参考文章:
王者对决:XLNet对比Bert
3分钟了解GPT Bert与XLNet的差异
张俊林-运行机制及和 Bert 的异同比较
自回归语言模型
- 概念
在 ELMO / BERT 出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的 LM 被称为自回归语言模型- ELMO本质上也是自回归LM
- ELMO 尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归 LM ,这个跟模型具体怎么实现有关系。
- ELMO 是做了两个方向 ( 从左到右以及从右到左两个方向的语言模型 ) ,但是是分别有两个方向的自回归 LM ,然后把 LSTM 的两个方向的隐节点状态拼接到一起,来体现双向语言模型这个事情的。所以其实是两个自回归语言模型的拼接,本质上仍然是自回归语言模型
- ELMO本质上也是自回归LM
- 缺点
自回归语言模型的问题在于它只能使用前向上下文或后向上下文,这意味着它不能同时使用前向和后向上下文,从而限制其对上下文和预测的理解。- 当然,貌似 ELMO 这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好
自编码语言模型
与AR语言模型不同,BERT使用自动编码器(AE)语言模型。AE语言模型旨在从损坏的输入重建原始数据。
在BERT中,通过添加[MASK]来破坏预训练输入数据。例如,’Goa has the most beautiful beaches in India’将成为‘Goa has the most beautiful [MASK] in India’,该模型的目标是根据上下文词预测[MASK]词。自动编码器语言模型的优点是,它可以看到前向和后向的上下文。但是,由于在输入数据中添加[MASK]引入了微调模型的差异
bert的问题
- [MASK]标记导致实际和预训练不一致
训练BERT以预测用特殊[MASK]标记替换的标记。问题是在下游任务中微调BERT时,[MASK]标记永远不会出现。在大多数情况下,BERT只是将非掩码标记复制到输出中。 - 预测的标记彼此独立
Bert 在第一个预训练阶段,假设句子中多个单词被 Mask 掉,这些被 Mask 掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet 则考虑了这种关系- 例如:
Whenever she goes to the [MASK] [MASK] she buys a lot of [MASK]
三个[MASK]是并行训练,它们三个直接的关系bert是没有考虑的
- 例如:
XLNet
- 背景:
能不能结合自编码(bert)从左向右学习,和自回归模型(elmo)能够同时学习上下文,也能够避免bert的缺陷呢? - 排列语言建模思想:
看上去仍然是个自回归的从左到右的语言模型,但是其实通过对句子中单词排列组合,把一部分 Ti 下文的单词排到 Ti 的上文位置中,于是,就看到了上文和下文,但是形式上看上去仍然是从左到右在预测后一个单词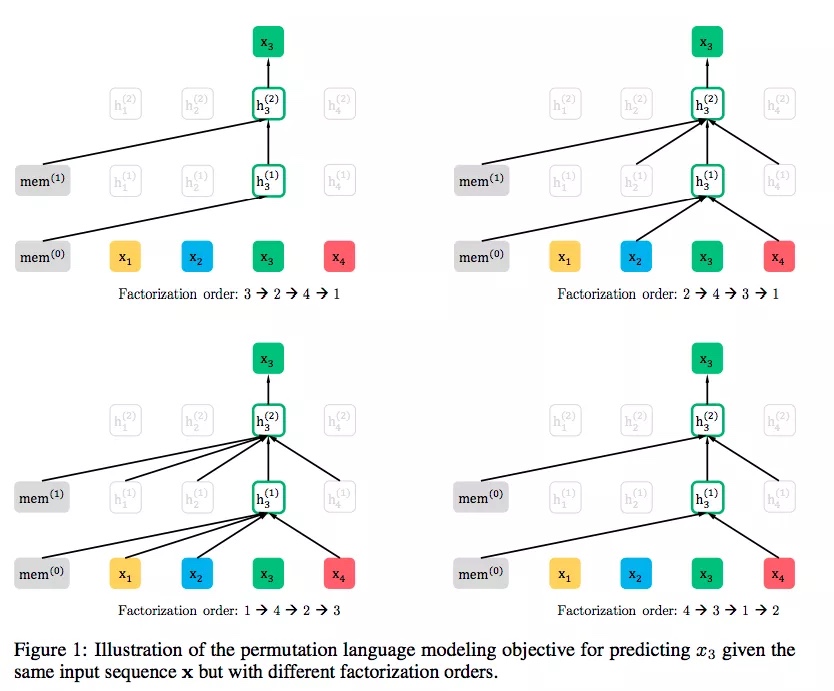
- 这样从左往右也能看见原始Ti的上下文了