我的强化学习文章
网络:强化学习算法汇总1
网络:强化学习算法汇总2
不同角度分类
- Model free/Model based
- Mode based:比如基于MDP(马尔科夫处理过程),必须知道很多的环境状态,比如状态转移矩阵,reward等
- Model free:不用知道环境的一些信息
- 基于价值还是基于策略
- 基于价值,比如V(s),Q(s,a)等,只能处理离散的行为,状态。得到最优值,对连续行为不好处理(Q-Learning,Sarsa,DQN及其变种)
- 基于策略,能够解决连续行为状态的场景,比如对状态行为进行建模,能够输出该状态行为的价值数值,所以就可以根据所以行为价值值选择最优的进行迭代(Actor-critic,A3C,DDPG等)
- 只是基于价值的模型(Critic only),只会对整个序列完成后才给reward,对中间好的action损失较多,而基于价值和策略的模型就不会(例如Actor-critic),从Loss函数就能看出来
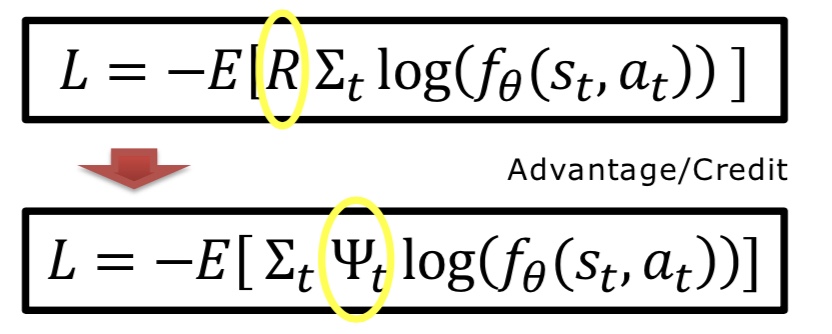
- 是否使用函数近似
- 使用类似神经网络模型逼近V(s),Q(s,a)的真实值,本质就是对参数的求解,一定程度上能够解决连续状态行为的问题
- 迭代更新策略(MC,TD,DP)
- 基于采样的MC,TD,区别是迭代关注到后面的几步问题,实用性讲大部分都是基于TD的
- DP不基于采样,所以状态都需要探索
- 一套架构与否(行为策略和目的策略是否一致)
- 行为策略和目的策略分开,或两套深度学习模型,典型的如Actor-critic
Q-Learning
所属范畴
Model free/基于价值/TD/Off-PolicyQ-Table(状态-行为表)
会有一个状态-行为表,来存储对应的价值,使用的时候只需要查表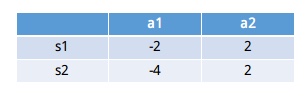
更新Q-Table
- 注意这里是选择s2状态下的最大行为值max $Q(s_2,a)$
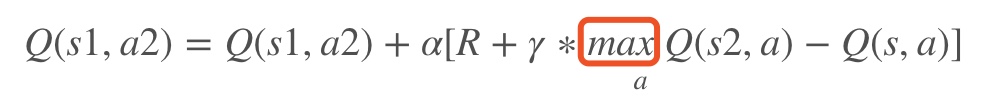
- 注意这里是选择s2状态下的最大行为值max $Q(s_2,a)$
算法伪代码

Sarsa
- 所属范畴
Model free/基于价值/TD and MC(Sarsa($\lambda$))/On-policy 和QLearning区别
Q-learning 在从状态s−>s′的时候,考虑到的为 max Q(s′,a′), 在s′状态中选取 a′时,永远考虑的是最大。而对于Sarsa 而言,在从s′状态中选取 a′时,会采取与从s选取a 的策略一样,即采用 greedy 或者 ϵ−greedy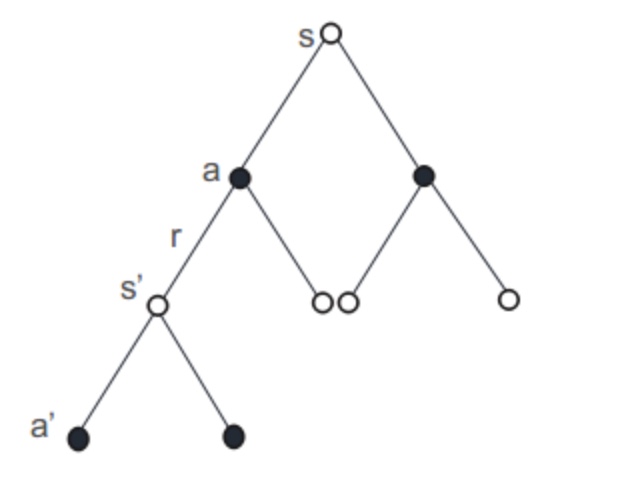

