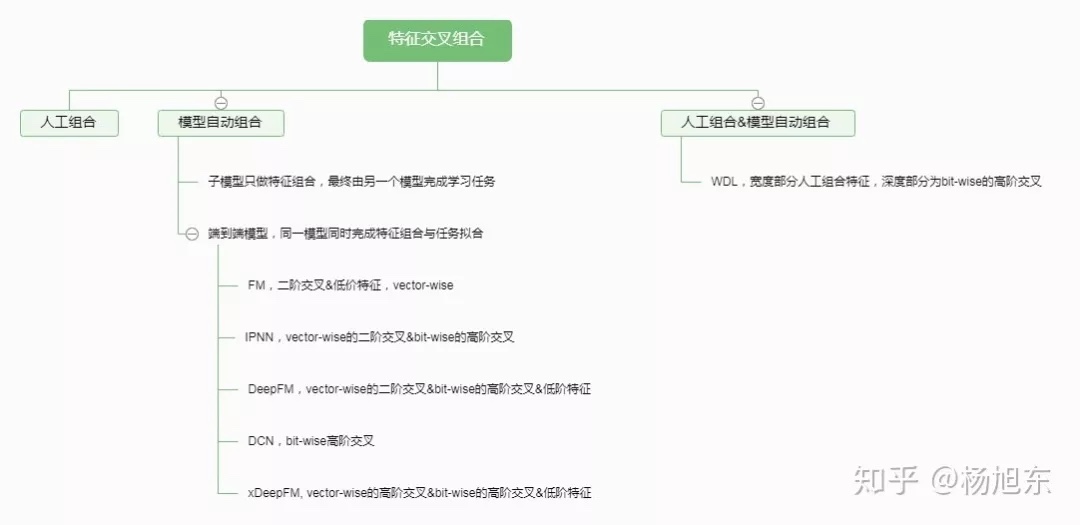
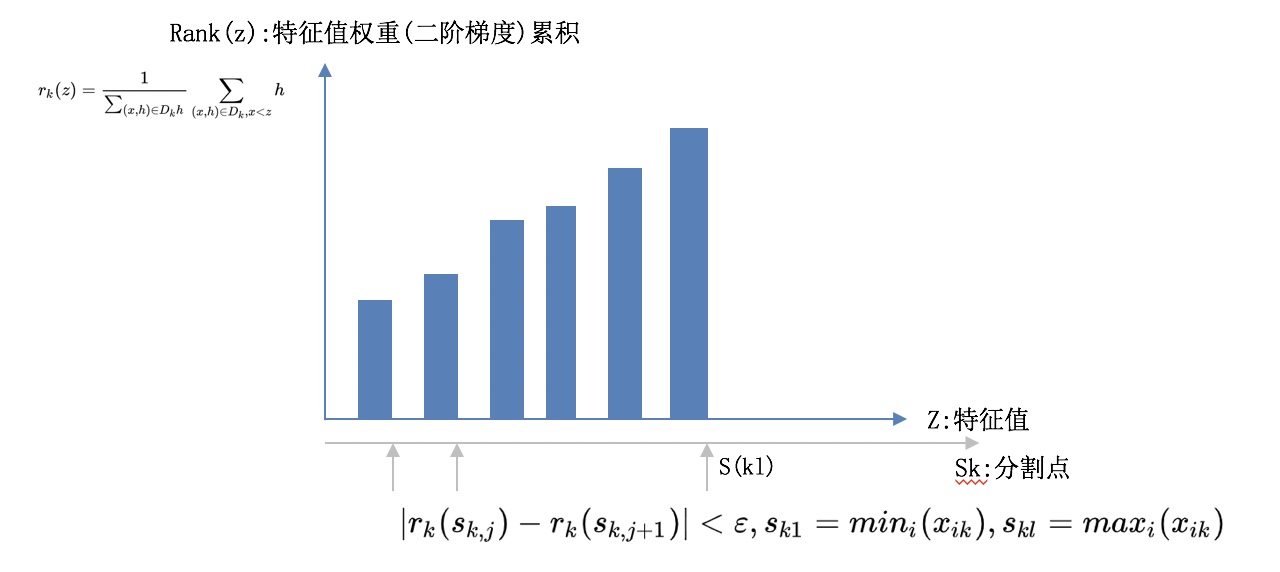
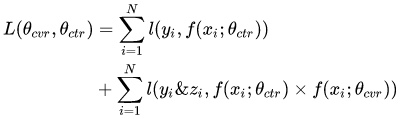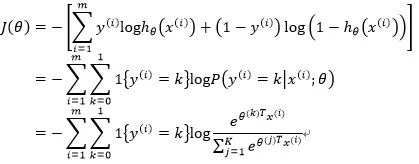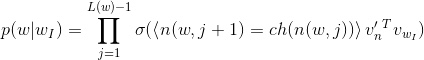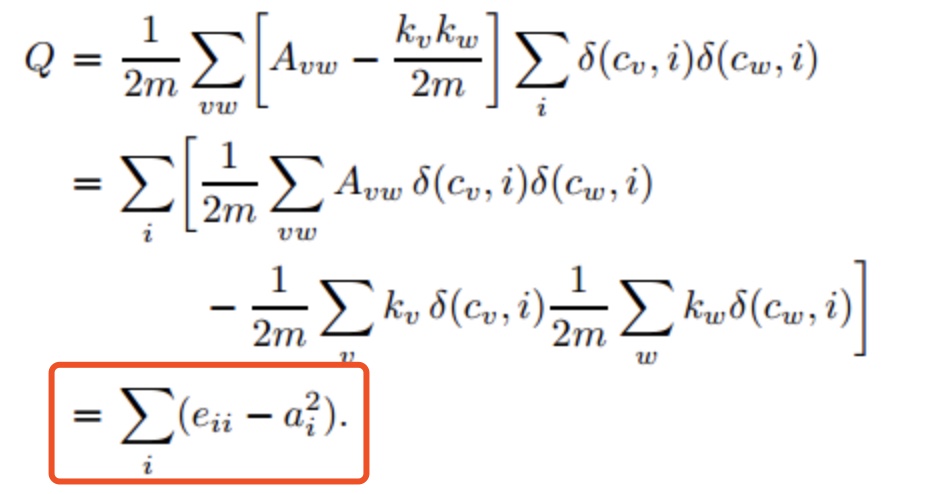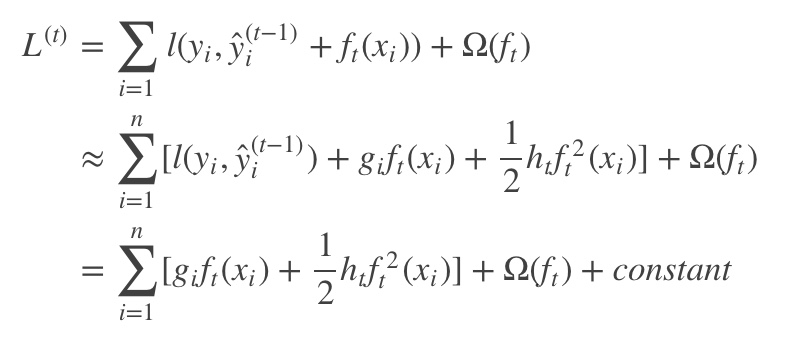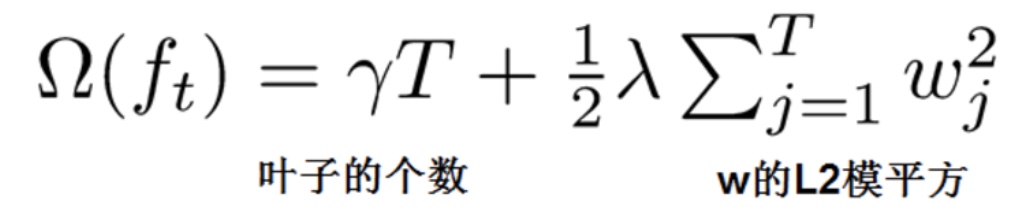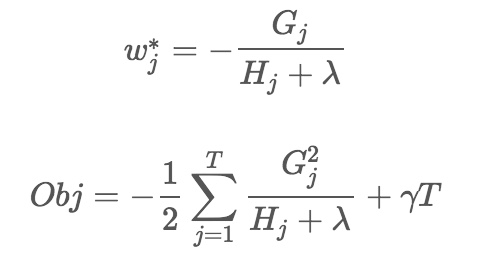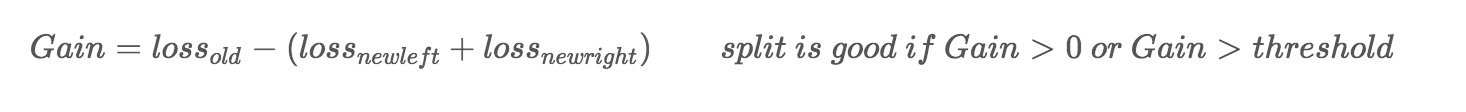