相关文章
- 参考我之前的总结:
CF,FM,WDL,DeePFM总结
xDeepFM模型总结这里只是对比每个模型的优缺点及演进路线,具体每个模型的学习需要参考上面两篇文章 - 网络文章
CTR模型演进
CTR数据特点
- 图像中会有大量的像素与周围的像素比较类似;文本数据中语言会受到语法规则的限制。CNN对于空间特征有很好的学习能力,正如RNN对于时序特征有强大的表示能力一样
- 在Web-scale的搜索、推荐和广告系统中,特征数据具有高维、稀疏、多类别的特点,一般情况下缺少类图像、语音、文本领域的时空关联性
深度CTR、CVR预估模型发展演化的三条主线
- 1.第一条主脉络是以FM家族为代表的深度模型,它们的共同特点是自动学习从原始特征交叉组合新的高阶特征。
- 2.第二条主脉络是一类使用attention机制处理时序特征的深度模型,以DIN、DIEN等模型为代表
- attention机制是不是可以在某种程度上理解为一种特殊形式的组合特征,和第一条主线雷同
- 3.第三条主脉络是以迁移学习、多任务学习为基础的联合训练模型或pre-train机制,以ESMM
- 属于流程或框架层面的创建
FM家族的交叉特征组合
背景
交叉组合原始特征构成新的特征是一种常用且有效的特征构建方法。哪些特征需要被交叉组合以便生成新的有效特征?需要多少阶的交叉组合?这些问题在深度学习流行之前需要算法工程师依靠经验来解决。人工构建组合特征特别耗时耗力,在样本数据生成的速度和数量巨大的互联网时代,依靠人的经验和技能识别出所有潜在有效的特征组合模式几乎是不可能的。一些有效的组合特征甚至没有在样本数据中出现过。
GBDT+LR
- 特点:将特征工程和目标拟合分为两个模型,能够组合些高阶的特征,但是比较麻烦
FM
- 特点:
- 模型是第一个从原始特征出发,端到端学习的例子
- FM提出了一种很好的自动学习交叉组合特征的思路,随后融入FM模型思路的深度学习模型便如雨后春笋般应运而生,典型的代表有FNN、PNN、DeepFM、DCN、xDeepFM等
- 问题:
- FM毕竟还是一个浅层模型,经典的FM模型只能做二阶的特征交叉,模型学习复杂组合特征的能力偏弱
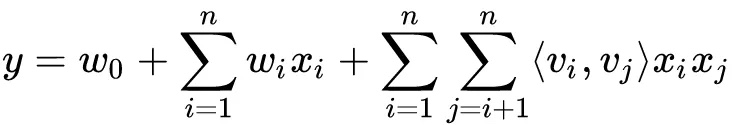
- FM毕竟还是一个浅层模型,经典的FM模型只能做二阶的特征交叉,模型学习复杂组合特征的能力偏弱
FNN
- 背景:
FNN模型最先提出了一种增强FM模型的思路,就是用FM模型学习到的隐向量初始化深度神经网络模型(MLP),再由MLP完成最终学习 - 特点:
- MLP(plain-DNN)因其特殊的结构天然就具有学习高阶特征组合的能力,它可以在一定的条件下以任意精度逼近任意函数
- 可以看出plain-DNN的高阶特征交互建模是元素级的(bit-wise),也就是说同一个域对应的embedding向量中的元素也会相互影响
- 不足:
- plain-DNN以一种隐式的方式建模特征之间的交互关系,我们无法确定它学习到了多少阶的交叉关系
- 虽然两种建模交叉特征的方式(bit-wise和vectiro-wise)有一些区别,但两者并不是相互排斥的,如果能把两者集合起来,便会相得益彰
PNN
- 背景:
PNN模型最先提出了一种融合bit-wise和vector-wise交叉特征的方法,其通过在网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合 - 不足:
舍弃了低阶特征:PNN与FM相比,舍弃了低阶特征,也就是线性的部分,这在一定程度上使得模型不太容易记住一些数据中的规律
WDL
- 特点:WDL(Wide & Deep Learning)模型混合了宽度模型与深度模型,其宽度部分保留了低价特征,偏重记忆;深度部分引入了bit-wise的特征交叉能力
- 不足:
宽度部分的输入依旧依赖于大量的人工特征工程- 能不能在融合bit-wise和vector-wise交叉特征的基础上,同时还能保留低阶特征(linear part)呢?
