推荐系统应用方向
个性化推荐,相关推荐,热门推荐。。。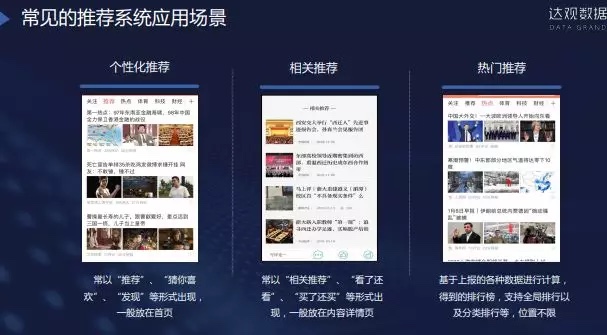
推荐系统设计目标
- 功能:功能上要全面些,包括相关推荐、个性化推荐、热门推荐等还包括混合推荐
- 效果:效果在不同领域有差异,如在直播领域关注送礼物、打赏收入等,而资讯行业较关注人均点击数量、用户停留时长等;
- 性能:性能在不同领域也是有差异的,但是必须是快速、稳定的,不允许出现推荐位置的留白,也就是你的推荐系统可以效果不好但是不能空白,在高并发时要求性能稳定快速。其实在实际业务场景中这三者是相互影响,权衡利弊的

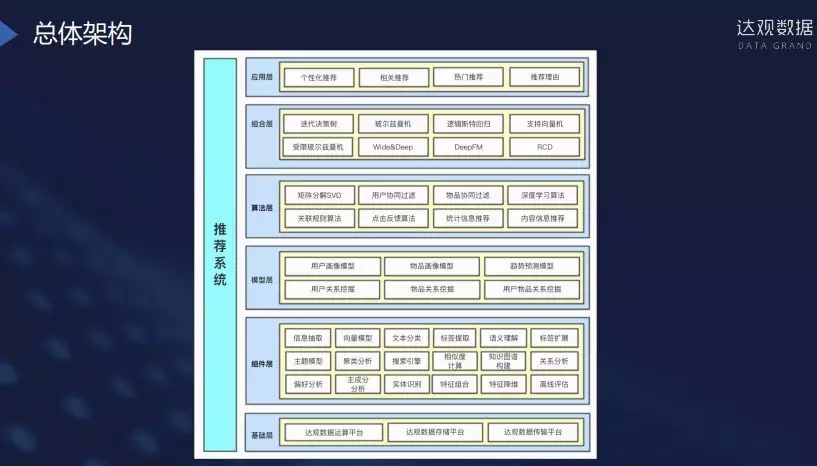
系统层次图
- 基础层,对于服务多家客户来说首先是基础运算平台,全部基于Hadoop和Spark。基础存储平台是基于HBase、MySQL、Redis、HDFS等,传输平台是DgIO,主要基于消息队列的方式。
- 在组件层有各种各样的组件和算法库,实现多个产品服务都可以复用。对于这些组件也有相应的研发团队进行升级和维护,如文本分类、标签、语义理解都是由文本组处理,对于搜索引擎性能、相关性等的优化升级是由搜索组完成,组件都是共同使用共同维护。
- 组件层有一系列小的组件,基于组件可以做一些模型层的事情,比如推荐相关的做用户画像,因为对于不同行业的用户画像有不同的标准,我们拿到的就是用户id和行为数据,刻画用户画像主要基于向量方式。物品画像主要解决流向,就是物品来了如何及时曝光,这时就需要依据其初始信息进行预估打分,对于已经曝光的物品会记录一段时间的收益情况(点击率、收藏数据等)形成物品画像做一些过滤信息。趋势分析主要是物品曝光后接下来是怎么样的,用户关系主要是基于用户行为分析的,主要做社交关系的推荐。物品关系主要是做算法方面的处理。