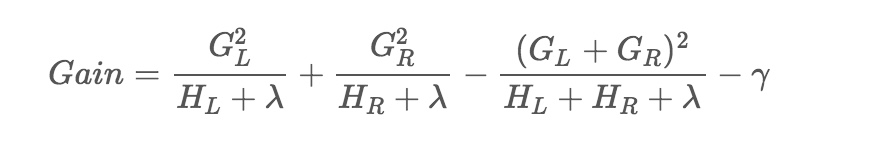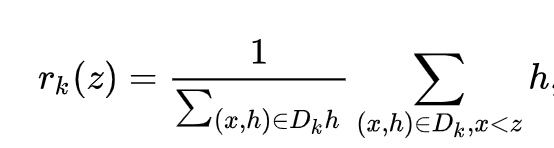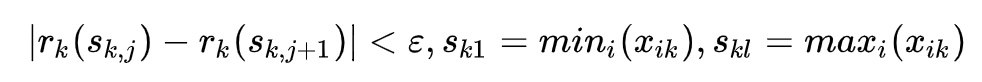词向量之DNN模型
word2vec-Hierarchical Softmax
word2vec-Negative Sampling
词向量之DNN模型
- 模型
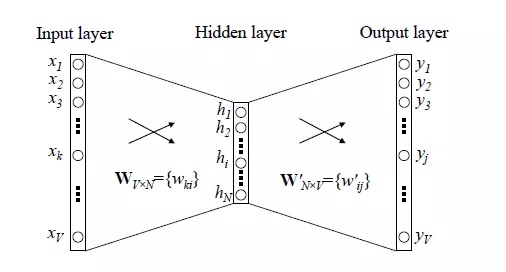
- 训练方式:CBOW或者Skip-gram
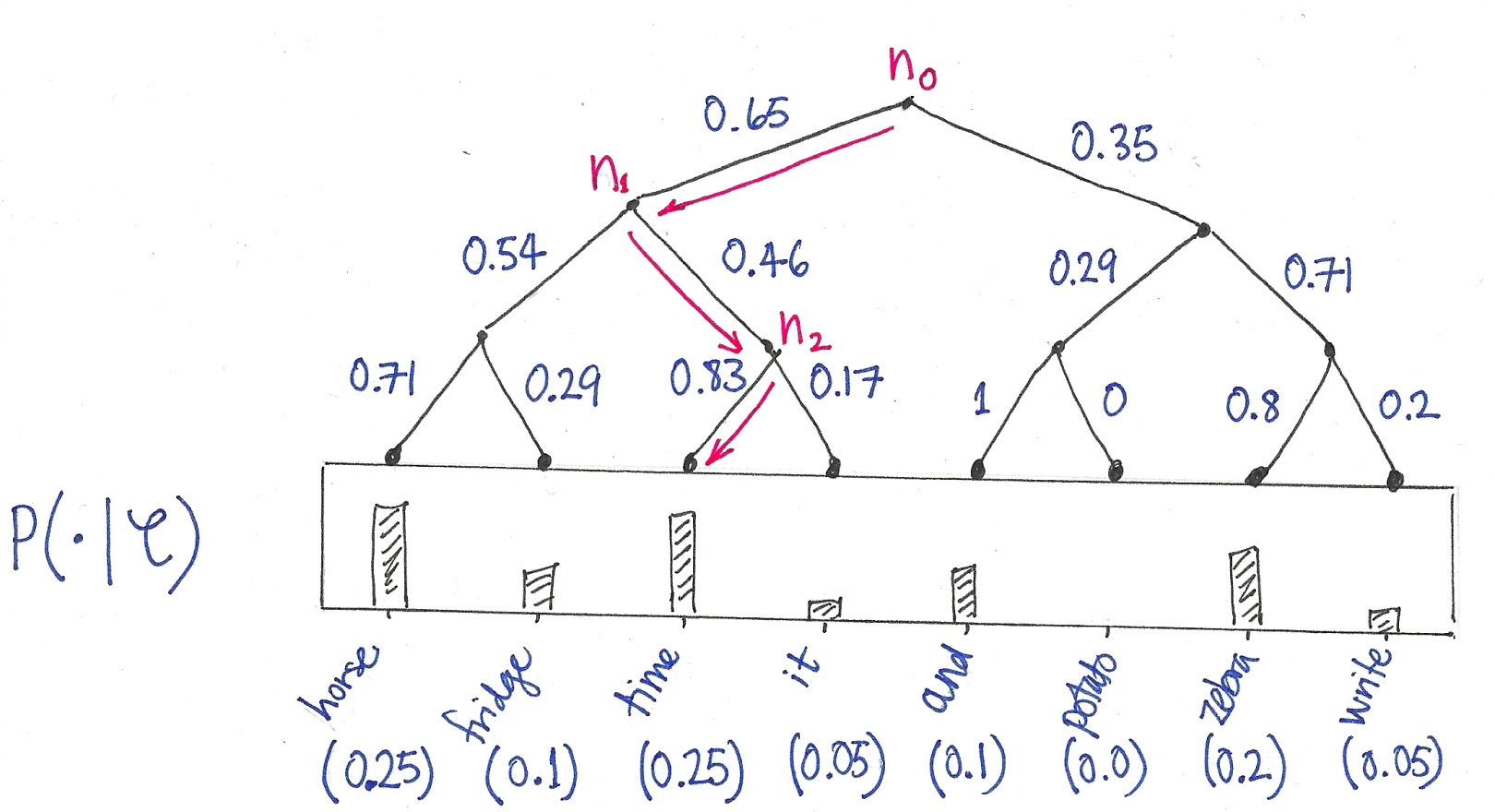
- 输入:one-hot向量,n*V矩阵(V表示词汇数量,n表示输入词数)
- Hidden layer:我们想得到的N维词向量
- Output layer:softmax分类