DeepFm
- 背景:
能不能在融合bit-wise和vector-wise交叉特征的基础上,同时还能保留低阶特征(linear part)呢(优化WDL问题) - 特点:
- DeepFM模型融合了FM和WDL模型,其FM部分实现了低阶特征和vector-wise的二阶交叉特征建模,其Deep部分使模型具有了bit-wise的高阶交叉特征建模的能力
- 不足:
FM、DeepFM和Inner-PNN都是通过原始特征隐向量的内积来构建vector-wise的二阶交叉特征,有下面问题:- 必须要穷举出所有的特征对,即任意两个field之间都会形成特征组合关系,而过多的组合关系可能会引入无效的交叉特征,给模型引入过多的噪音,从而导致性能下降
- 二阶交叉特征有时候是不够的,好的特征可能需要更高阶的组合。虽然DNN部分可以部分弥补这个不足,但bit-wise的交叉关系是晦涩难懂、不确定并且不容易学习的
- 所以:有没有可能引入更高阶的vector-wise的交叉特征,同时又能控制模型的复杂度,避免产生过多的无效交叉特征呢
DCN
DCN模型以一个嵌入和堆叠层(embedding and stacking layer)开始,接着并列连一个cross network和一个deep network,接着通过一个combination layer将两个network的输出进行组合。交叉网络(cross network)的核心思想是以有效的方式应用显式特征交叉
- 不足:
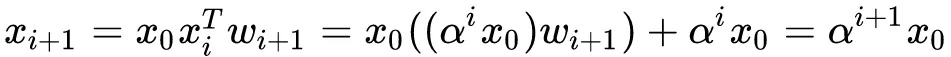 因此Cross Network的输出就相当于不断乘以一个数,当然这个数是和$x_0$高度相关的
因此Cross Network的输出就相当于不断乘以一个数,当然这个数是和$x_0$高度相关的- CrossNet的输出被限定在一种特殊的形式上
- 特征交叉还是以bit-wise的方式构建的
xDeepFM
- 背景
- 由上面的DCN网络可以看出:时间cross网络的每一层是上一层的乘以一个标量得到,并没有做到vector-wise的特征多阶交叉
- 特征交叉还是以deep部分的bit-wise的方式构建的
- 特点
既有线下模型的记忆能力,也集成了多维特征的显示交叉,同时也兼顾了DNN网络隐式特征交叉和泛华能力,在CIN网络也采用池化计算进行降维,有效的避免了维度爆炸的情况- CIN:集成显示的高阶特征交叉
- DNN:集成隐式的高阶特征交叉,并兼顾泛华能力
- 线下模型:集成线下模型有助于记忆功能
总结
特征交叉组合作为一种常用的特征工程方法,可以有效地提升模型的效果。特征交叉组合从人工方式开始,经历了模型辅助的阶段,最后发展到各种端到端模型的阶段。端到端模型从建模二阶交叉关系向构建高阶交叉关系的方向发展,同时建模方式也从bit-wise向vector-wise发展。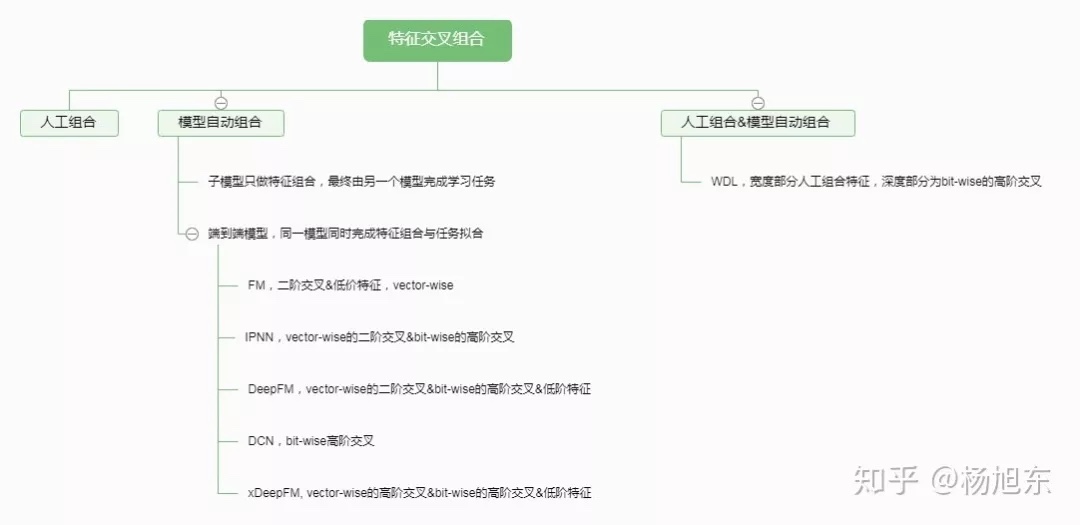
- 本文总结了FM家族的一系列深度学习模型,这些模型有一个共同的强制要求:所有field的embedding向量的维数是相同的。这个要求是合理的吗?我们知道不同的field对应的值空间大小是不一样的,比如淘宝商品ID的量级在十亿级,类目的量级在万级,用户年龄段的量级在十级,在如此巨大的差异的情况下,embedding向量的维数只能取得尽可能的大,这大大增加了模型的参数量级和网络的收敛时间。所以作者认为本文提及的FM家族模型有两个主要缺点:
- 强制要求所有field的embedding向量的维数,增加了网络复杂度;
- 对连续值特征不友好