直方图
- 和xgboost的pre-order比较
xgboost 采用了预排序的方法来处理节点分裂,这样计算的分裂点比较精确。但是,时间空间上都造成了很大的时间开销(但这个也是当时相比GBDT的重要提升点)。为了解决这个问题,Lightgbm 选择了基于 histogram 的决策树算法。相比于 pre-sorted算法,histogram 在内存消耗和计算代价上都有不少优势 - LightGBM和最近的FastBDT都采取了提前histogram binning再在bin好的数据上面进行搜索。并在pre-bin之后的histogram的求和用了一个非常巧妙的减法trick(histogram加速),省了一半的时间
leaf-wise替代level-wise
在 histogram 算法之上, LightGBM 进行进一步的优化。首先它抛弃了大多数 GBDT 工具使用的按层生长
(level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法
在 histogram 算法之上, LightGBM 进行进一步的优化。首先它抛弃了大多数 GBDT 工具使用的按层生长(level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。 level-wise 过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,不容易过拟合。但实际上level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销。因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
- leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环
- 因此同 level-wise 相比,在分裂次数相同的情况下,leaf-wise 可以降低更多的误差,得到更好的精度。
- leaf-wise 的缺点是可能会长出比较深的决策树,产生过拟合。因此 LightGBM 在leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合
Level wise方式:
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂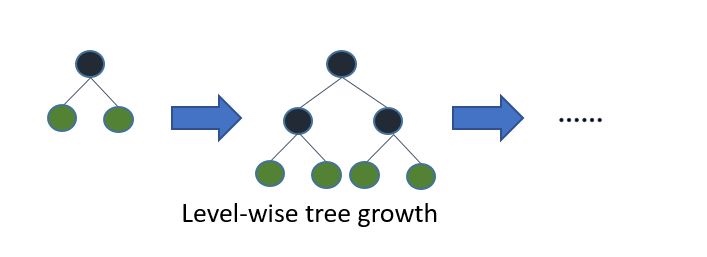
Leaf wise方式:
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。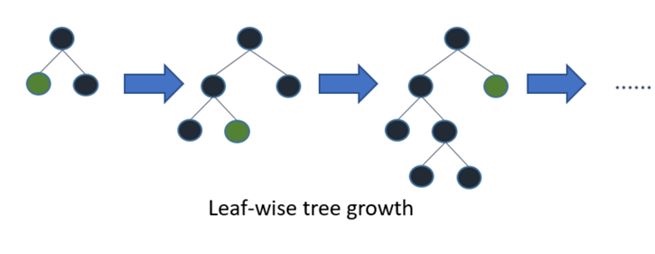
Gradient-based One-Side Sampling(GOSS)
在机器学习当中,我们面对大数据量时候都会使用采样的方式(根据样本权值)来提高训练速度。又或者在训练的时候赋予样本权值来关于于某一类样本(如Adaboost)。LightGBM利用了GOSS来做采样算法。
- 选取前a%个较大梯度的值作为大梯度值的训练样本
- 从剩余的1 - a%个较小梯度的值中,我们随机选取其中的b%个作为小梯度值的训练样本
- 对于较小梯度的样本,也就是b% * #samples,我们在计算信息增益时将其放大(1 - a) / b倍
总的来说就是a% #samples + b% #samples个样本作为训练样本。 而这样的构造是为了尽可能保持与总的数据分布一致,并且保证小梯度值的样本得到训练。
Exclusive Feature Bundling(EFB)
EFB中文名叫独立特征合并,顾名思义它就是将若干个特征合并在一起。使用这个算法的原因是因为我们要解决数据稀疏的问题。在很多时候,数据通常都是几千万维的稀疏数据。因此我们对不同维度的数据合并一齐使得一个稀疏矩阵变成一个稠密矩阵