- 核心就是采用语言模型,学习Input layer和Hidden layer直接的参数矩阵(词嵌入矩阵)
- 训练方式:softmax进行多分类,采用交叉熵作为loss,梯度下来求解方法进行训练
- 缺点:
- 从input layer到hidden layer
每次我们只是使用了几个单词进行训练,但是在计算梯度的过程却要对整个参数矩阵进行运算,这样计算效率低下 - 从hidden layer到output layer
采用全连接层并用softmax方式,需要对输出层中每个位置求其概率。为了得到输出层的每个位置的概率,我们需要求得所有单词的得分,如果一个词汇表很庞大的话,这是很耗资源的
- 从input layer到hidden layer
word2vec-Hierarchical Softmax
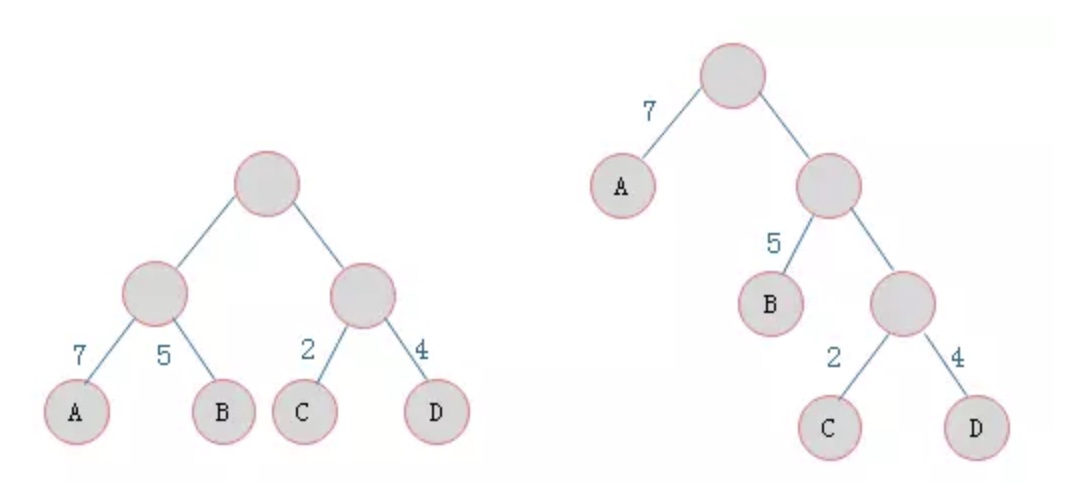
- 霍夫曼树
