大相径庭
DRL研究存在多少坑
2018年的情人节当天,曾经就读于伯克利人工智能研究实验室的Alexirpan通过一篇博文Deep Reinforcement Learning Doesn’t Work Yet[13]给DRL圈送来了一份苦涩的礼物,从实验角度总结了DRL算法存在的几大问题:
- 样本利用率非常低;
- 最终表现不够好,经常比不过基于模型的方法;
- 好的奖励函数难以设计;
- 难以平衡 “ 探索 ” 和 “ 利用 ” ,以致算法陷入局部极小;
- 对环境的过拟合;
- 灾难性的不稳定性…
负面评论还将持续发酵。那么, DRL的问题根结在哪里?前景真的如此黯淡吗?如果不与深度学习结合,RL的出路又在哪里?
免模型强化学习的本质缺陷
RL分类
RL算法可以分为基于模型的方法(Model-based)与免模型的方法(Model-free)
- 前者主要发展自最优控制领域。通常先通过高斯过程(GP)或贝叶斯网络(BN)等工具针对具体问题建立模型,然后再通过机器学习的方法或最优控制的方法,如模型预测控制(MPC)、线性二次调节器(LQR)、线性二次高斯(LQG)、迭代学习控制(ICL)等进行求解
- 而后者更多地发展自机器学习领域,属于数据驱动的方法。算法通过大量采样,估计代理的状态、动作的值函数或回报函数,从而优化动作策略
免模型缺陷
- Ben Recht连发了13篇博文,从控制与优化的视角,重点探讨了RL中的免模型方法[18]。Recht指出免模型方法自身存在以下几大缺陷
- 免模型方法无法从不带反馈信号的样本中学习,而反馈本身就是稀疏的,因此免模型方向样本利用率很低,而数据驱动的方法则需要大量采样
- 比如在Atari平台上的《Space Invader》和《Seaquest》游戏中,智能体所获得的分数会随训练数据增加而增加。利用免模型DRL方法可能需要 2 亿帧画面才能学到比较好的效果。AlphaGo 最早在 Nature 公布的版本也需要 3000 万个盘面进行训练。而但凡与机械控制相关的问题,训练数据远不如视频图像这样的数据容易获取,因此只能在模拟器中进行训练。而模拟器与现实世界间的Reality Gap,直接限制了训练自其中算法的泛化性能。另外,数据的稀缺性也影响了其与DL技术的结合
- 免模型方法不对具体问题进行建模,而是尝试用一个通用的算法解决所有问题。而基于模型的方法则通过针对特定问题建立模型,充分利用了问题固有的信息。免模型方法在追求通用性的同时放弃这些富有价值的信息
- 基于模型的方法针对问题建立动力学模型,这个模型具有解释性。而免模型方法因为没有模型,解释性不强,调试困难
