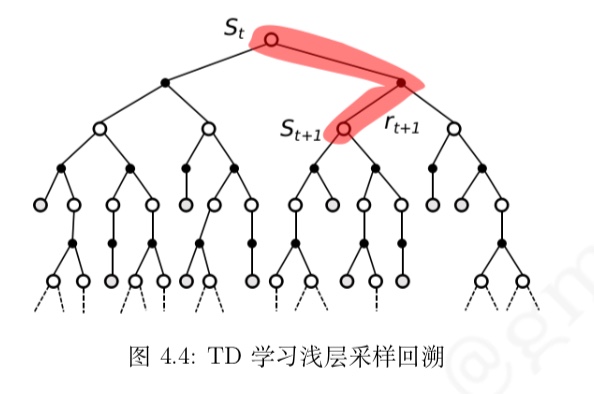
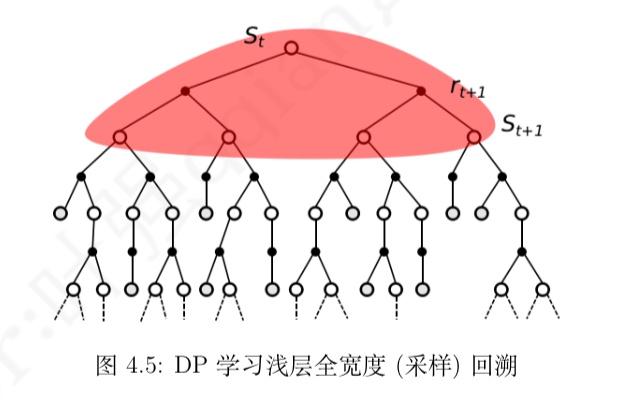
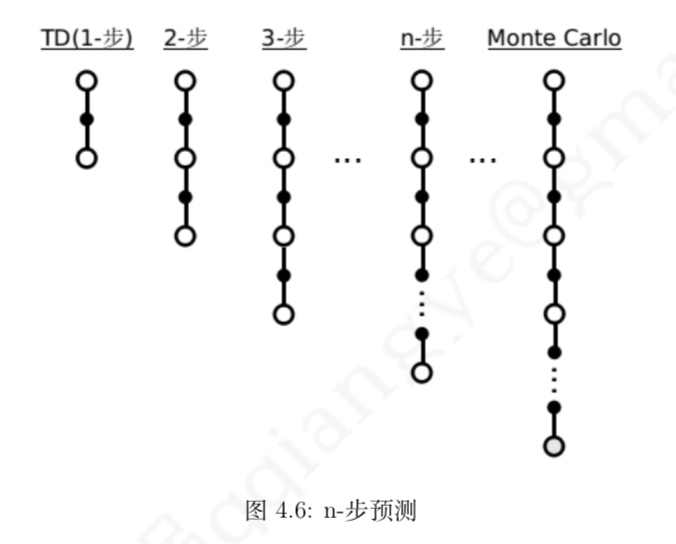
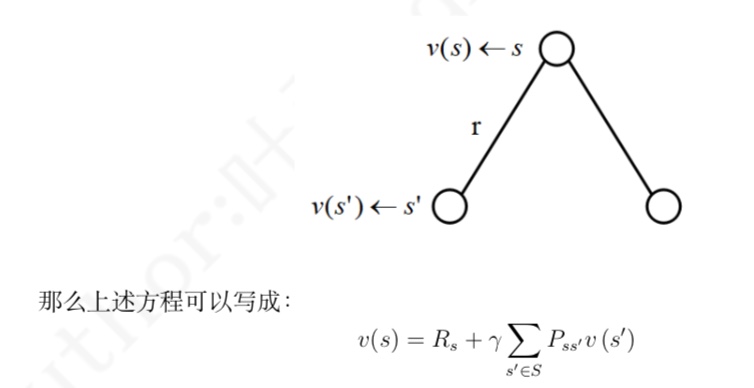
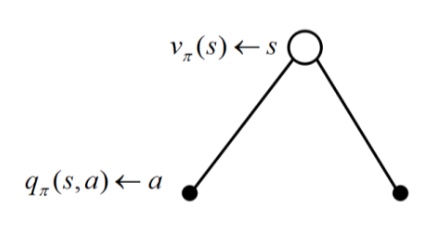
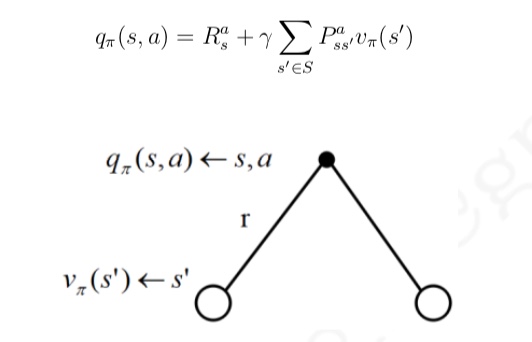
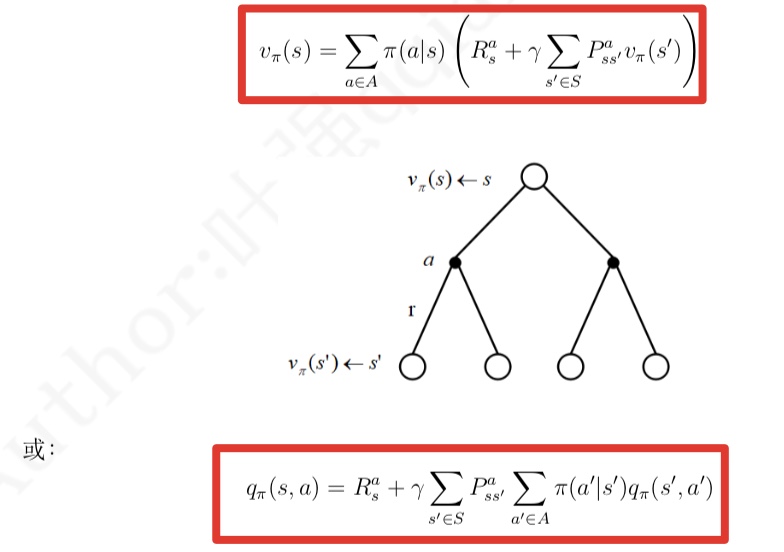
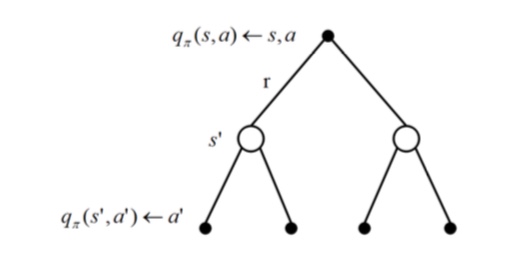
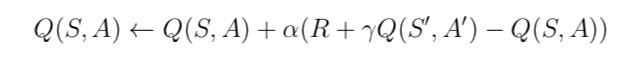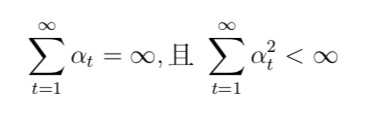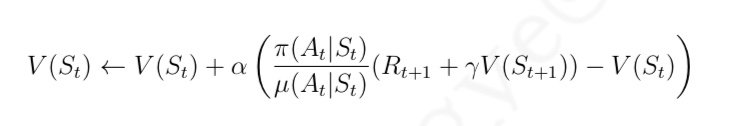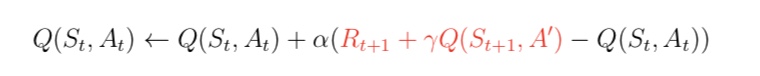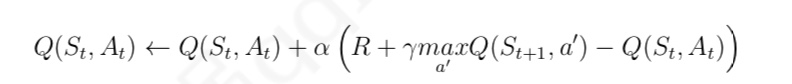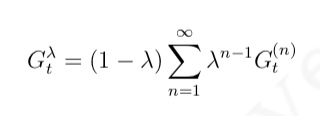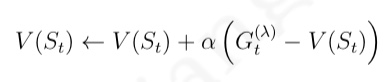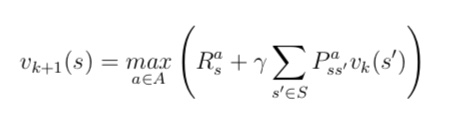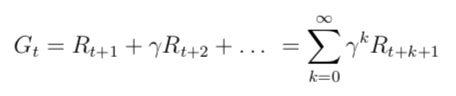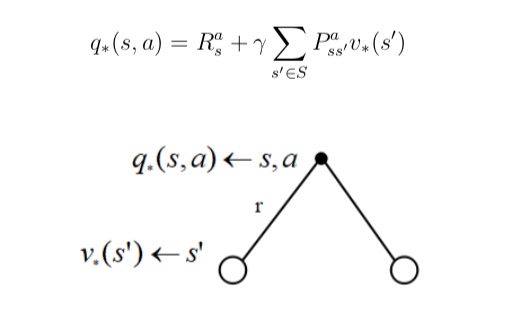什么是相似信息的推荐模型
