背景
传统CVR预估模型有样本选择偏差(sample selection bias)和训练数据过于稀疏(data sparsity )的问题
- 以电子商务平台为例,用户在观察到系统展现的推荐商品列表后,可能会点击自己感兴趣的商品,进而产生购买行为。换句话说,用户行为遵循一定的顺序决策模式:impression → click → conversion:即p(CVR) = p(conversion|click,impression)
样本选择偏差
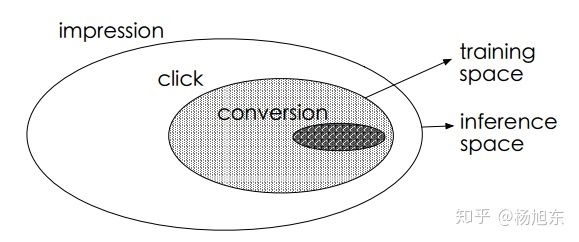
- 对应图中的阴影区域,传统的CVR模型就是用此集合中的样本来训练的,同时训练好的模型又需要在整个样本空间做预测推断。由于点击事件相对于展现事件来说要少很多,只是全局的一个很小的子集。
- 违背了机器学习算法之所以有效的前提:独立同分布
- 样本选择偏差会伤害学到的模型的泛化性能
数据过于稀疏
- 对应图中的阴影区域,传统的CVR模型就是用此集合中的样本来训练的,数据量太少
ESMM模型
概念
- CTCVR
- x是高维稀疏多域的特征向量,y和z的取值为0或1,分别表示是否点击和是否购买
- CVR模型的目标是预估条件概率pCVR ,与其相关的两个概率为点击率pCTR 和点击且转换率 pCTCVR ,它们之间的关系如下:
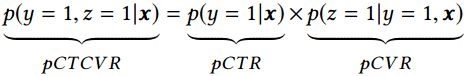
模型架构
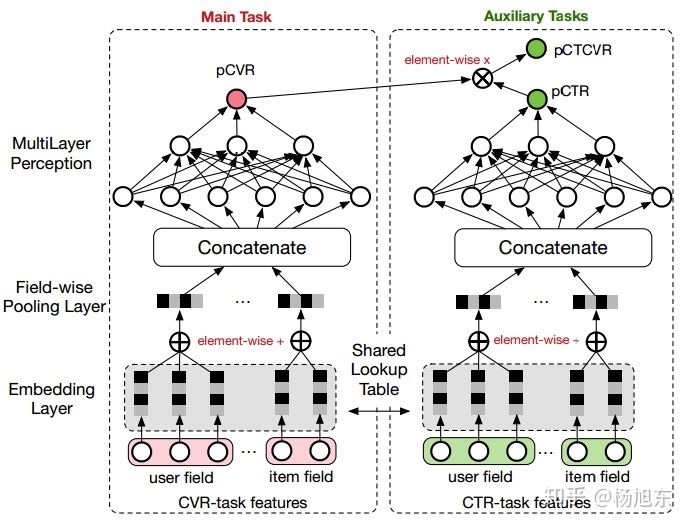
- 在整个样本空间建模,而不像传统CVR预估模型那样只在点击样本空间建模
- 共享特征表示
由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题 - 损失函数由两部分组成
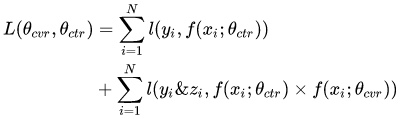
- 其中,$\theta _{ctr}$ 和$\theta _{cvr}$分别是CTR网络和CVR网络的参数,l(.)是交叉熵损失函数。在CTR任务中,有点击行为的展现事件构成的样本标记为正样本,没有点击行为发生的展现事件标记为负样本;在CTCVR任务中,同时有点击和购买行为的展现事件标记为正样本,否则标记为负样本
总结
- ESMM模型是一个新颖的CVR预估方法,其首创了利用用户行为序列数据在完整样本空间建模,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果
- ESMM模型的贡献在于其提出的利用学习CTR和CTCVR的辅助任务,迂回地学习CVR的思路。ESMM模型中的BASE子网络可以替换为任意的学习模型,因此ESMM的框架可以非常容易地和其他学习模型集成,从而吸收其他学习模型的优势,进一步提升学习效果,想象空间巨大