算法伪代码

Sarsa($\lambda$)

DQN
所属范畴
Model free/价值近似函数/TD和QLearning比较
在Q-Learning中,我们提到了用Q表来存储当前状态s1下采取的动作action的值(value,在Q表中也称为Q值)。但是在实际过程中,一个状态s1到下一状态s2,这里的s2可能有很多不同的情况,这将会导致Q表存储的值会很多,不仅占内存,且在搜索的时候也是十分耗时的- 用神经网络来替代行为策略和目的策略
- 输入为状态s和动作a,得到所有的动作值(Q值)
- 只输入状态值,然后输出所有的动作值
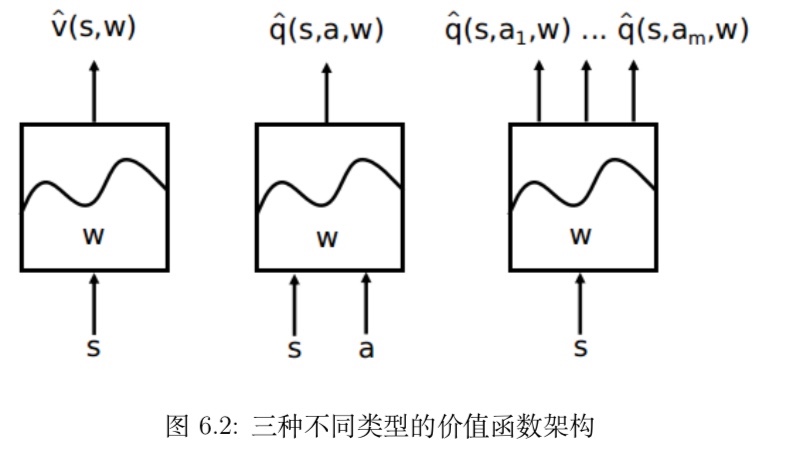
- 用神经网络来替代行为策略和目的策略
伪代码

