达观数据个性化推荐系统实践
刘志强 奇虎360:机器学习与推荐系统实践
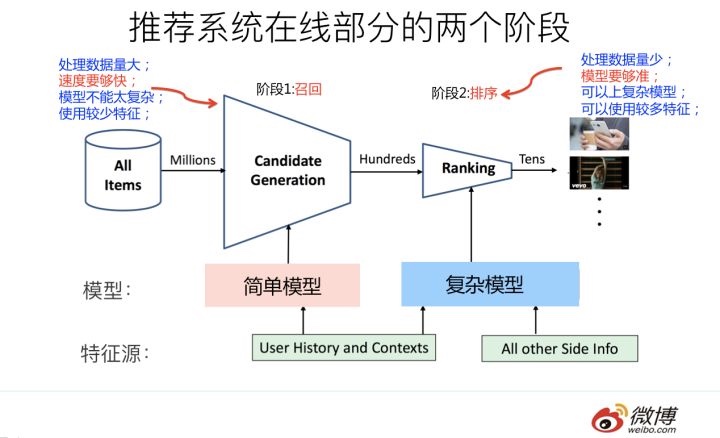
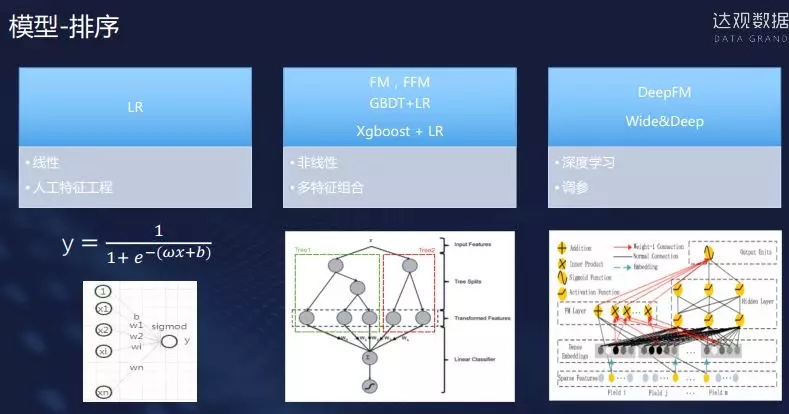
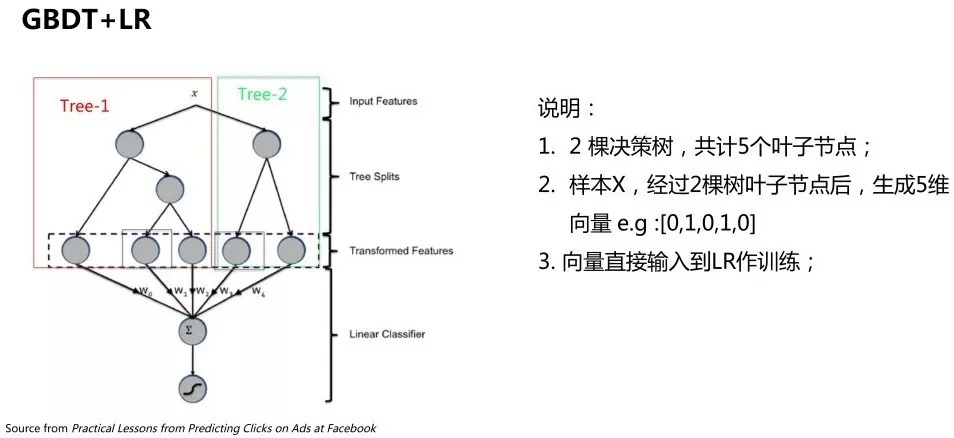
整体过程
- 用户
推荐系统本质是将人和物品关联起来,而系统对用户的理解也是由浅入深,初来时彼此陌生,需要有一个冷启的过程,逐渐把握用户的喜好。随着用户行为的丰富,系统对用户兴趣的描述也越来越客观,此时便可能得到更准确的用户偏好,进而完成更精准的推荐。然而物极必反,用户对于一个平台的认知与期望也是一样。随着用户的深度使用,势必对推荐系统生出更高的期待和要求。这时,便可能需要系统在满足深度用户某种刁钻的口味,与大众用户的普遍期待中做出某种取舍。用户也就不可避免的出现了流失。因为系统的能力终归有限,而用户的期望无限。 - 资源
此外资源也会经历类似的过程,新进场的资源虽然天然有某种内容的属性,但其被用户接受,仍然不可避免需要经历一个过程。过程中有些资源会被淘汰,有些则会成长为热门。在不断地引入新资源的过程中,再热门的资源都会有过期的一天。就好比,再会保养的人,也逃不过岁月的流逝。甚至,为了保持系统的实时性,热门的资源需要主动地让出在系统中的曝光份额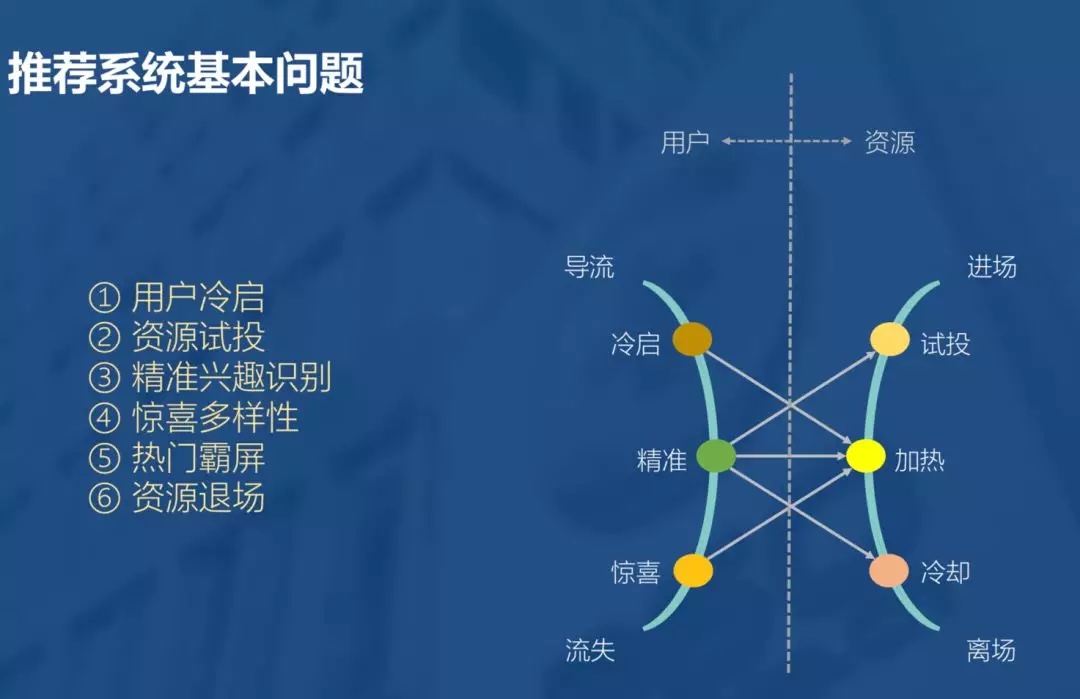
如何精准把握用户兴趣
用户兴趣不仅存在多样性,而且会随着时间的变化而变化
- 长短期兴趣画像让模型效果稳定提升
- 通过引入时间因子,基于不同的时间周期做用户画像
- 比如基于最近半年的或更久的数据做长期用户画像,基于近一个月或三个月做短期用户画像,同时还会有实时用户画像,基于这三种类型用户画像之间的差异化,能够感知用户的兴趣变更