参考FastText中的霍夫曼链接,总的来说就是让出现频率大的词在树较浅的层次,频率小的出现在较深层次(最少编码也是这个道理) - 网络结构
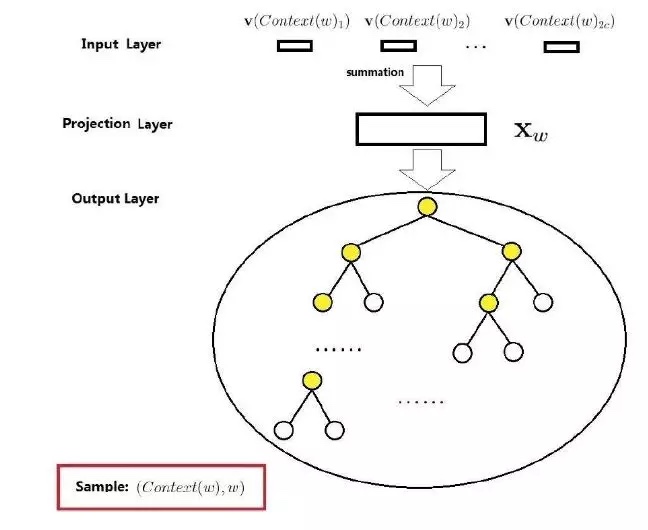
- 模型学习方式同样可以是CBOW或者Skip-gram模式
- Input layer:需要学习的词向量,多个词向量加和平均到映射层
- Output layer:通过加和平均得到的向量,作为输入,通过
Hierarchical Softmax进行分类训练
- 训练过程:
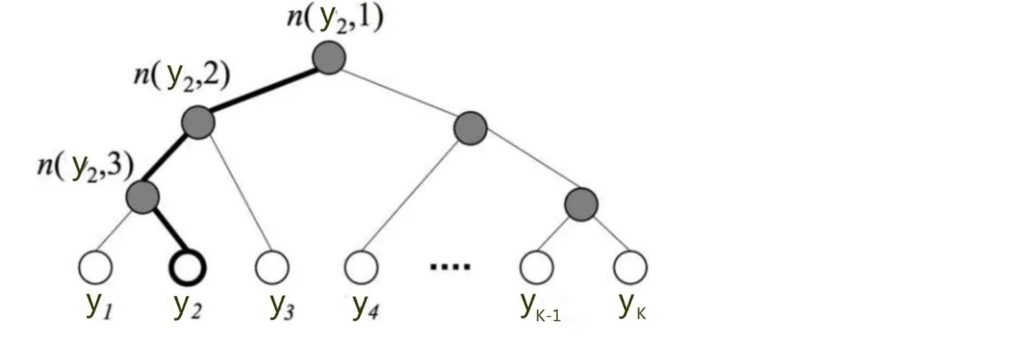
- 需要通过已经词表构造一颗霍夫曼树(通过频率的计算)
- 通过$X_w$的输入,就能够通过霍夫曼树确定该输入对应到的叶子节点,同时也就知道了整个路径(类似101001…)
- 每一个节点的选择都是通过sigmoid进行二分类
- 最后是通过最大似然模型,梯度提升求解方法进行该路径概率的最大值求解(p(step1)*p(step2)…都是二分类模型)