- 定义
相似信息的推荐模型又叫“临近”(Neighborhood)模型。顾名思义,就是我们希望利用临近、或者相似的数据点来为用户推荐。 - 协同过滤
临近模型的内在假设是推荐系统中著名的“协同过滤”(Collaborative Filtering)- 相似的用户可能会有相似的喜好,相似的物品可能会被相似的人所偏好。
- 于是,如果我们能够定义怎么寻找相似的用户或者相似的物品,那么我们就可以利用这些类别的人群或者物品来给用户进行推荐。
- 举例
A,B都看了战狼2,B还看了红海,那么就给A推荐红海
思考过程:- 第一,联系用户 A 和用户 B 的是他们都看过《战狼 2》。这就帮助我们定义了 A 和 B 是相似用户
- 第二,我们的假定是,相似的用户有相似的观影偏好,于是我们就直接把 B 的另外一个观看过的电影《红海行动》拿来推荐给了 A
- 意义:
- 这两个步骤其实就很好地解释了“协同过滤”中“协同”的概念,意思就是相似的用户互相协同,互相过滤信息
- “协同过滤”从统计模型的意义上来讲,其实就是“借用数据”,在数据稀缺的情况下帮助建模。掌握这个思路是非常重要的建模手段
- 在用户 A 数据不足的情况下,我们挖掘到可以借鉴用户 B 的数据
- 因此,我们其实是把用户 A 和用户 B“聚类”到了一起,认为他们代表了一个类型的用户。