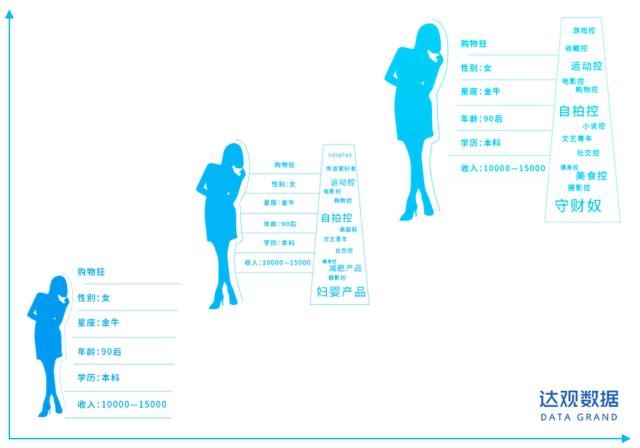
- 比如基于最近半年的或更久的数据做长期用户画像,基于近一个月或三个月做短期用户画像,同时还会有实时用户画像,基于这三种类型用户画像之间的差异化,能够感知用户的兴趣变更
- 基于用户画像后做一个过滤机制,把推荐过或者质量不佳先过滤。这样做排序时会引入一个时间因子做一个衰减,另外也会做机器学习的预测,可以方便地调整推荐顺序。
- 接下来做优化,随着时间的推移,对于用户的刻画会更清晰准确
冷启动
- 主要分为:用户冷启动,物品冷启动,系统冷启动
- 用户冷启动
- 和其他领域做映射
从其他维度或领域的数据来判断新用户对现存物品的喜好。具体解释就是某个用户可能在已有领域current domain和另一领域out domain都有相关行为,可对两个不同领域的行为建立一个mapping,当新用户来的时候,如果在另一领域有相关行为,可用该mapping作出prediction,得到新用户对item的喜好程度
- 先给用户推荐热门内容,等行为多后再进行个性化推荐
- 利用注册信息
根据用户注册账号时填写的性别、年龄、地址等信息,推荐相关性高的内容或者商品- 比如说一个人的性别是男、年龄是40岁、职业是老师,那么就会有对应“性别是男、年龄是40岁、职业是老师”的三个相关推荐列表,再根据筛选,确定最终的推荐列表
- 授权设备信息
通过授权,可以获得手机中的位置,通讯录,按照app等,然后通过这些信息来做进一步聚合推荐- 指的是允许app访问手机的一些信息,比如定位、安装信息、通讯录等,这样就可以推荐通讯录好友喜欢过的内容或商品
- 或者说你手机里安装过懂球帝,就可以给你推荐足球相关的内容