- 通过反向传播求梯度后,通过梯度提升,更改权重向量(节点与节点连线);同时改变input layer词向量(因为$X_w$只是加权求平均)
- 优点:
- 舍去了隐藏层,在CBOW模型从输入层到隐藏层的计算改为直接从输入层将几个词的词向量求和平均作为输出
- 词向量的线性相关性
- 第一个改进在于去除了隐藏层,Word2vec训练词向量的网络结构严格上来说不算是神经网络的结构,也就去掉了非线性的激活函数,所以就能够表示词向量直接是线性相关的
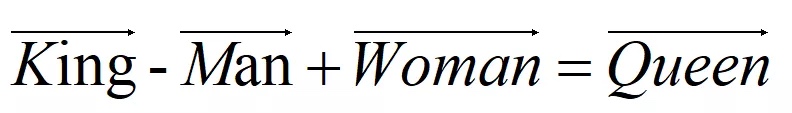
- 词向量的线性相关性
- 舍去了隐藏层到输出层的全连接结构,换成了霍夫曼树来代替隐藏层到输出层的映射
- 不需要计算所有的非叶子结点,只需要计算找寻某个叶子结点时经过的路径上存在的节点,极大的减少了计算量
- 舍去了隐藏层,在CBOW模型从输入层到隐藏层的计算改为直接从输入层将几个词的词向量求和平均作为输出
- 缺点:
比如霍夫曼树的结构是基于贪心的思想,这样训练频率很大的词很有效,但是对词频很低的词很不友好,路径很深(二分类比较多,训练的权重也就比较多)
word2vec-Negative Sampling
- 网络结构
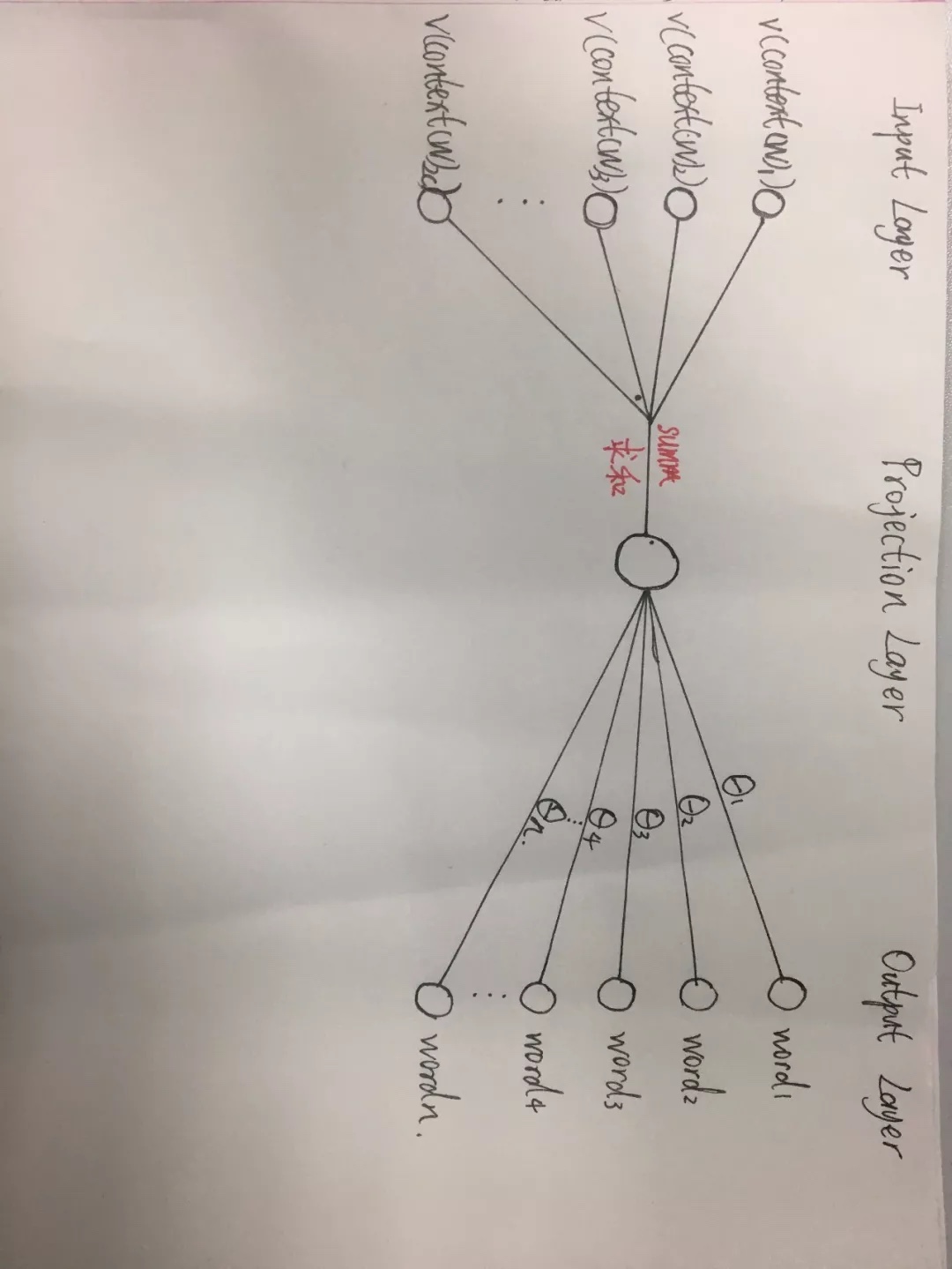
- 训练网络图
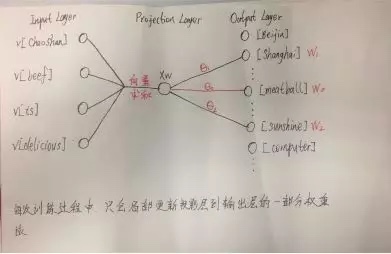
- 训练过程:
- 输入:(V,w0)(V,w1)(V,w2)…
- w0是想预测出来的那个正样本,w1,w2…是跟随随机选取的负样本
- V是上下文,比如cbow方式就是前后单词的向量求和sum
- 输出也是用的二分类的方法对正负样本进行概率判断
- 也是采用的最大似然的方法,对各个正负样本进行概率相乘,使其概率值达最大
- 通过梯度提升的方法,更新每个样本对应的$\theta$向量,以及输入的词向量
- 输入:(V,w0)(V,w1)(V,w2)…
- Negative Sampling选取负例词原理
基本就是对词出现的频率进行划分,目的是概率性取到不同频率的负样本 - 优点:
Negative Sampling训练生僻词的词向量会更稳定更快些
word2vec整体优缺点
- Word2vec训练出来的词向量效果挺好,其训练出来的词向量可以衡量不同词之间的相近程度
- word2vec也存在缺点,因为在使用context(w)中并没有考虑w上下文的词序问题,这就造成了训练时输入层所有的词都是等价的,这样训练出来的词向量归根结底只包含大量语义,语法信息
- 所以一般想拥有比较好的词向量,还是应该在一个有目标导向的神经网络中训练,比如目标是情感分析,在这样的神经网络中去取得第一层embedding层作为词向量,其表达的的效果应该会比word2vec训练出来的效果好得多,当然一般我们可能不需要精准表达的词向量,所以用word2vec来训练出词向量,也是一种可选择的快速效率的方法
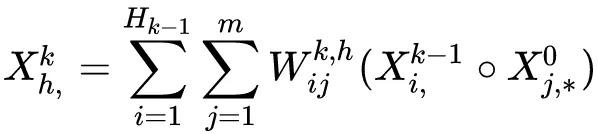
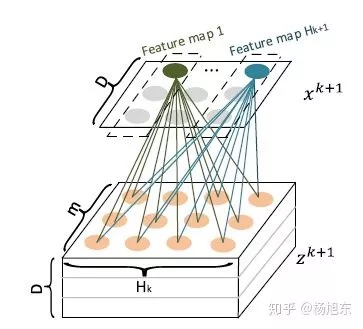
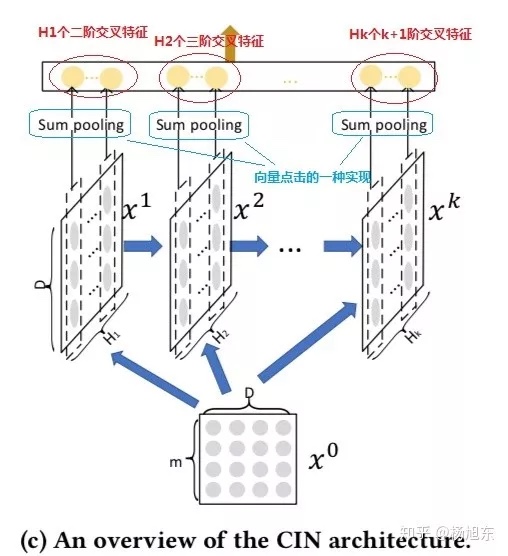
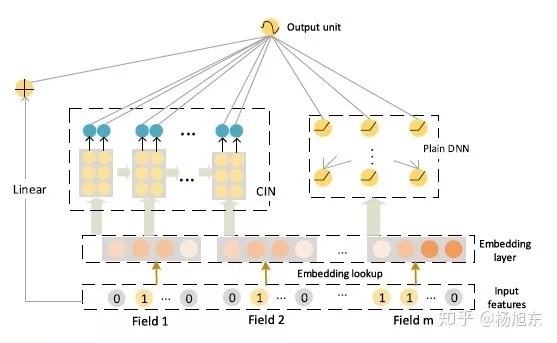
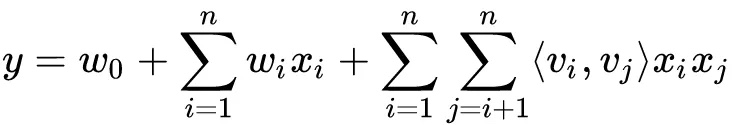
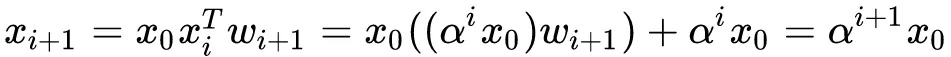 因此Cross Network的输出就相当于不断乘以一个数,当然这个数是和$x_0$高度相关的
因此Cross Network的输出就相当于不断乘以一个数,当然这个数是和$x_0$高度相关的