变种Double DQN, Dueling DQN等
- DDQN
使用借鉴的思路,使用两个架构相同的近似价值函数- 其中一个用来根据策略生成交互行为并随 时频繁参数 (θ)
- 另一个则用来生成目标价值
- DDQN
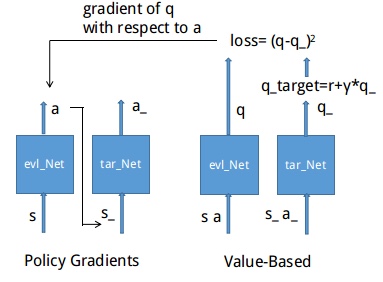
Policy Gradients
- 可以解决连续行为空间的情况
- 强化学习是一个通过奖惩来学习正确行为的机制,有学习奖惩值,根据自己认为的高价值选择行为的,如Q Learning、Deep Q Network 等。也有不通过分析奖励值,直接输出行为的方法,如Policy Gradient。Policy Gradient 直接输出动作的最大好处就是,能够在一个连续区间内挑选动作,而基于值的,往往是在所有动作中计算值,然后选择值最高的那个行为
Actor-Critic
所属范畴
Model free/(基于策略 and 价值/策略近似函数)/TDActor Critic 为类似于Policy Gradient 和 Q-Learning 等以值为基础的算法的组合
- Actor Critic 结合了 Policy Gradient(Actor)和 Function Approximation Critic)。Actor 基于概率选择行为,Critic 基于 Actor 的行为评判行为的得分,Actor 根据 Critic 的评分修改选择行为
- 逻辑
- 其中Actor 类似于Policy Gradient,以状态s为输入,神经网络输出动作actions,并从在这些连续动作中按照一定的概率选取合适的动作action。
- Critic 类似于 Q-Learning 等以值为基础的算法,由于在Actor模块中选择了合适的动作action,通过与环境交互可得到新的状态s_, 奖励r,将状态 s_作为神经网络的输入,得到v_,而原来的状态s通过神经网络输出后得到v。
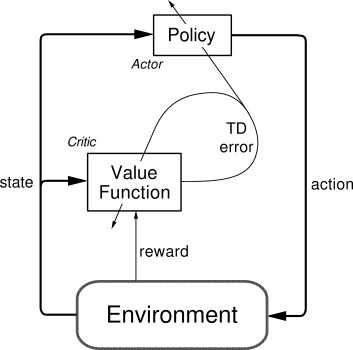
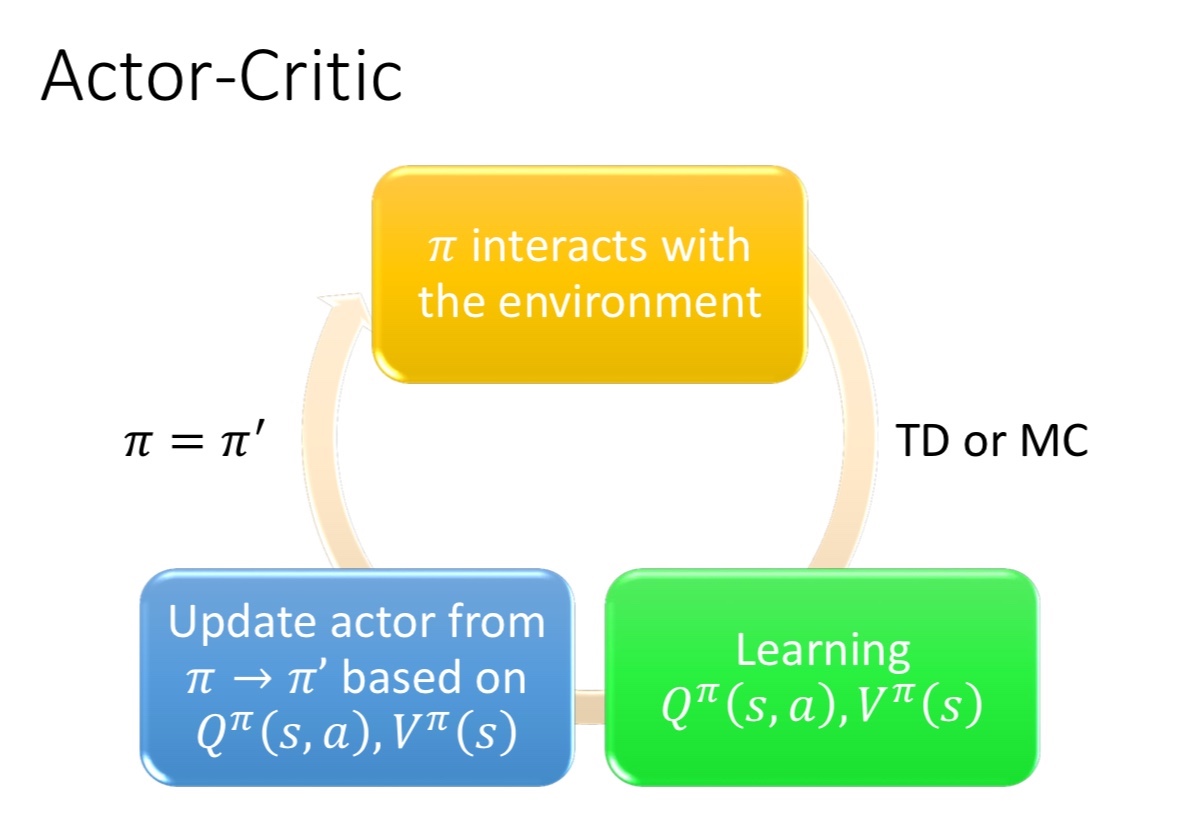
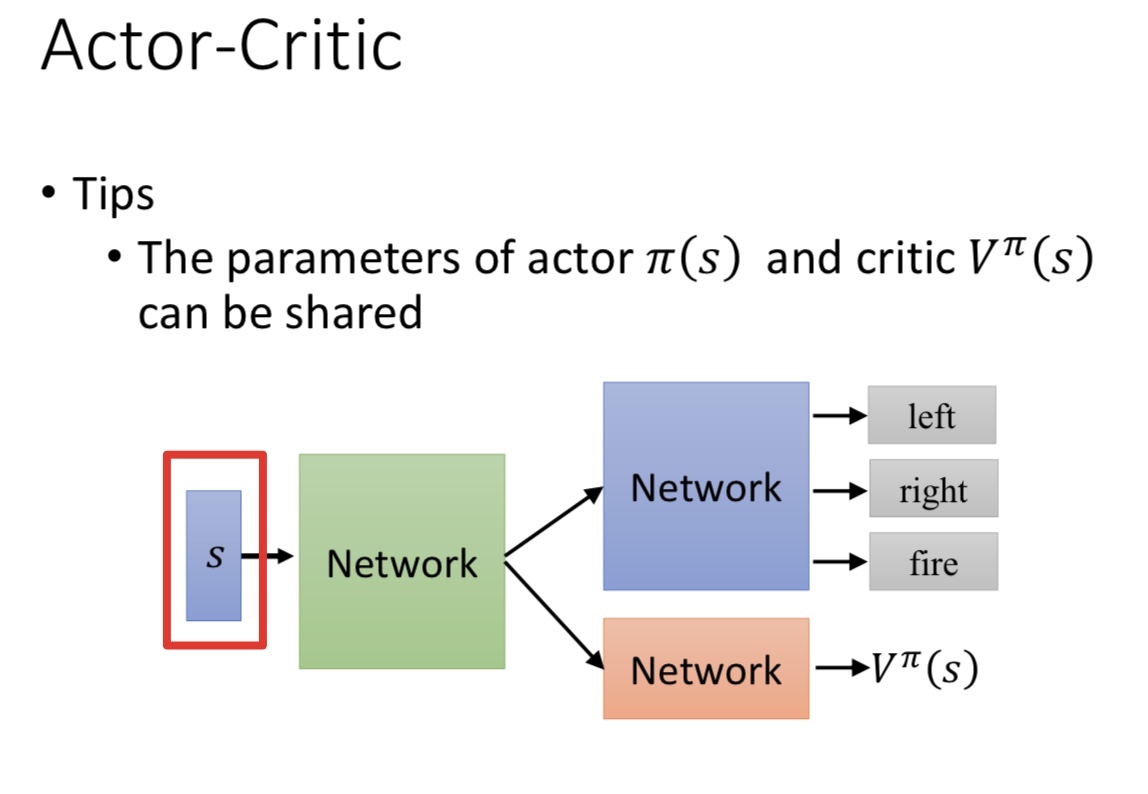
- QAC算法(最基本的基于行为价值 Q 的 Actor-Critic 算法)

A3C
- 所属范畴
Model free/(基于策略 and 价值/策略近似函数)/TD - A3C 其实采用了Actor-Critic 的形式,但是引入了并行计算的概念。为了训练一对Actor 和 Critic,我们将Actor 和 Critic 复制成多份,然后放在不同的核中进行训练。其中需要声明一个主要的Actor-Critic (global),不断从多个副本中更新的参数进行学习,获得新的参数,同时副本中的参数也不断从 Actor-Critic (global) 中获得并更新。
- A3C 是Google DeepMind 提出的一种解决 Actor Critic 不收敛问题的算法。A3C会创建多个并行的环境,让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数。并行中的 agent 们互不干扰,而主结构的参数更新受到副结构提交更新的不连续性干扰,所以更新的相关性被降低,收敛性提高

DDPG(Deep Deterministic Policy Gradient)
- 所属范畴
Model free/(基于策略 and 价值/策略近似函数)/TD - DDPG算法能较为稳定地解决连续行为空间下强化学习问题
- DDPG用到的神经网络是怎么样的?它其实有点类似于Actor-Critic,也需要有基于策略Policy 的神经网络 和 基于价值 Value 的神经网络,但是为了体现DQN的思想,每种神经网络我们都需要再细分成俩个。Policy Gradient 这边有估计网络和现实网络,估计网络用来输出实时的动作,而现实网络则是用来更新价值网络系统的。再看看价值系统这边,我们也有现实网络和估计网络,他们都在输出这个状态的价值,而输入端却有不同,状态现实网络这边会拿着当时actor施加的动作当做输入。在实际运用中,DDPG的这种做法的确带来了更有效的学习过程
- 噪音函数
- 该算法在学习阶段通过在确定性的行为基础上增加一个噪声函数而实现在确定性行为周围的小范围内探索
- 该算法还为 Actor 和 Critic 网络各备份了一套参数用来计算行为价值的期待值以更稳定地提升 Critic 的策略指导水平。使用备份参数的网络称为目标网络,其对应的参数每次更新的幅度很小
- 伪代码