- 相比基于模型的方法,尤其是基于简单线性模型的方法,免模型方法不够稳定,在训练中极易发散
- 免模型方法无法从不带反馈信号的样本中学习,而反馈本身就是稀疏的,因此免模型方向样本利用率很低,而数据驱动的方法则需要大量采样
通过Recht的分析,我们似乎找到了DRL问题的根结。近三年在机器学习领域大火的DRL算法,多将免模型方法与DL结合,而免模型算法的天然缺陷,恰好与Alexirpan总结的DRL几大问题相对应
为什么多数DRL的工作都是基于免模型方法呢
- 免模型的方法相对简单直观,开源实现丰富,比较容易上手
- 当前RL的发展还处于初级阶段,学界的研究重点还是集中在环境是确定的、静态的,状态主要是离散的、静态的、完全可观察的,反馈也是确定的问题(如Atari游戏)上。针对这种相对“简单”、基础、通用的问题,免模型方法本身很合适
- 绝大多数DRL方法是对DQN的扩展,属于免模型方法
基于模型或免模型,问题没那么简单
基于模型的方法,未来潜力巨大
基于模型的方法一般先从数据中学习模型,然后基于学到的模型对策略进行优化。学习模型的过程和控制论中的系统参数辨识类似
- 因为模型的存在,基于模型的方法可以充分利用每一个样本来逼近模型,数据利用率极大提高
- 基于模型的方法则在一些控制问题中,相比于免模型方法,通常有10^2级的采样率提升。
- 此外,学到的模型往往对环境的变化鲁棒,当遇到新环境时,算法可以依靠已学到的模型做推理,具有很好的泛化性能
- 预测学习(Predictive Learning)关系
基于模型的方法还与潜力巨大的预测学习(Predictive Learning)紧密相关。由于建立了模型,本身就可以通过模型预测未来,这与Predictive Learning的需求不谋而合- 基于模型的RL方法可能是实现Predictive Learning的重要技术之一
基于模型问题也较多,免模型方法,依旧是第一选择
基于模型的DRL方法相对而言不那么简单直观,RL与DL的结合方式相对更复杂,设计难度更高。目前基于模型的DRL方法通常用高斯过程、贝叶斯网络或概率神经网络(PNN)来构建模型
基于模型的方法也还若干自身缺陷
- 针对无法建模的问题束手无策
- 建模会带来误差,而且误差往往随着算法与环境的迭代交互越来越大,使得算法难以保证收敛到最优解
- 模型缺乏通用性,每次换一个问题,就要重新建模
- 可能的工作,笔者认为
- 我们可以考虑多做一些基于模型的DRL方面的工作,克服当前DRL存在的诸多问题
- 此外,还可以多研究结合基于模型方法与免模型方法的半模型方法,兼具两种方法的优势
- 这方面经典的工作有RL泰斗Rich Sutton提出的Dyna框架和Dyna-2框架[28]
其他问题
- 模拟器存在非常大的问题,经过调试的线性策略就已经可以取得非常好的效果——这样的模拟器实在过于粗糙,难怪基于随机搜索的方法可以在同样的模拟器上战胜免模型方法
- 可见目前RL领域的实验平台还非常不成熟,在这样的测试环境中的实验实验结果没有足够的说服力。很多研究结论都未必可信
- 一些学者指出当前RL算法的性能评判准则也不科学
重新审视强化学习
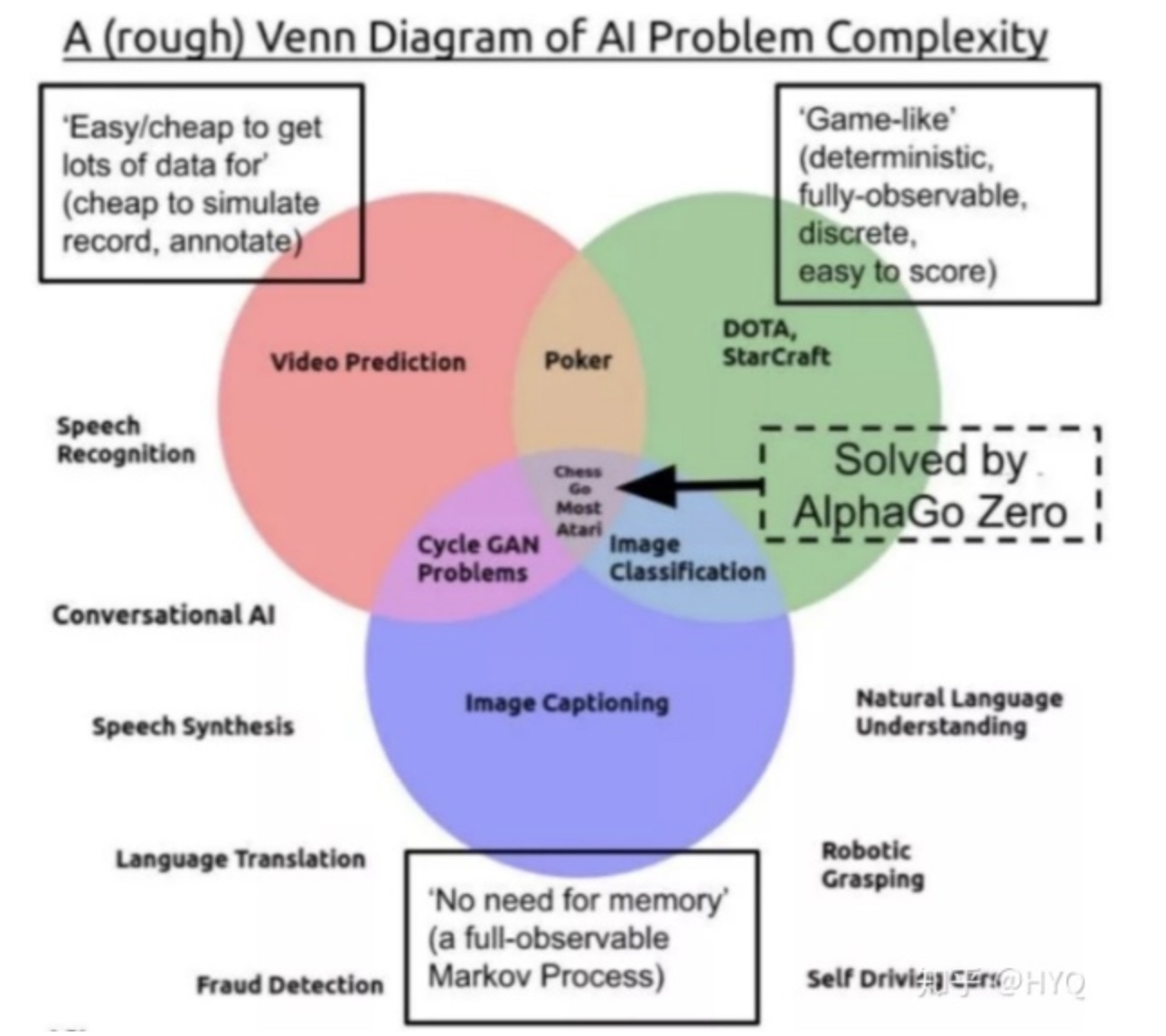
- DQN和AlphaGo系列工作给人留下深刻印象,但是这两种任务本质上其实相对“简单”。因为这些任务的环境是确定的、静态的,状态主要是离散的、静态的、完全可观察的,反馈是确定的,代理也是单一的
- 目前DRL在解决部分可见状态任务(如StarCraft),状态连续的任务(如机械控制任务),动态反馈任务和多代理任务中还没取得令人惊叹的突破
重新审视RL的研究(或不足)(值得研究的方向)
机器学习是个跨学科的研究领域,而RL则是其中跨学科性质非常显著的一个分支。RL理论的发展受到生理学、神经科学和最优控制等领域的启发,现在依旧在很多相关领域被研究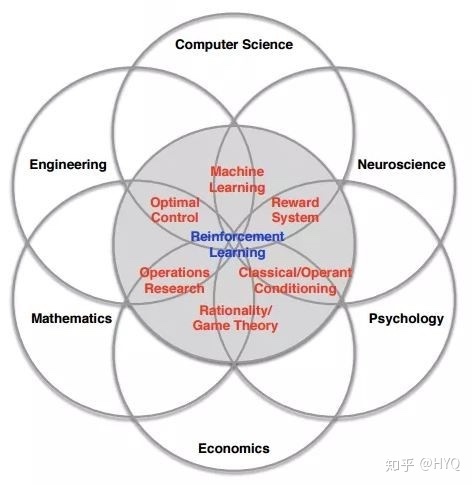
- 基于模型的方法
如上文所述,基于模型的方法不仅能大幅降低采样需求,还可以通过学习任务的动力学模型,为预测学习打下基础 - 提高免模型方法的数据利用率和扩展性
这是免模型学习的两处硬伤,也是Rich Sutton的终极研究目标。这个领域很艰难,但是任何有意义的突破也将带来极大价值 - 更高效的探索策略(Exploration Strategies)
平衡“探索”与“利用”是RL的本质问题,这需要我们设计更加高效的探索策略。除了若干经典的算法如Softmax、ϵ-Greedy[1]、UCB[72]和Thompson Sampling[73]等,近期学界陆续提出了大批新算法,如Intrinsic Motivation [74]、Curiosity-driven Exploration[75]、Count-based Exploration [76]等。其实这些“新”算法的思想不少早在80年代就已出现[77],而与DL的有机结合使它们重新得到重视。此外,OpenAI与DeepMind先后提出通过在策略参数[78]和神经网络权重[79]上引入噪声来提升探索策略, 开辟了一个新方向 - 与模仿学习(Imitation Learning, IL)结合
机器学习与自动驾驶领域最早的成功案例ALVINN[33]就是基于IL;当前RL领域最顶级的学者Pieter Abbeel在跟随Andrew Ng读博士时候,设计的通过IL控制直升机的算法[34]成为IL领域的代表性工作.IL介于RL与监督学习之间,兼具两者的优势,既能更快地得到反馈、更快地收敛,又有推理能力,很有研究价值 - 奖赏塑形(Reward Shaping)
奖赏即反馈,其对RL算法性能的影响是巨大的。- Alexirpan的博文中已经展示了没有精心设计的反馈信号会让RL算法产生多么差的结果
- 设计好的反馈信号一直是RL领域的研究热点
- 近年来涌现出很多基于“好奇心”的RL算法和层级RL算法
- 这两类算法的思路都是在模型训练的过程中插入反馈信号,从而部分地克服了反馈过于稀疏的问题。
- 另一种思路是学习反馈函数,这是逆强化学习(Inverse RL, IRL)的主要方式之一。
- 近些年大火的GAN也是基于这个思路来解决生成建模问题, GAN的提出者Ian Goodfellow也认为GAN就是RL的一种方式 [36]。而将GAN于传统IRL结合的GAIL[37]已经吸引了很多学者的注意
- RL中的迁移学习与多任务学习
当前RL的采样效率极低,而且学到的知识不通用。迁移学习与多任务学习可以有效解决这些问题 - 提升RL的的泛化能力
- 机器学习最重要的目标就是泛化能力, 而现有的RL方法大多在这一指标上表现糟糕[8],无怪乎Jacob Andreas会批评RL的成功是来自“train on the test set”
- 研究者们试图通过学习环境的动力学模型[80]、降低模型复杂度[29]或模型无关学习[81]来提升泛化能力,这也促进了基于模型的方法与元学习(Meta-Learning)方法的发展
- 层级RL(Hierarchical RL, HRL)
- 与序列预测(Sequence Prediction)结合
- Sequence Prediction与RL、IL解决的问题相似又不相同。三者间有很多思想可以互相借鉴
- 免模型方法探索行为的安全性(Safe RL)
- 相比于基于模型的方法,免模型方法缺乏预测能力,这使得其探索行为带有更多不稳定性。一种研究思路是结合贝叶斯方法为RL代理行为的不确定性建模,从而避免过于危险的探索行为
- 关系RL
近期学习客体间关系从而进行推理与预测的“关系学习”受到了学界的广泛关注。关系学习往往在训练中构建的状态链,而中间状态与最终的反馈是脱节的 - 对抗样本RL
- 处理其他模态的输入
重新审视RL的应用
RL只能打游戏、下棋,其他的都做不了?
- 我们不应对RL过于悲观。其实能在视频游戏与棋类游戏中超越人类,已经证明了RL推理能力的强大。通过合理改进后,有希望得到广泛应用
- 控制领域
这是RL思想的发源地之一,也是RL技术应用最成熟的领域。控制领域和机器学习领域各自发展了相似的思想、概念与技术,可以互相借鉴 - 自动驾驶领域
驾驶就是一个序列决策过程,因此天然适合用RL来处理 - NLP领域
相比于计算机视觉领域的任务,NLP领域的很多任务是多轮的,即需通过多次迭代交互来寻求最优解(如对话系统);而且任务的反馈信号往往需要在一系列决策后才能获得(如机器写作)。这样的问题的特性自然适合用RL来解决- 因而近年来RL被应用于NLP领域中的诸多任务中,如文本生成、文本摘要、序列标注、对话机器人(文字/语音)、机器翻译、关系抽取和知识图谱推理等等
- 推荐系统与检索系统领域
RL中的Bandits系列算法早已被广泛应用于商品推荐、新闻推荐和在线广告等领域。近年也有一系列的工作将RL应用于信息检索、排序的任务中 - 金融领域
RL强大的序列决策能力已经被金融系统所关注。无论是华尔街巨头摩根大通还是创业公司如Kensho,都在其交易系统中引入了RL技术 - 对数据的选择
在数据足够多的情况下,如何选择数据来实现“快、好、省”地学习,具有非常大的应用价值 - 通讯、生产调度、规划和资源访问控制等运筹领域
这些领域的任务往往涉及“选择”动作的过程,而且带标签数据难以取得,因此广泛使用RL进行求解
总结
- 虽然有上文列举的诸多成功应用,但我们依旧要认识到,当前RL的发展还处于初级阶段,不能包打天下。目前还没有一个通用的RL解决方案像DL一样成熟到成为一种即插即用的算法。RL算法的输出存在随机性,这是其“探索”哲学带来的本质问题,因此我们不能盲目 All in RL, 也不应该RL in All
广义的RL——从反馈学习
定义与意义
- 本节使用“广义的RL”一词指代针对“从反馈学习”的横跨多个学科的研究。与上文中介绍的来自机器学习、控制论、经济学等领域的RL不同,本节涉及的学科更宽泛,一切涉及从反馈学习的系统,都暂且称为广义的RL
- 行为和反馈是智能形成的基石
- 生成论(Enactivism)认为行为是认知的基础,行为与感知是互相促进的,智能体通过感知获得行为的反馈,而行为则带给智能体对环境的真实有意义的经验[65]。
广义的RL,是未来一切机器学习系统的形式
只要一个机器学习系统会通过接收外部的反馈进行改进,这个系统就不仅仅是一个机器学习系统,而且是一个RL系统。当前在互联网领域广为使用的A/B测试就是RL的一种最简单的形式。而未来的机器学习系统,都要处理分布动态变化的数据并从反馈中学习。因此可以说,我们即将处于一个“一切机器学习都是RL”的时代,学界和工业界都亟需加大对RL的研究力度
广义的RL,是很多领域研究的共同目标
节已经提到RL在机器学习相关的领域被分别发明与研究,其实这种从反馈中学习的思想,在很多其他领域也被不断地研究。仅举几例如下
- 在心理学领域,经典条件反射与操作性条件反射的对比
- 在教育学领域,一直有关于“主动学习”与“被动学习”两种方式的对比与研究
- 在组织行为学领域,学者们探究“主动性人格”与“被动性人格”的不同以及对组织的影响
- 在企业管理学领域,企业的“探索式行为”和“利用式行为”一直是一个研究热点
可以说,一切涉及通过选择然后得到反馈,然后从反馈中学习的领域,几乎都有RL的思想以各种形式存在,因此笔者称之为广义的RL
- 这些学科为RL的发展提供了丰富的研究素材,积累了大量的思想与方法。同时,RL的发展不会仅仅对人工智能领域产生影响,也会推动广义的RL所包含的诸多学科共同前进。
束语
- 虽然RL领域目前还存在诸多待解决的问题,在DRL这一方向上也出现不少泡沫,但我们应该看到RL领域本身在研究和应用领域取得的长足进步
- 这一领域值得持续投入研究,但在应用时需保持理性
- 而对基于反馈的学习的研究,不仅有望实现人工智能的最终目标,也对机器学习领域和诸多其他领域的发展颇有意义
- 这确实是通向人工智能的最佳路径。这条路上布满荆棘,但曙光已现