- 当我们把对单个用户的建模抽象上升到某一个类型的用户的时候,这就把更多的数据放到了一起
基于相似用户的协同过滤
如何才能够比较系统地定义这样的流程呢?
- 首先,问题被抽象为我们需要估计用户 I 针对一个没有“触碰过”(这里指点击、购买、或者评分等行为)的物品 J 的偏好
- 第一步,我们需要构建一个用户集合,这个用户集合得满足两个标准:
- 第一,这些用户需要已经触碰过物品 J,这是与用户 I 的一大区别;
- 第二,这些用户在其他的行为方面需要与用户 I 类似
- 然后进行打分
- 简单的做法
首先,我们已经得到了所有和 I 相似的用户对 J 的打分。那么,一种办法就是,直接用这些打分的平均值来预估 J 的评分。也就是说,如果我们认为这个相似集合都是和用户 I 相似的用户,那么他们对 J 的偏好,我们就认为是 I 的偏好。显然这是一个很粗糙的做法 - 改进方法
- 采用加权平均的做法
也就是说,和用户 I 越相似的用户,我们越倚重这些人对 J 的偏好 - 我们也需要对整个评分进行一个修正
- 虽然这个相似集合的人都对 J 进行过触碰,但是每个人的喜好毕竟还是不一样的。比如有的用户可能习惯性地会对很多物品有很强的偏好。因此,仅仅是借鉴每个人的偏好,而忽略了这些用户的偏差,这显然是不够的。所以,我们需要对这些评分做这样的修正,那就是减去这些相似用户对所有东西的平均打分,也就是说,我们需要把这些用户本人的偏差给去除掉
- 采用加权平均的做法
- 简单的做法
- 方法总结:
综合刚才说的两个因素,可以得到一个更加合适的打分算法,那就是,用户 I 对物品 J 的打分来自两个部分:- 一部分是 I 的平均打分
- 另外一部分是 I 对于 J 的一个在平均打分之上的补充打分
- 这个补充打分来自于刚才我们建立的相似用户集,是这个相似用户集里每个用户对于 J 的补充打分的一个加权平均
- 权重依赖于这个用户和 I 的相似度
- 每个用户对于 J 的补充打分是他们对于 J 的直接打分减去他们自己的平均打分
- 这个补充打分来自于刚才我们建立的相似用户集,是这个相似用户集里每个用户对于 J 的补充打分的一个加权平均
- 第一步,我们需要构建一个用户集合,这个用户集合得满足两个标准:
相似信息的构建
几个关键要素:
- 我们怎么来定义两个用户是相似的
- 一种最简单的办法,就是计算两个用户对于他们都偏好物品的“皮尔森相关度”(Pearson Correlation)
- 皮尔森相关度是针对每一个“两个用户”都同时偏好过的物品,看他们的偏好是否相似,这里的相似是用乘积的形式出现的。当两个偏好的值都比较大的时候,乘积也就比较大
- 设定一些“阈值”来筛选刚才所说的相关用户集合
- 我们可以设置最多达到前 K 个相似用户(比如 K 等于 100 或者 200)
- 加权平均里面的权重问题
- 一种权重,就是直接使用两个用户的相似度,也就是我们刚计算的皮尔森相关度
- 当然,这里有一个问题,如果直接使用,我们可能会过分“相信”有一些相关度高但自身数据也不多的用户
- 所以我们可以把皮尔森相关度乘以一个系数,这个系数是根据自身的偏好数量来定的
- 一种权重,就是直接使用两个用户的相似度,也就是我们刚计算的皮尔森相关度
总结
- 协同过滤
相似的用户可能会有相似的喜好,相似的物品可能会被相似的人所偏好 - 基于相似用户协同过滤
- 问题被抽象为我们需要估计用户 I 针对一个没有“触碰过”(这里指点击、购买、或者评分等行为)的物品 J 的偏好
- 假设已经构建了这样的用户组,然后就是对需要推荐的物品进行打分,有分为简单的平均打分,和加权打分等
- 相似信息的构建(皮尔森相似度,设置阈值构建用户集合)

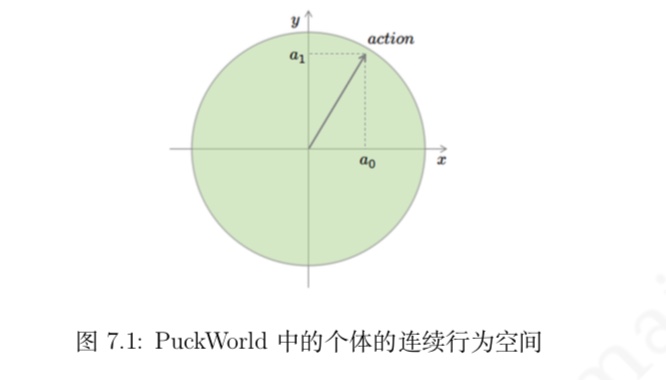
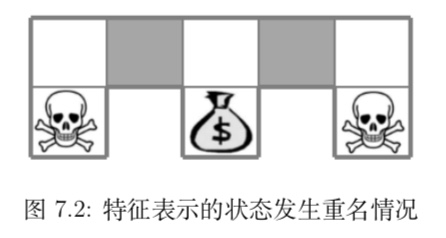
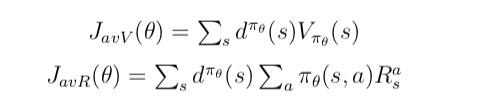

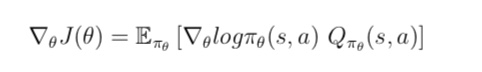
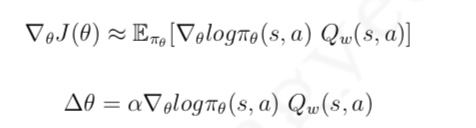




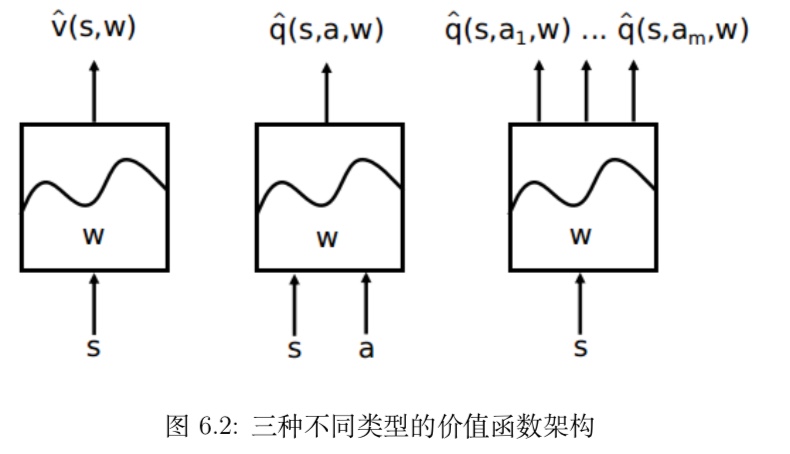
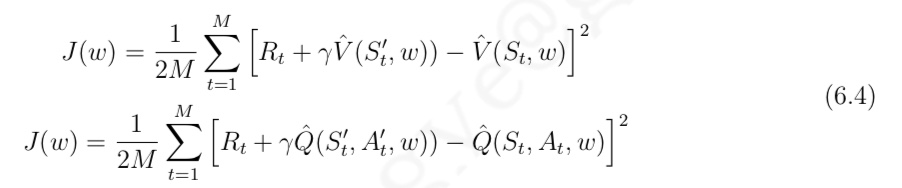

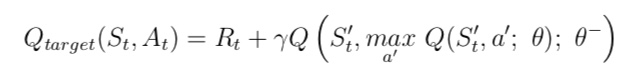

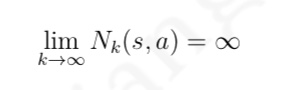