- 假如你安装了美丽说、蘑菇街、大姨妈等app,就可以判定你是女性了,更进一步还可以判定你是备孕还是少女
- 首次登录选标签
要求用户进来时选择一个或者多个标签,然后收集整理用户感兴趣的范围,去推荐相关性高的内容和商品 - 绑定社交账号
利用用户的社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的内容或物品
- 和其他领域做映射
- 物品冷启动
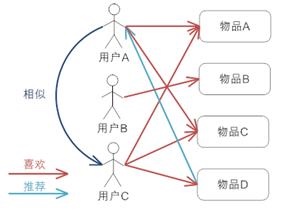
- 对物品分类,可以使用Item-CF方法,推荐给相关用户
- 设置一定概率的曝光机会,然后根据收益进行调整
- 系统冷启动
- 采用专家标注
对物品进行人工的标记,比如电影可以标记心情、剧情类型、类别、故事时间、地点、观众类型、获奖情况、风格、主旨、画面技术等等。在专家标记了一定样本之后使用自然语言理解和机器学习技术,通过分析用户对电影的评价和电影自身的内容属性对新电影进行自我标记。同时还设置了用户反馈界面,通过用户反馈进行改善
- 采用专家标注
回声室效应
为了满足用户的兴趣。第二部分是重复,如果依赖于内容标签或者内容分类,对于标签或者类目来不断地召回新的推荐结果,这会导致推荐结果没有新鲜感
性能方面
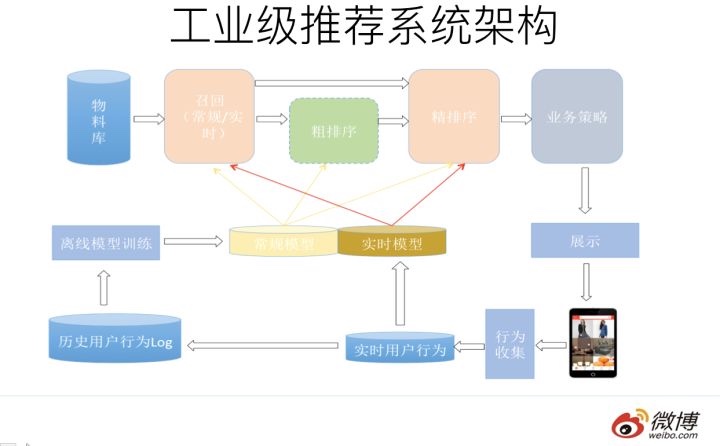
- 采用离线,近实时,实时三层架构解决,可以参考推荐系统架构篇
其他问题
- 精准兴趣
在推荐系统中,我们往往使用用户的点击行为来估计用户的喜好类型。然而用户的每次点击未必都是经过其深思熟虑之后的结果,因此行为本身会存在一个置信度的问题。而这个置信度是未知的 - 新资源找不到合适用户
大量优质资源找不到需要的用户,成为层面资源,而低俗的内容大量曝光 - EE问题