[习题练习]
Building+a+Recurrent+Neural+Network+-+Step+by+Step,主要讲是一步一步构建RNN基础网络和LSTM网络,理解运作原
dinosaurus-island(character-level language model,练习使用基础RNN模型或者LSTM模型,学习一些文本,然后生成新的文)
Improvise-music with an LSTM network,主要使用LSTM网络生成音
循环神经网络基础
RNN背景
- 什么是序列问题?
比如语音识别,输入是一段音频,要求输出是一段文字Y。或者情感分析,输入评论,要求输出几颗星等。本质输入都是一段序列内容,其实就是X->Y的映射问题 - 序列问题特点?
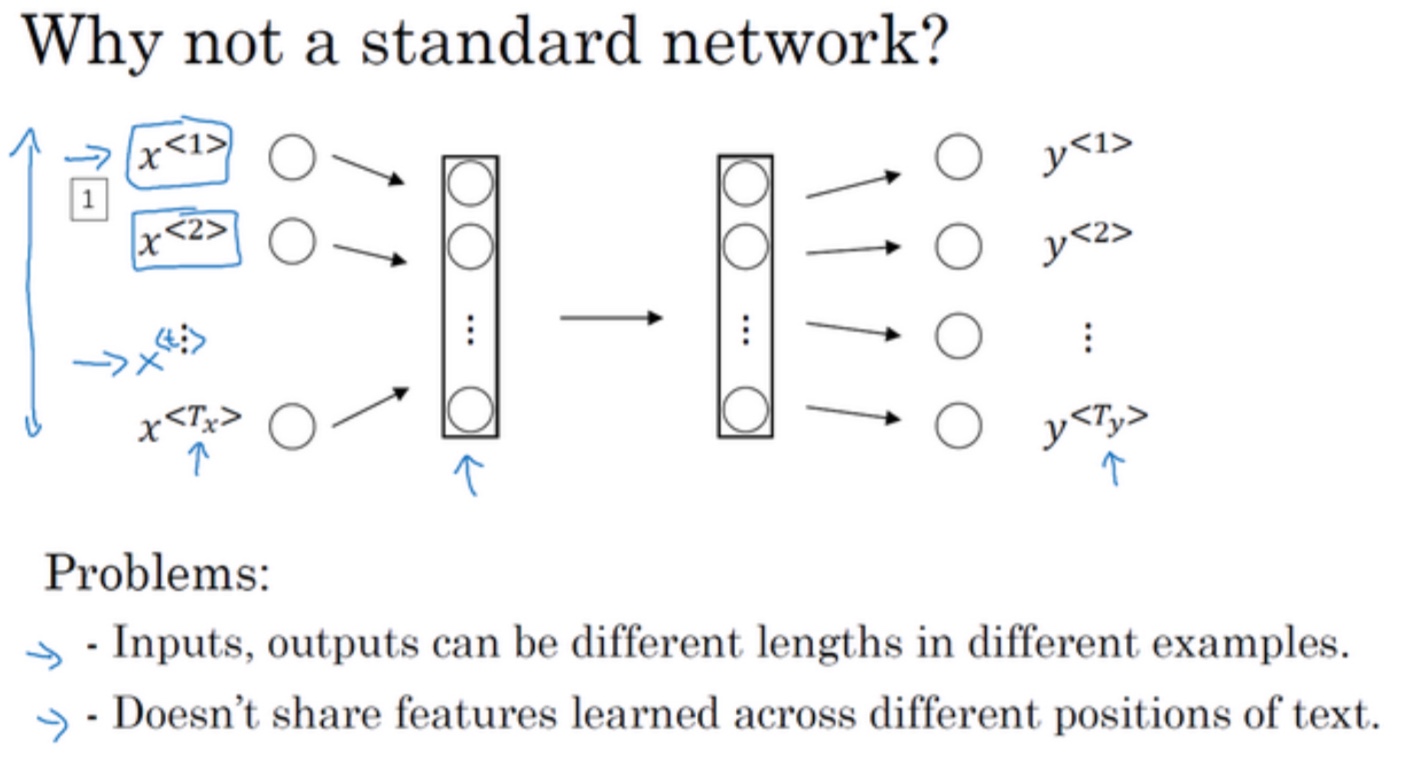
可以看见,有些序列问题X,Y长度一致,有些不一致… - 为什么不用标准神经网络处理序列问题:
- 输入输出不定长
- 序列上一些位置已经学到的文本信息内容不能在其他位置共享
- 比如如果神经网络已经学习到了在位置 1 出现的 Harry 可能是人名的一部分,那么如果 Harry 出现在其他位置,比如$x^{< t >}$时,它也能够自动识别其为人名的一部分的话,这就很棒了。这可能类似于你在卷积神经网络中看到的,你希望将部分图片里学到的内容快速推广到图片的其他部分,而我们希望对序列数据也有相似的效果。和你在卷积网络中学到的类似,用一个更好的表达方式也能够让你减少模型中参数的数量
- RNN传递一个激活值到下一个时间步中进行计算,所以能够解决这个问题,适用于序列问题
- 注意项:
- $a^{<0>}$通常使用零向量作为零时刻的伪激活值
- 注意多种不同的参数$W_{ax},W_{aa},W_{ya}$

前向后向计算
- RNN cell
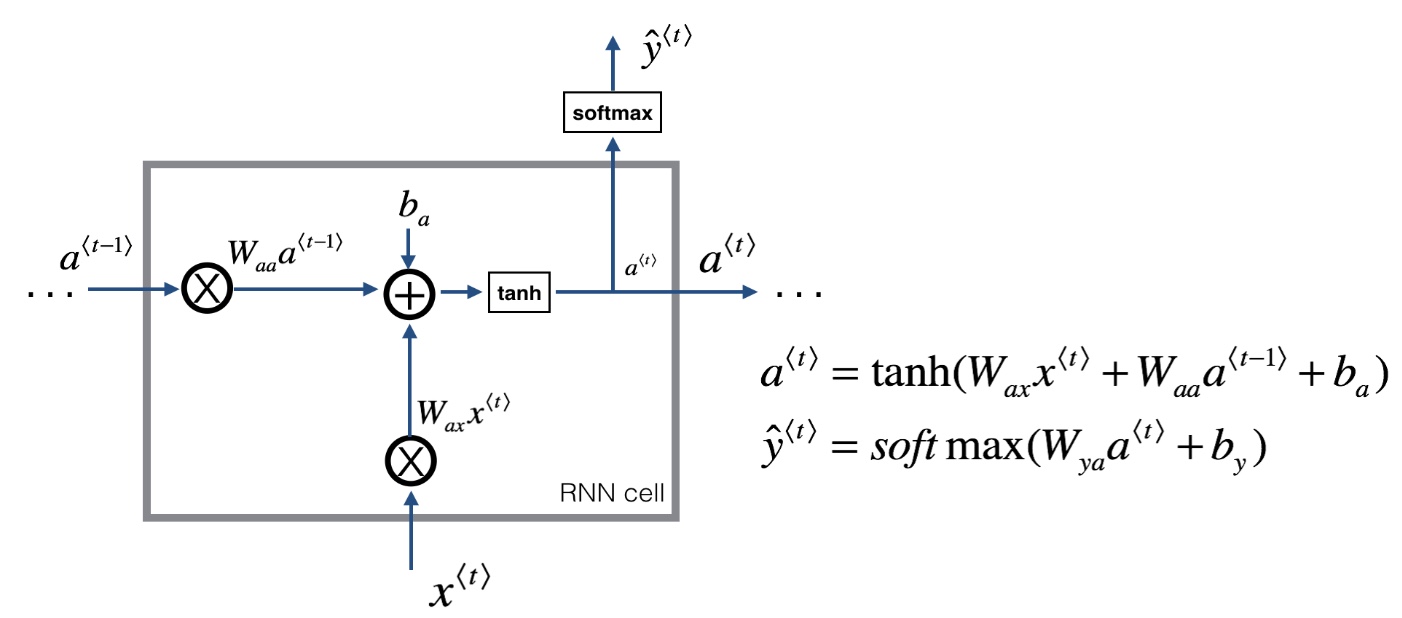
前向传播
- t时刻:
$a^{< t >}=g_1(W_{aa}a^{t-1} + W_{ax}x^{t} + b_a)$
$\hat y^{t} = g_2(W_{ya}a^{< t >} + b_y)$ - 激活函数通常使用tanh,y输出激活函数视情况而定
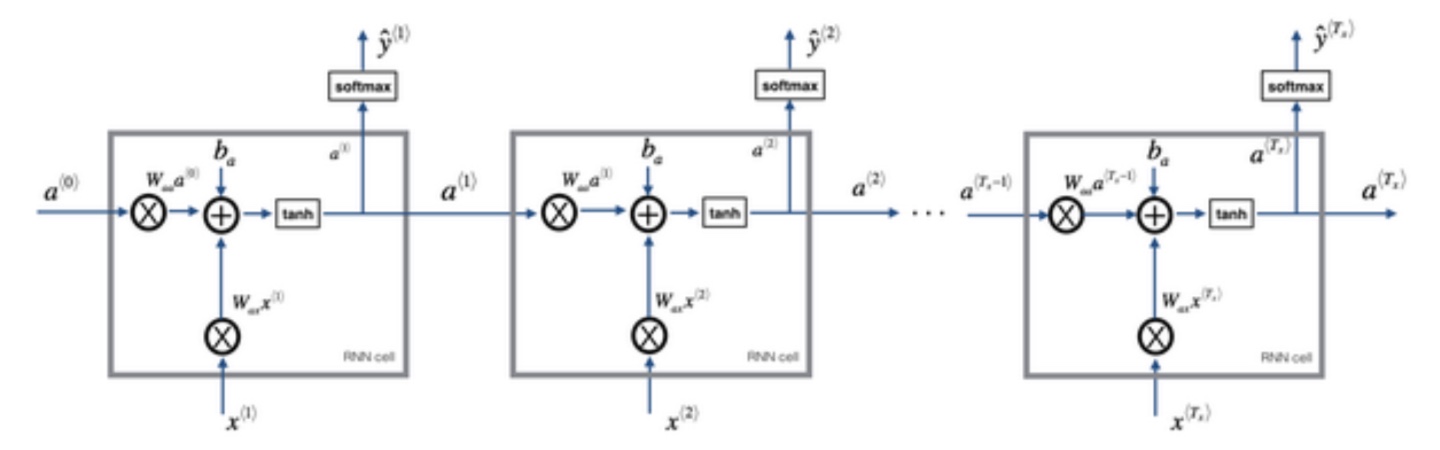
- t时刻:
后向传播
- 对于一个元素的损失函数:
$L^{< t >}(\hat y^{< t >},y^{t}) = -y^{< t >}log\hat y^{< t >} - (1-y^{< t >})log(1-\hat y^{< t >})$ - 整体序列的损失函数,就是将各时间步的损失值函数相加
$L(\hat y,y) = \sum_{t-1}^{T_x}L^{< t >}(\hat y^{< t >},y^{t})$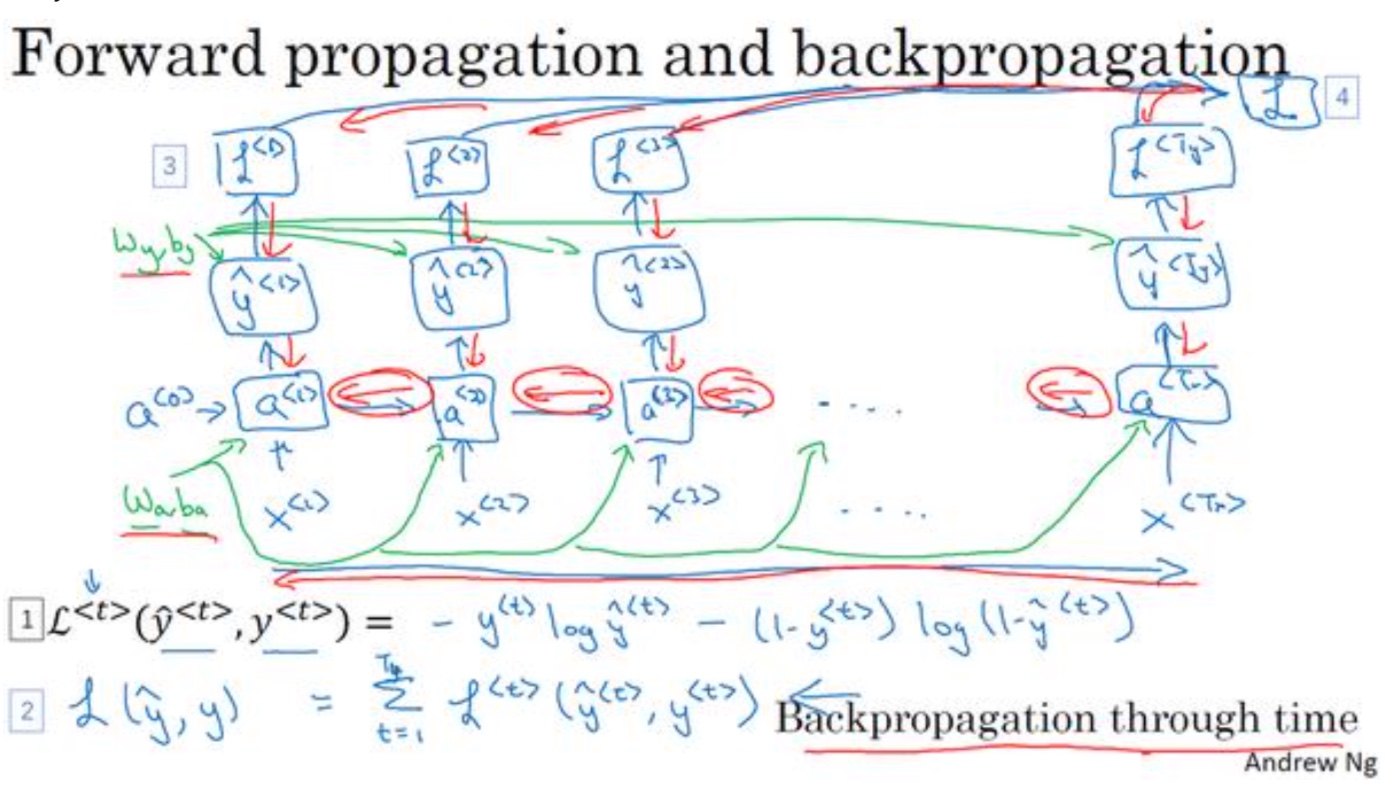
- 同样也是使用bp算法求偏导,进行后向计算,不用的是RNN会有多个输出$\hat y$
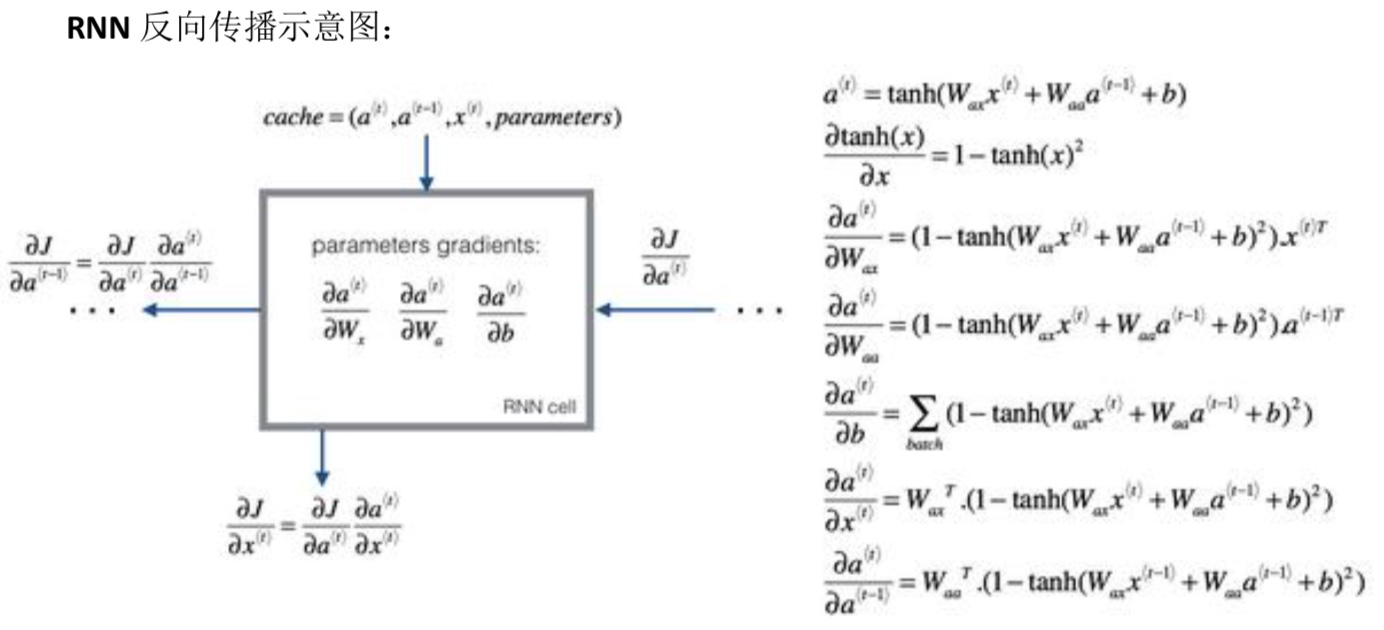
- 对于一个元素的损失函数:
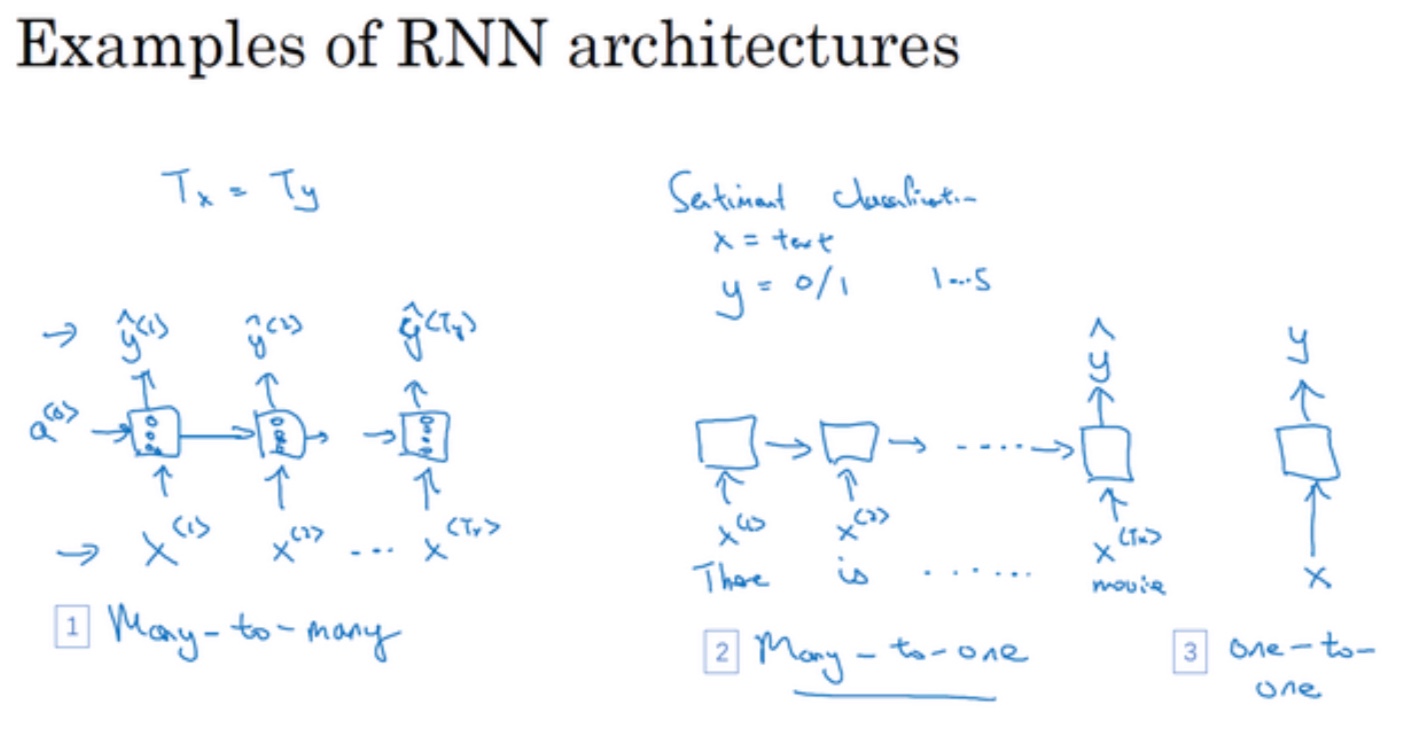
不同类型的RNN
- 输入输出长度分类:
- many-to-many:机器翻译
- many-to-one:情感分类
- one-to-one:小型标准神经网络
- one-to-many:音乐作曲
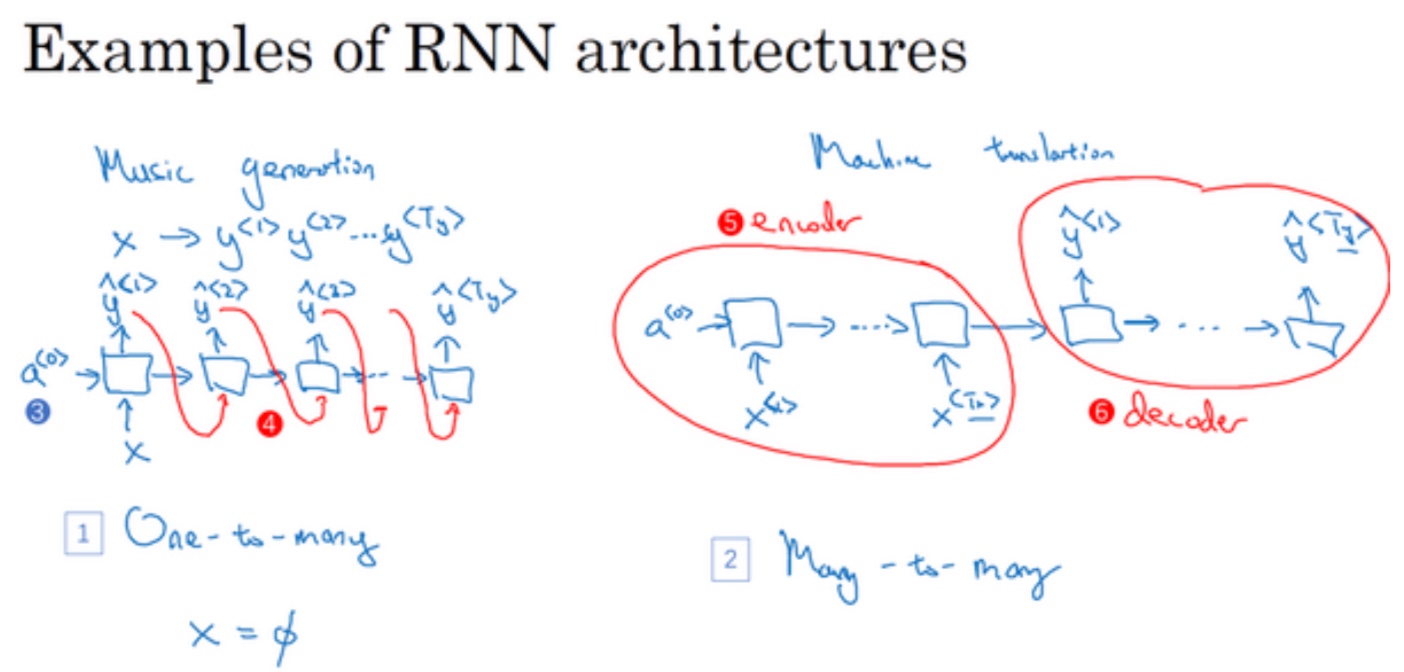
语言模型和序列生成
语言模型:语言模型就是它会告诉你某个特定的句子它出现的概率是多少
- 语言模型做的最基本工作就是输入一个句子,准确地说是一个文本序列,然后语言模型会估计某个句子序列中各个单词出现的可能性。
RNN模型基础结构
- 将每个单词都转换成对应的one-hot向量,也就是词典中的索引,其中也要注意EOS(结尾符),UNK(未知单词),标点符号
- 每一层$\hat y$的输出,都是预测该层输入词在字典中出现的概率
- 最后的输出是每层条件概率的乘积
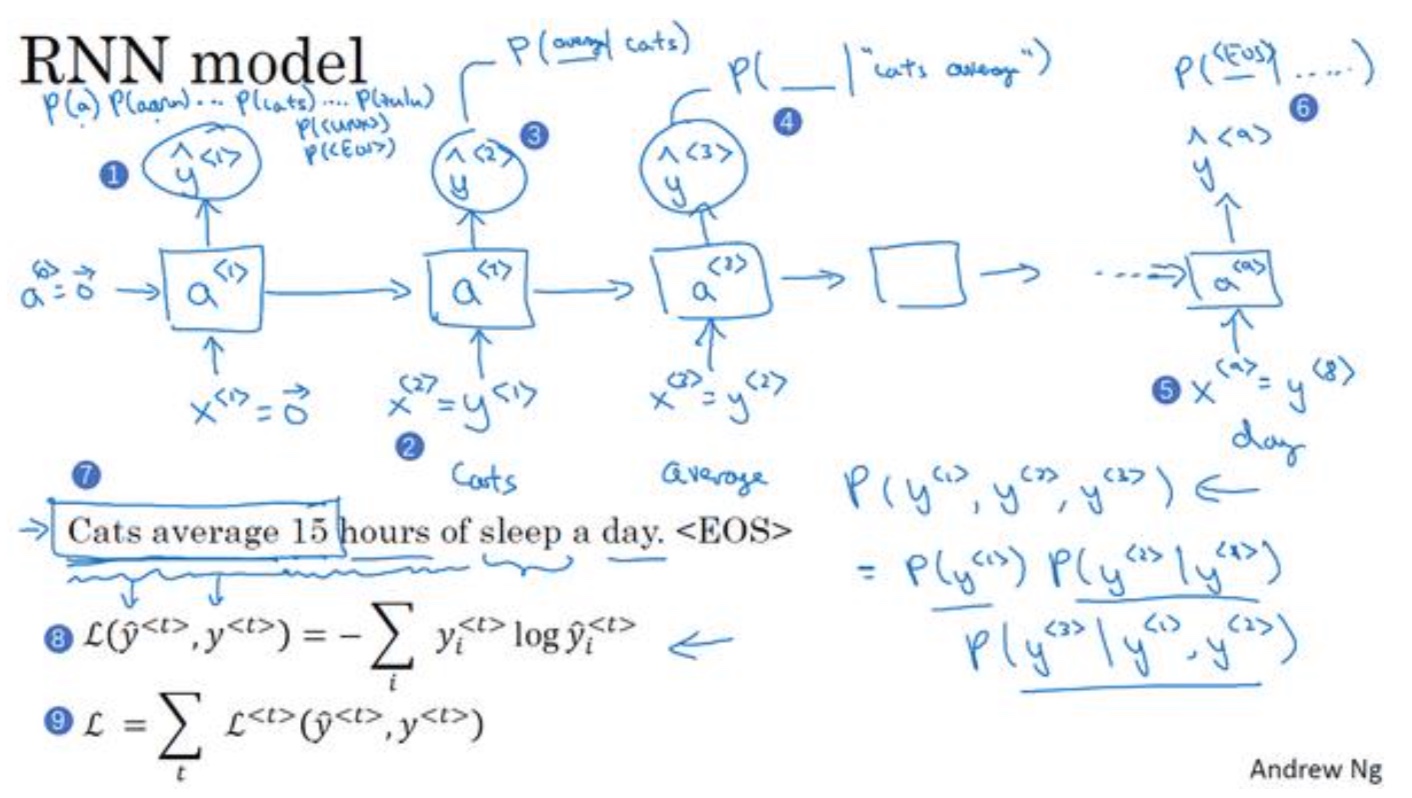
对新序列采样
- 作用:一个序列模型之后,要想了解到这个模型学到了什么,一种非正式的方法就是对新序列采样
- 方法:序列模型模拟了任意特定单词序列的概率,我们要做的就是对这些概率分布进行采样来生成一个新的单词序列
- 如何结束:1.字典中有EOS,2.时间步的多少
- 基于词汇和字符的模型,各有优缺点
RNN中的梯度问题
- 梯度消失:
- 网络的输出$\hat y$得到的梯度很难传播回去,很难影响靠前层的权重,很难影响前面层(编号 5 所示的层)的计算
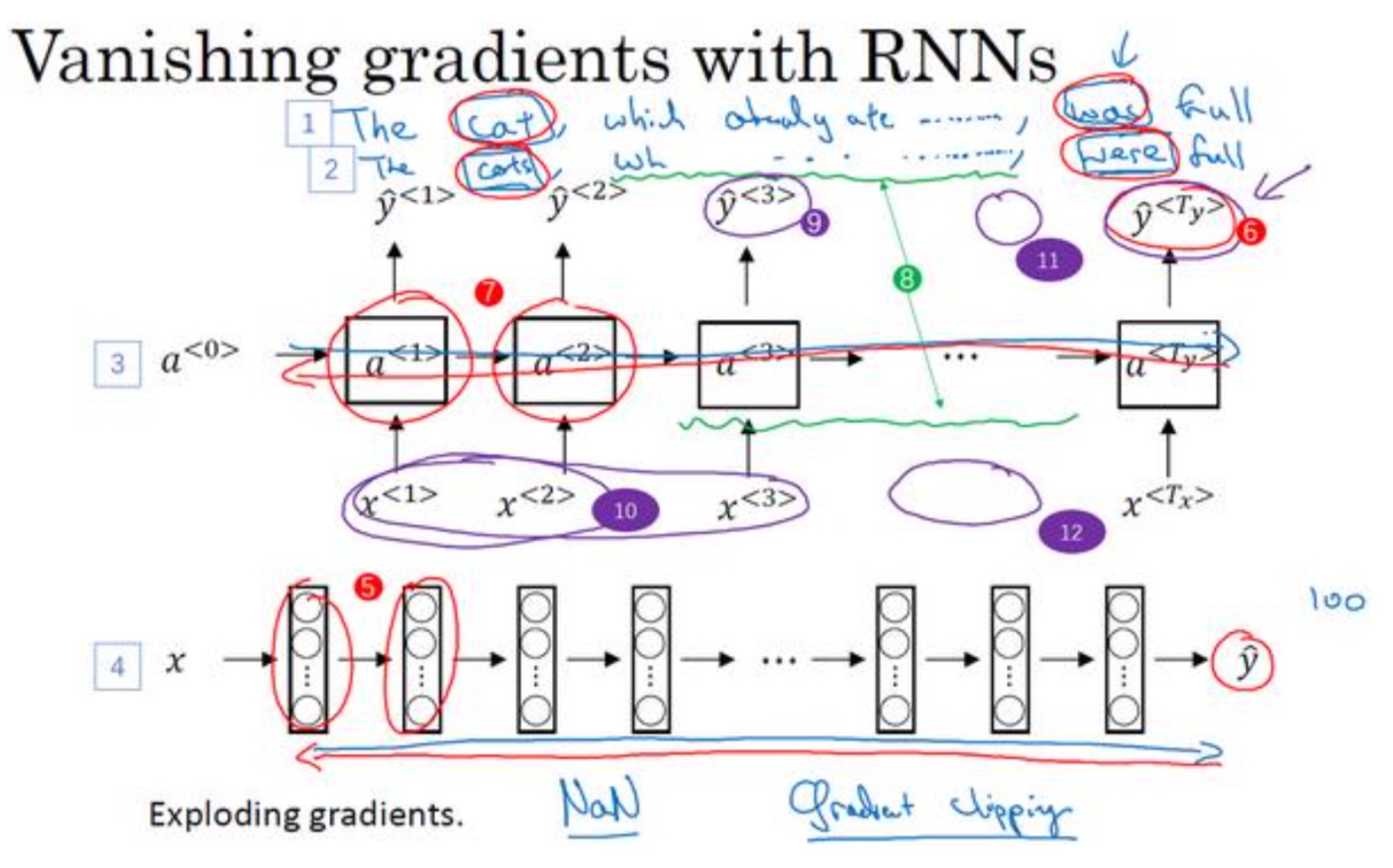
- 基础RNN也同样存在这个问题:前一层名词的单复数和难影响到厚层的动词单复数,很难传递(也是因为输出很难传到前层)
- 如何解决:看后面的GRU和LSTM
- 网络的输出$\hat y$得到的梯度很难传播回去,很难影响靠前层的权重,很难影响前面层(编号 5 所示的层)的计算
- 梯度爆炸:
- 比较容易发现,比如看见很多NaN,或者不是数字的情况,意味着数值溢出
- 解决方法:梯度修剪,就是观察你的梯度向量,如果它大于某个阈 值,缩放梯度向量,保证它不会太大,这就是通过一些最大值来修剪的方法,并且具有好的鲁棒性
GRU(门控制单元)
基础
- 新增变量:记忆细胞cell
- 计算逻辑:如下图3标记中,$\hat C^{< t >} = tanh(W_c[C^{< t-1 >}, x^{< t >}] + b_c)$
- 作用:提供了记忆的能力,比如说一只猫是单数还是复数,所以当它看到之后的句子的时候,它仍能够判断句子的主语是单数还是复数
- 新增变量:门控制变量
- 计算逻辑:如下图3标记中,$\Gamma _u^{< t >} = tanh(W_u[C^{< t-1 >}, x^{< t >}] + b_u)$
- 作用:决定什么更新记忆细胞,是由sigmoid激活,如果为1,才更新C值,所以前面层次的值就可以一直保持到后面
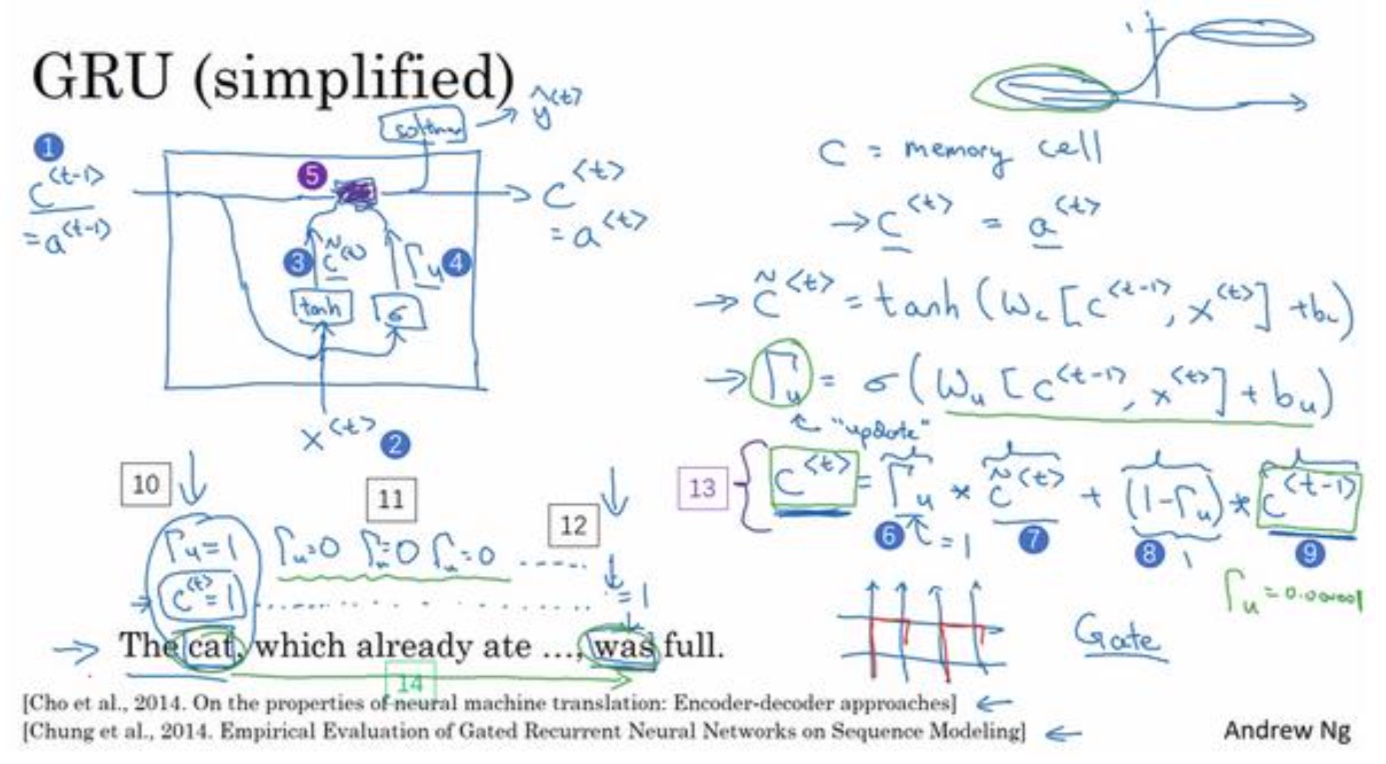
记忆细胞更新逻辑:
如下图5标记中,逻辑门为1才更新C值(或者接近1值,新值C的权重更大)
$C^{< t >} = \Gamma _u\hat C^{< t >} + (1-\Gamma _u) C^{< t-1 >}$如何有效控制梯度消失问题
因为 sigmoid的值,现在因为门很容易取到 0 值,只要这个值是一个很大的负数, $\Gamma_u$值很容易为0,这种情况,就会变成$C^{< t >}=C^{< t-1 >}$,所以记忆细胞的值很好的被维持了。这就是缓解梯度消失的关键
其他
- 同时记忆细胞c可以是多维向量,这样可以记忆很多的内容
- 通过完成的GRU还会有一个相关门:这个相关门告诉你计算出的候选值$\hat C$和$C^{< t-1 >}$有多大的相关性
- $\Gamma _r^{< t >} = tanh(W_r[C^{< t-1 >}, x^{< t >}] + b_r)$

LSTM(Long short term memory)
基础
- LSTM-cell
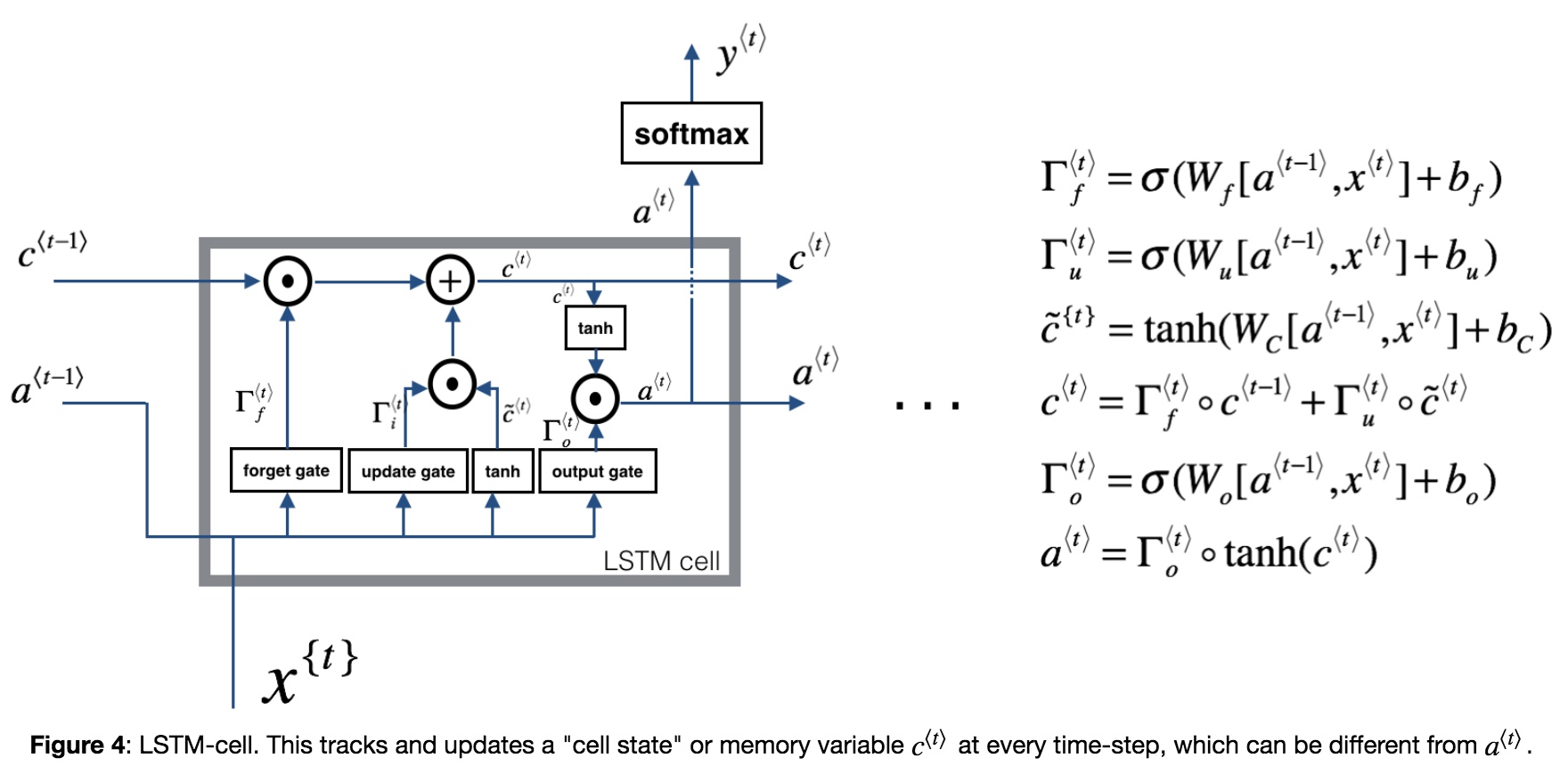
- 遗忘门($\Gamma_f$),让记忆细胞去选择更新新的候选值还是遗忘旧的值
$C^{< t >} = \Gamma_u\hat C^{< t >} + (1-\Gamma_f) C^{< t-1 >}$ - 输出门($\Gamma_o$), $a^{< t >} = \Gamma_o*tanh(c^{< t >})$
LSTM重要公式及前向传播:
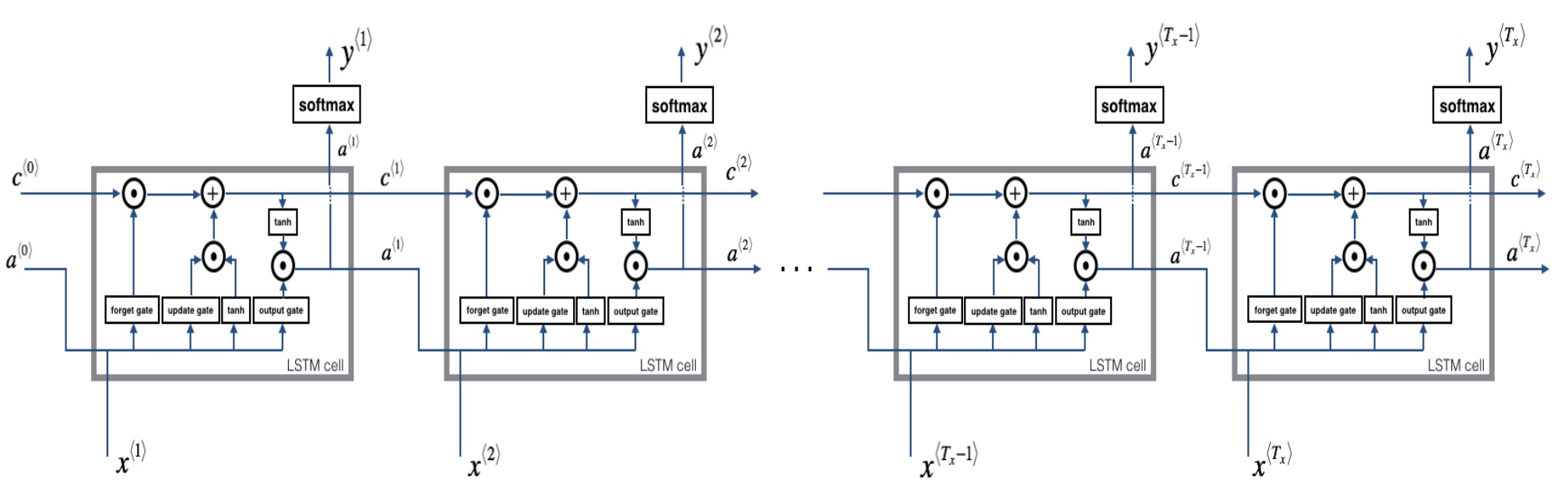
反向传播:就是BP算法,由后向前,对每一个参数求偏导数,对门$\Gamma$,参数W,偏置b,以及最后的隐藏状态,记忆细胞,输入x
- GRU与LSTM
都能够捕获更加深层的神经网络,GRU的优点是比LSTM简单一点的模型,只有两个门,在计算上也运行得更快。但LSTM在历史上是更优的选择
双向RNN
- 背景:有些场景不仅需要参考过去,还应该参考未来
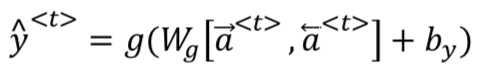
- 缺点:总数需要一段完整的内容
- NLP一般就比较适合,应该经常能够获得完整的文章
- 语音翻译等就不是很适合了,因为要获得已经完整的一段话语通常不是很现实







 code:
code: