参考文章
- 自己总结:
实际是对推荐算法总结的补充
推荐算法总结
CTR模型演进 - 网络文章:
主流CTR预估模型的演化及对比
MLR(混合逻辑回归)
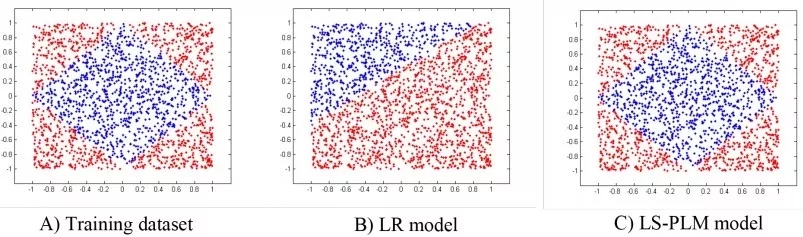
MLR算法是alibaba在2012年提出并使用的广告点击率预估模型,2017年发表出来。MLR模型是对线性LR模型的推广,它利用分片线性方式对数据进行拟合。基本思路是采用分而治之的策略:如果分类空间本身是非线性的,则按照合适的方式把空间分为多个区域,每个区域里面可以用线性的方式进行拟合,最后MLR的输出就变为了多个子区域预测值的加权平均。如下图(C)所示,就是使用4个分片的MLR模型学到的结果
- MLR模型在大规模稀疏数据上探索和实现了非线性拟合能力,在分片数足够多时,有较强的非线性能力;
- 同时模型复杂度可控,有较好泛化能力;同时保留了LR模型的自动特征选择能力。
MLR模型的思路非常简单,难点和挑战在于MLR模型的目标函数是非凸非光滑的,使得传统的梯度下降算法并不适用
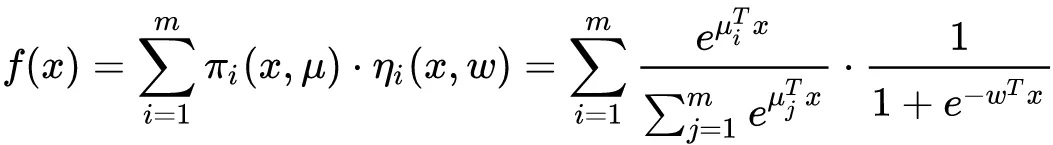
- 上式即为MLR的目标函数,其中m为分片数(当m=1时,MLR退化为LR模型)
- $\pi _i(x,\mu)$是聚类参数,决定分片空间的划分,即某个样本属于某个特定分片的概率
- softmax也是这样做分类
- $\eta _i(x,w)$是分类参数,决定分片空间内的预测
$\mu$和w都是待学习的参数。最终模型的预测值为所有分片对应的子模型的预测值的期望
神经网络思路
另一方面,MLR模型可以看作带有一个隐层的神经网络。如下图,是大规模的稀疏输入数据,MLR模型第一步是做了一个Embedding操作,分为两个部分,一种叫聚类Embedding(绿色),另一种是分类Embedding(红色)。两个投影都投到低维的空间,维度为,是MLR模型中的分片数。完成投影之后,通过很简单的内积(Inner Product)操作便可以进行预测,得到输出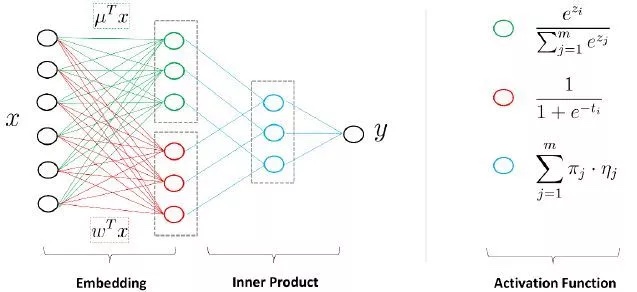
FNN (Factorization-machine supported Neural Network)
- 思路类似于LR+GBDT,两个阶段:
- 第一个阶段先用一个模型做特征工程
除了神经网络模型,FM模型也可以用来学习到特征的隐向量(embedding表示),因此一个自然的想法就是先用FM模型学习到特征的embedding表示 - 第二个阶段用第一个阶段学习到新特征训练最终的模型
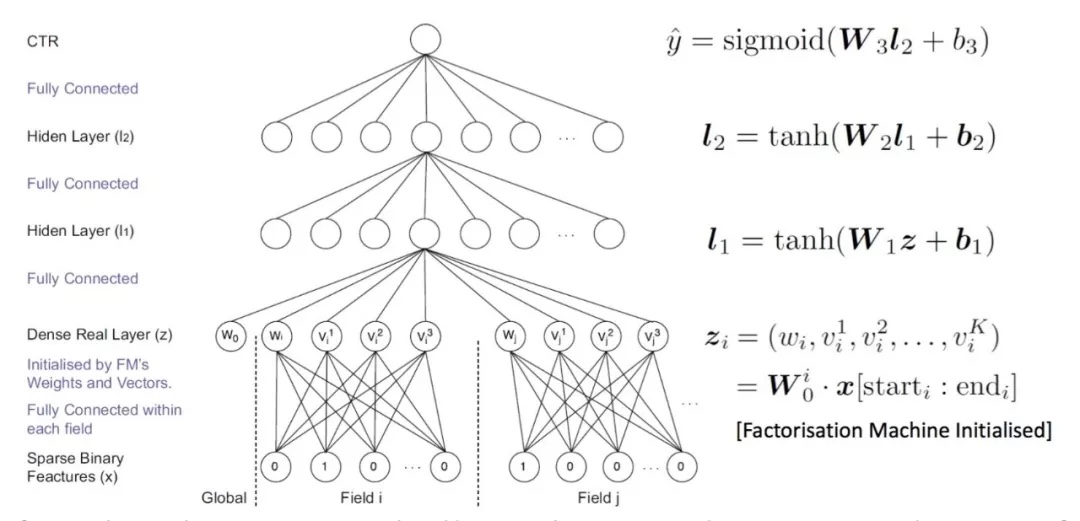
- 第一个阶段先用一个模型做特征工程
PNN(Product-based Neural Networks)
- 背景
MLP中的节点add操作可能不能有效探索到不同类别数据之间的交互关系,虽然MLP理论上可以以任意精度逼近任意函数,但越泛化的表达,拟合到具体数据的特定模式越不容易 - PNN主要是在深度学习网络中增加了一个inner/outer product layer,用来建模特征之间的关系
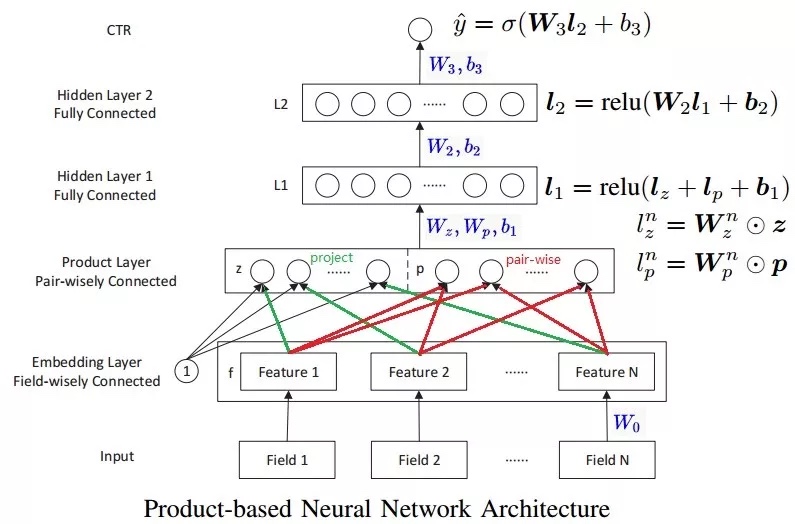
- Product Layer的节点分为两部分,一部分是z向量,另一部分是p向量。z向量的维数与输入层的Field个数(N)相同,$z=(f_1,f_2,…f_N)$。p向量的每个元素的值由embedding层的feature向量两两成对并经过Product操作之后生成,$p={g(f_i,f_j)}$i=1…N,j=1…N,因此p向量的维度为N*(N-1)
- Product操作有两种:内积和外积;对应的网络结构分别为IPNN和OPNN
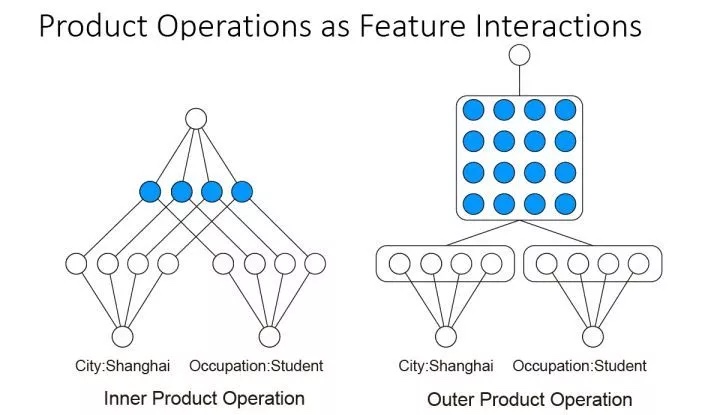
总结
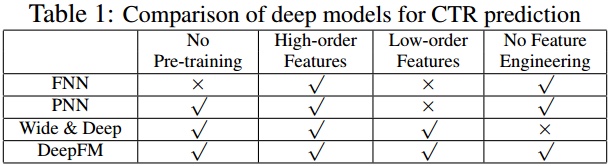
- 主流的CTR预估模型已经从传统的宽度模型向深度模型转变,与之相应的人工特征工程的工作量也逐渐减少
- 上文提到的深度学习模型,除了DIN对输入数据的处理比较特殊之外,其他几个模型还是比较类似的,它们之间的区别主要在于网络结构的不同

- 这四种深度学习模型的比较见下表
- 综上,深度学习技术主要有三点优势
- 个人觉得在是否都能包含高低维特征,特征是否需要工程化上面很重要,并且也在向这个方向发展
- 模型设计组件化
组件化是指在构建模型时,可以更多的关注idea和motivation本身,在真正数学化实现时可以像搭积木一样进行网络结构的设计和搭建。 - 深度学习可以帮助我们实现设计与优化的解耦,将设计和优化分阶段进行
- 对于工业界的同学来说,可以更加关注从问题本身出发,抽象和拟合领域知识。然后用一些标准的优化方法和框架来进行求解