- 算法层主要是包括基于内容的推荐、矩阵分解、协同过滤、深度学习等。基于内容推荐如标签召回、热门召回、内容召回,深度学习各行业都在使用。
- 组合层,对各种单一推荐算法的召回结果,使用机器学习的方式进行融合,以达到推荐效果的最优化。
- 应用层,目前提供三种推荐,同时还有推荐理由,就是可解释性
整体架构
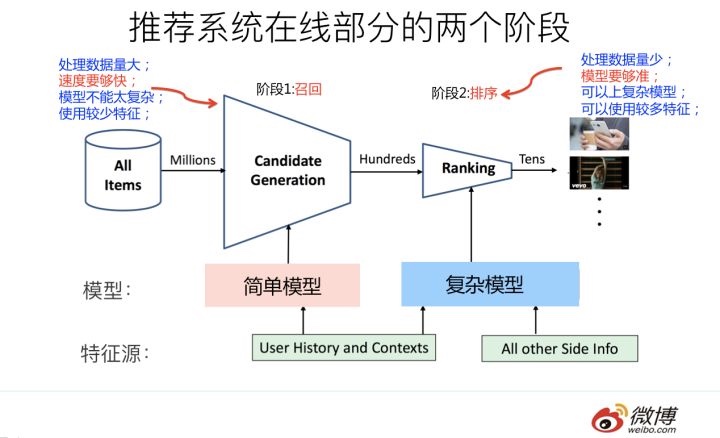
- 在线部分
- 召回:通过召回环节,将给用户推荐的物品降到千以下规模
- 粗排:如果召回阶段返回的物品还是太多,可以加入粗排阶段,这个阶段是可选的,粗排可以通过一些简单排序模型进一步减少往后续环节传递的物品
- 精排:使用复杂的模型来对少量物品精准排序
- 其他逻辑:即使精排推荐结果出来了,一般并不会直接展示给用户,可能还要上一些业务策略,比如去已读,推荐多样化,加入广告等各种业务策略。之后形成最终推荐结果,将结果展示给用户
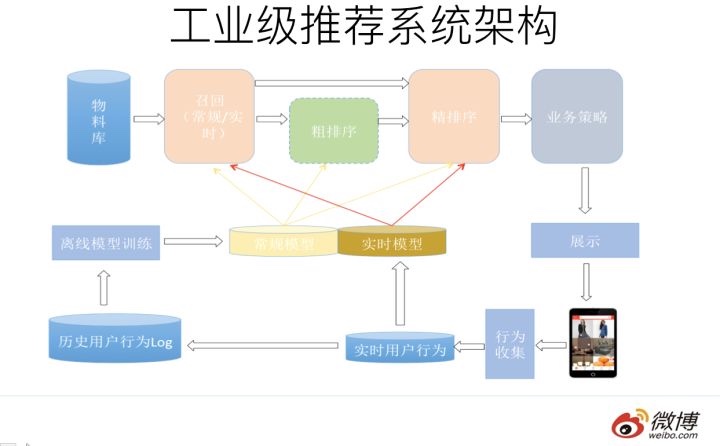
- 近线部分
主要目的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地更新在线推荐模型。这样做的好处是用户的最新兴趣能够近乎实时地体现到推荐结果里 - 离线部分
通过对线上用户点击日志的存储和清理,整理离线训练数据,并周期性地更新推荐模型。对于超大规模数据和机器学习模型来说,往往需要高效地分布式机器学习平台来对离线训练进行支持

- GP应用推荐举例
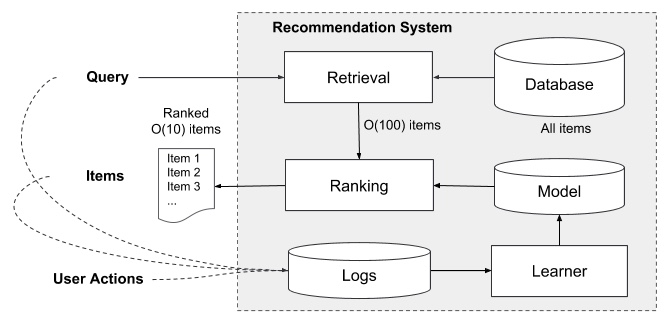
在线部分
- 召回阶段
将物料从千万级别,降低到百级别