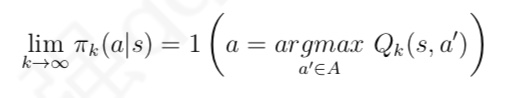
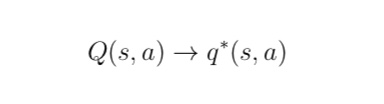
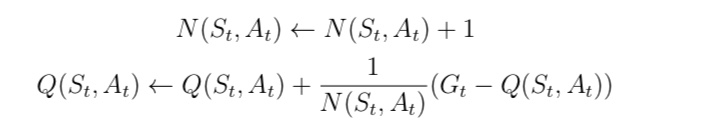
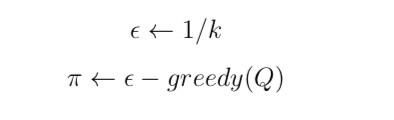
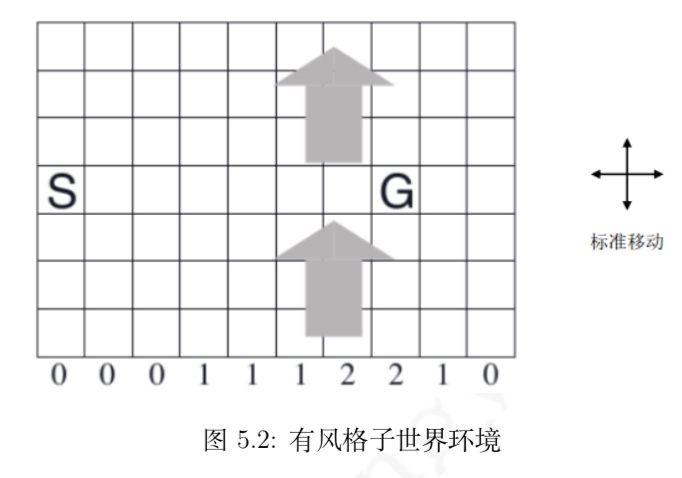
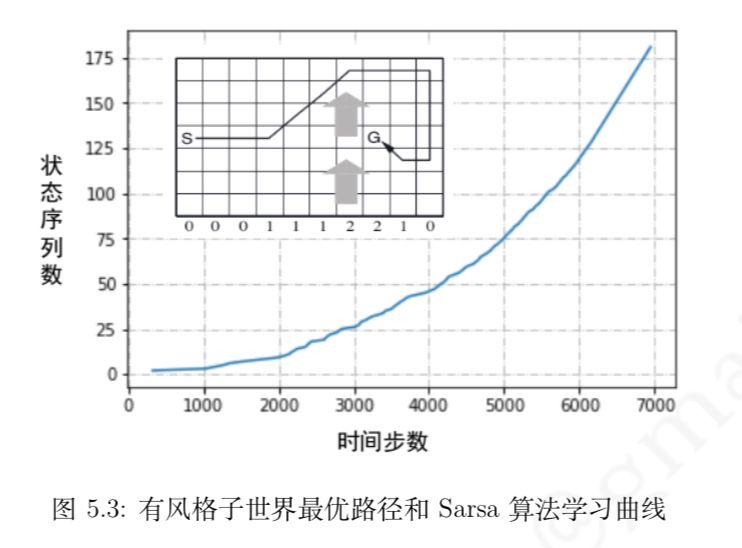
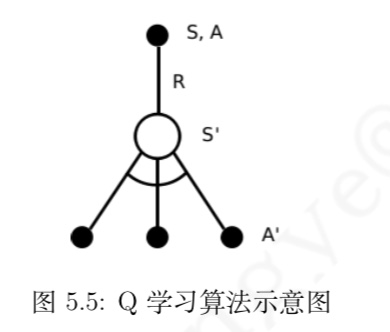
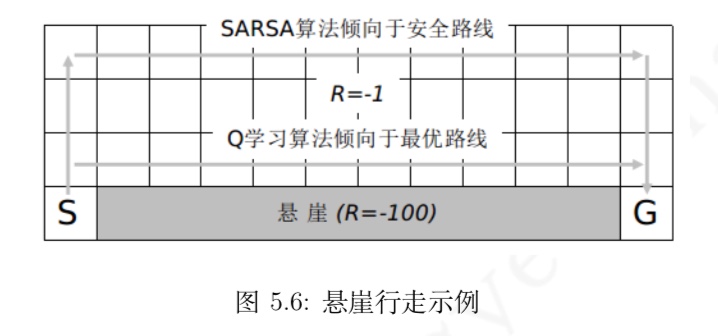
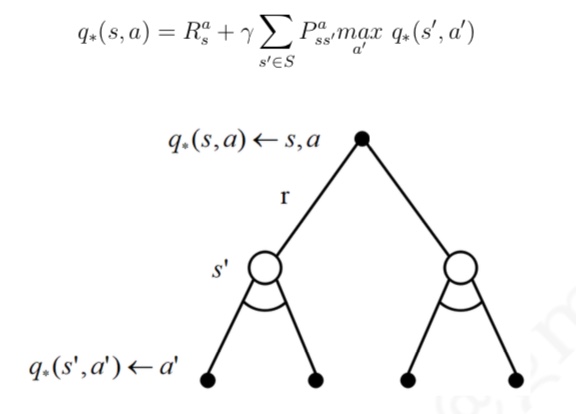
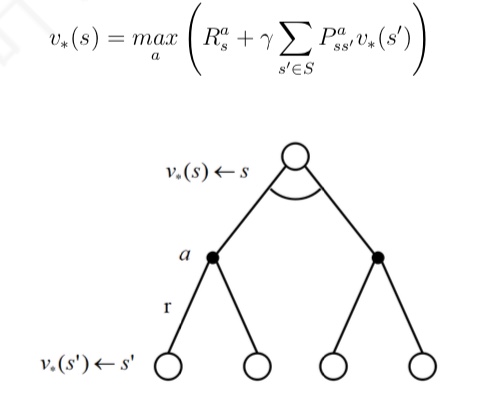
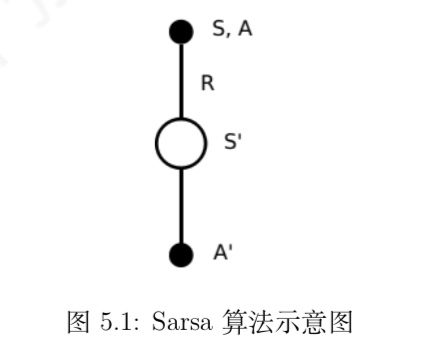 与 MC 算法不同的是,Sarsa 算法在单个状态序列内的每一个时间步,在状态 S 下采取一个 行为 A 到达状态 S’ 后都要更新状态行为对 (S,A) 的价值 Q(S,A)。这一过程同样使用 ε-贪婪策略进行策略迭代:
与 MC 算法不同的是,Sarsa 算法在单个状态序列内的每一个时间步,在状态 S 下采取一个 行为 A 到达状态 S’ 后都要更新状态行为对 (S,A) 的价值 Q(S,A)。这一过程同样使用 ε-贪婪策略进行策略迭代: